Google AI Introduces MediaPipe Diffusion Plugins That Enable Controllable Text-To-Image Generation On-Device
Diffusion models have been widely used with remarkable success in text-to-image generation in recent years, leading to significant improvements in image quality, inference performance, and the scope of our creative possibilities. However, effective generation management remains a challenge, especially under conditions that are hard to define in words.
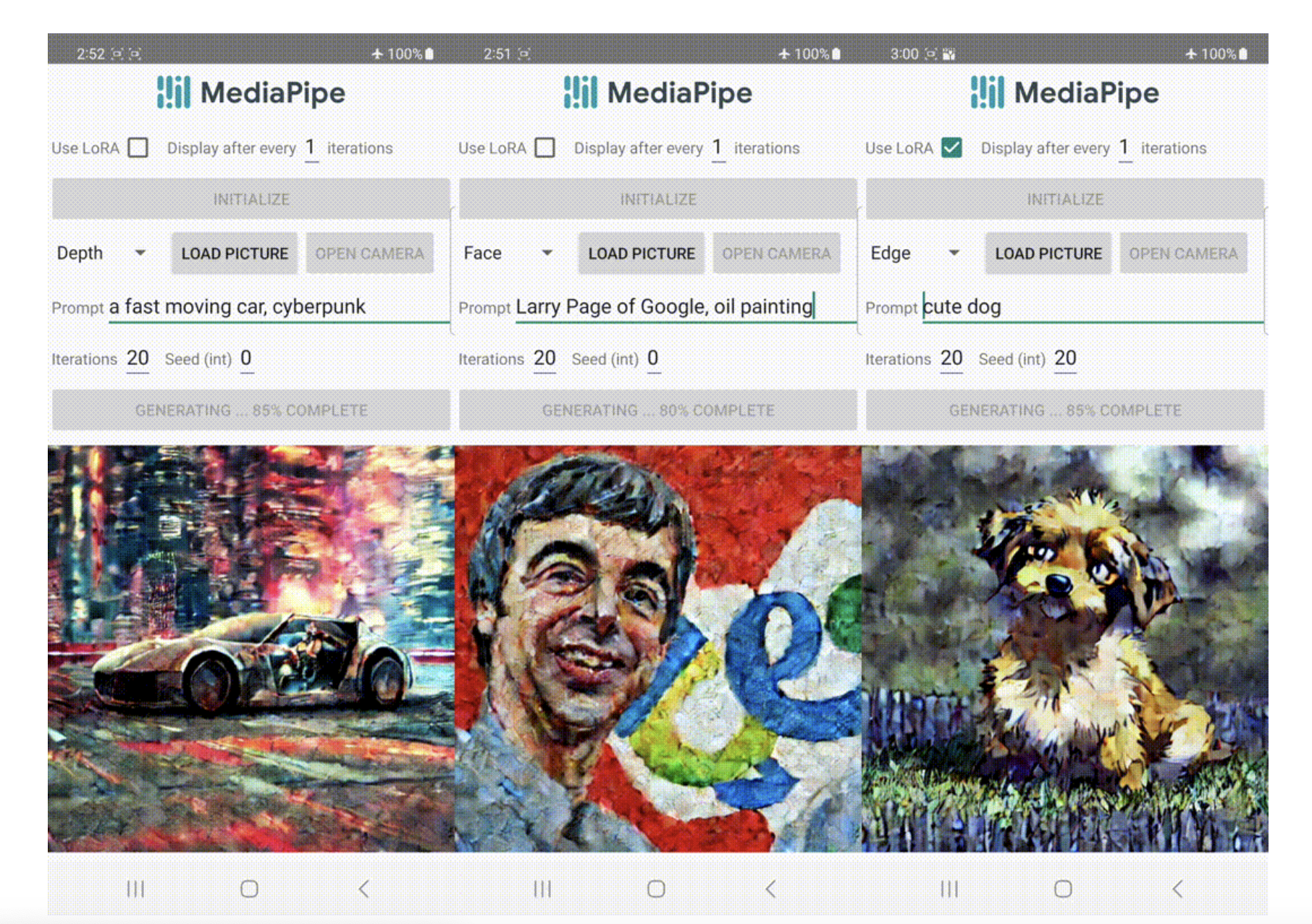
MediaPipe dispersion plugins, developed by Google researchers, make it possible to execute on-device text-to-image generation under user control. In this study, we extend our previous work on GPU inference for large generative models on the device itself, and we present low-cost solutions for programmable text-to-image creation that can be integrated into preexisting diffusion models and their Low-Rank Adaptation (LoRA) variations.
Iterative denoising is modeled for image production in diffusion models. Each iteration of the diffusion model begins with an image contaminated by noise and ends with an image of the target notion. Language understanding through text prompts has significantly enhanced the image-generating process. The text embedding is linked to the model for text-to-image production through cross-attention layers. However, the position and pose of an object are two examples of details that could be more challenging to convey using text prompts. Researchers introduce control information from a condition image into diffusion utilizing extra models.
The Plug-and-Play, ControlNet, and T2I Adapter methods are frequently used to generate controlled text-to-image output. To encode the state from an input image, Plug-and-Play employs a copy of the diffusion model (860M parameters for Stable Diffusion 1.5) and a widely-used denoising diffusion implicit model (DDIM) inversion approach that inverts the generation process from an input image to derive an initial noise input. The spatial features with self-attention are extracted from the copied diffusion and injected into the text-to-image diffusion using Plug-and-Play. ControlNet constructs a trainable duplicate of the encoder of a diffusion model and connects it via a convolution layer with zero-initialized parameters to encode conditioning information that is then passed on to the decoder layers. Unfortunately, this has led to a significant increase in size—about 450M parameters for Stable Diffusion 1.5—half as much as the diffusion model itself. T2I Adapter delivers comparable results in controlled generation despite being a smaller network (77M parameters). The condition picture is the only input to T2I Adapter, and the result is used by all subsequent diffusion cycles. However, this style of adapter is not made for mobile gadgets.
The MediaPipe diffusion plugin is a standalone network we developed to make conditioned generation effective, flexible, and scalable.
- Connects simply to a trained baseline model; pluggable.
- Zero-based training means no weights from the original model were used.
- It is portable because it can be run independently of the base model on mobile devices at almost no additional expense.
- The plugin is its network, the results of which can be integrated into an existing model for converting text to images. The diffusion model’s (blue) corresponding downsampling layer receives the retrieved features from the plugin.
A portable on-device paradigm for text-to-image creation, the MediaPipe dispersion plugin is available as a free download. It takes a conditioned image and uses multiscale feature extraction to add features at the appropriate scales to the encoder of a diffusion model. When coupled with a text-to-image diffusion model, the plugin model adds a conditioning signal to the image production. We intend for the plugin network to have only 6M parameters, making it a relatively simple model. To achieve rapid inference on mobile devices, MobileNetv2 employs depth-wise convolutions and inverted bottlenecks.
Fundamental Characteristics
- Easy-to-understand abstractions for self-service machine learning. To modify, test, prototype, and release an application, use a low-code API or a no-code studio.
- Innovative machine learning (ML) approaches to common problems, developed using Google’s ML know-how.
- Complete optimization, including hardware acceleration, while remaining small and efficient enough to run smoothly on smartphones running on battery power.
Check Out the Project Page and Google Blog. Don’t forget to join our 25k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
Featured Tools:
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.