Google AI Introduces MaMMUT: A Simple Architecture for Joint Learning for MultiModal Tasks
The idea on which vision-language fundamental models are constructed is that a single pre-training can be used to adapt to a wide variety of downstream activities. There are two widely used but distinct training scenarios:
- Contrastive learning in the style of CLIP. It trains the model to predict if image-text pairs correctly match, effectively building visual and text representations for the corresponding image and text inputs. It enables image-text and text-image retrieval tasks like selecting the image that best matches a specific description.
- Next-token prediction: It learns to generate text by predicting the most probable next token in a sequence. It supports text-generative tasks like Image Captioning and Visual Question Answering (VQA) while contrastive learning.
While both methods have shown promising results, pre-trained models not transferable to other tasks tend to perform poorly on text-generation tasks and vice versa. It’s also common for complex or inefficient approaches to be used while adapting to new tasks.
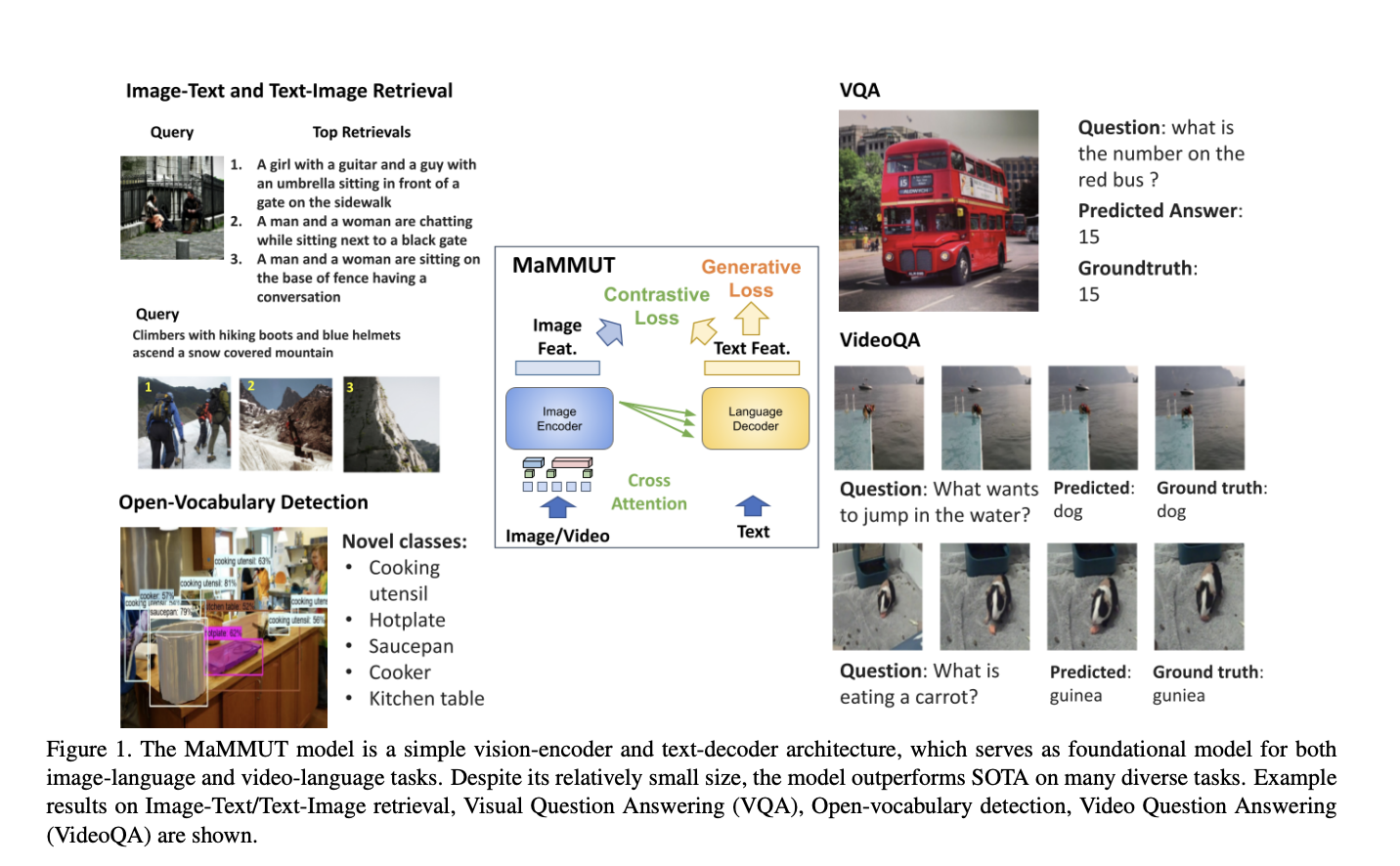
To train jointly for these competing aims and to provide the groundwork for numerous vision-language tasks either directly or by easy adaptation, a recent Google study presents MaMMUT, a simple architecture for joint learning for multimodal tasks. MaMMUT is a condensed multimodal model with only 2B parameters, and it may be trained to achieve contrastive, text-generating, and localization-aware goals. Its simple design—just one image encoder and one text decoder—makes it easy to recycle the two independently.
The proposed model comprises a single visual encoder and a single text-decoder linked via cross-attention and trains concurrently on contrastive and text-generative types of losses. Previous work either doesn’t address image-text retrieval tasks or just applies some losses to select aspects of the model. Jointly training contrastive losses and text-generative captioning-like losses is necessary to enable multimodal tasks and fully use the decoder-only model.
There is a considerable performance gain with a smaller model size (nearly half the parameters) for decoder-only models in language learning. One of the biggest obstacles to using them in multimodal situations is reconciling contrastive learning (which relies on unconditional sequence-level representation) and captioning (which optimizes the likelihood of a token based on the tokens that came before it). The researchers offer a two-pass technique to learn these incompatible text representations within the decoder jointly.
Their initial run at learning the caption generation challenge uses cross-attention and causal masking so that the text features can pay attention to the image features and make sequential token predictions. They turn off cross-attention and causal masking to learn the contrastive task on the second pass. While the picture features will remain hidden from the text features, the text features will be able to attend in both directions on all text tokens simultaneously. Both tasks, which were previously difficult to reconcile, may now be handled by the same decoder thanks to the two-pass technique. Even though this model architecture is quite simple, it can serve as a basis for various multimodal tasks.
Since the architecture is trained for several separate tasks, it may be easily integrated into many applications, including image-text and text-image retrieval, visual quality assessment, and captioning. The researchers use sparse video tubes to directly access spatiotemporal information from video for lightweight adaptation. Training to detect bounding boxes via an object-detection head is also required to transfer the model to Open-Vocabulary Detection.
Despite its compact design, MaMMUT provides superior or competitive results in various areas, including image-text and text-image retrieval, video question answering (VideoQA), video captioning, open-vocabulary identification, and VQA. The team highlights that their model achieves better results than much larger models like Flamingo, which is tailored to image+video pre-training and already pre-trained on image-text and video-text data.
Check out the Paper and Google blog. Don’t forget to join our 21k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.