Google AI Introduces PaLI: A Jointly-Scaled Multilingual Language-Image Model in Over 100 Languages
Increasing the number of parameters in ML training datasets improves the outcomes. Studies have shown that scaling in advanced language and vision-language (VL) models have led to a wide range of capabilities and outstanding results across tasks and languages.
A group of Google researchers set out to investigate the scalability of language-image models and the interaction between language and vision models on a large scale. Their paper, “PaLI: A Jointly-Scaled Multilingual Language-Image Model,” presents a unified language-image model trained to carry out a wide variety of tasks in more than a hundred different languages. Visual question answering, captioning, object detection, image categorization, optical character recognition, and text reasoning are just a few examples of the many tasks spanning vision, language, and multimodal image and language applications.
The researchers investigate the cross-modal scaling interactions in addition to the per-modality scaling. They scale up the visual part of our largest model to 4B parameters and the linguistic part to 13B during training.
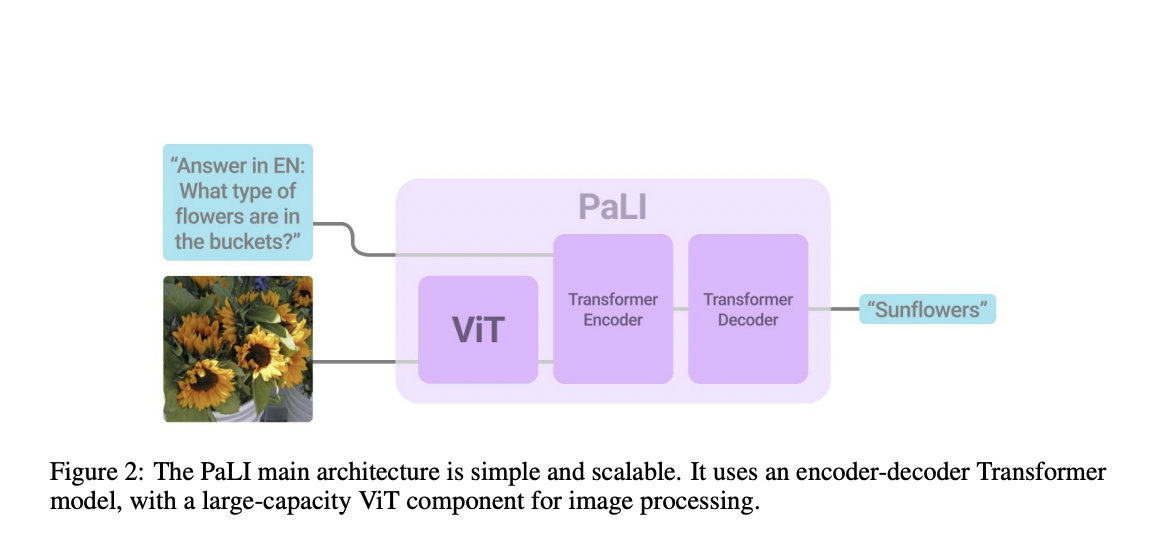
The architecture of the PaLI model is easy to understand, adapt, and use. A Transformer encoder processes an input text, and then the output text is generated by an auto-regressive Transformer decoder. The input to the Transformer encoder for image processing includes “visual words” representing the image to be transformed (ViT). Reuse is central to the PaLI model since we seed it with weights from other, previously-trained uni-modal vision and language models like mT5-XXL and huge ViTs. This allows for the transfer of abilities from uni-modal training and reduces the computational cost.

To fully realize the benefits of language-image pretraining, they built WebLI, a multilingual language-image dataset comprised of publicly available images and text.
According to them, it is possible to perform downstream actions in a wide variety of languages because of WebLI’s ability to translate text from datasets in English to 109 other languages. They expanded the WebLI dataset from 1 billion photos and 2 billion alt-texts to 10 billion by following a methodology similar to that used by other datasets, such as ALIGN and LiT.
Cloud Vision API was used to conduct OCR on the images, and together with web-text annotation, this produced 29 billion image-OCR pairs.
The researchers cast all tasks into a standardized API (input: picture + text; output: text), which is shared with the pretraining setup, allowing for knowledge-sharing between various image and language jobs. To train the model, they use the public domain T5X and Flaxformer frameworks written in JAX and Flax. Regarding the visual side of things, they introduce and train a big ViT architecture, called ViT-e, with 4B parameters utilizing the publicly available BigVision framework.
They use a battery of widely-used, comprehensive, and difficult vision-language benchmarks, including COCO-Captions, TextCaps, VQAv2, OK-VQA, and TextVQA, to evaluate PaLI. Compared to big models in the literature, the PaLI model obtains state-of-the-art results. For instance, it achieves better results than the much bigger Flamingo model (80B parameters) on various VQA and image-captioning tasks. It maintains performance even on difficult language-only and vision-only tasks that were not the primary focus of training.
Additionally, it has better results than competing models in both multilingual visual captioning and visual question answering. The researchers also investigate the interplay between the picture and language model components as they relate to model scalability and the areas in which the model excels. The findings show that optimal performance is achieved by scaling both components together and that scaling the visual component, which requires fewer parameters, is particularly important. Improving performance on various multilingual tasks also depends heavily on the ability to scale.
The team hopes that their work will lead to more investigations into multilingual and multimodal models.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'PaLI: A Jointly-Scaled Multilingual Language-Image Model'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and reference article. Please Don't Forget To Join Our ML Subreddit
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.