Google AI Introduces Pathdreamer: A World Model For Indoor Navigation

When navigating around an unknown facility, humans use various visual, spatial, and semantic cues to help them get to their destination quickly. However, taking advantage of semantic cues and statistical regularities in a new building is difficult for robotic agents. A common strategy would be to employ model-free reinforcement learning to learn implicitly what these cues are and how to apply them for navigation tasks. But Navigation cues learned this way are not only costly to learn but also difficult to evaluate and re-use in another agent without starting over.
A world model is an interesting alternative for robotic navigation and planning agents. The world model encapsulates rich and relevant information about their surroundings and allows an agent to make explicit predictions about actionable events within their environment. With spectacular results, these models have sparked broad interest in robotics, simulation, and reinforcement learning. However, real-world environments are very complex and diverse compared to game environments.
Google AI recently introduced a new world model called Pathdreamer that generates high-resolution 360o visual observations of sections of a building (unseen by an agent) using only a few seed observations and a suggested navigation trajectory. It can create an immersive scene from a single point of view, forecasting what an agent would see if it travelled to a different point of view or even to a previously unseen area, such as around a corner. This solution also can help autonomous agents navigate the actual world by codifying knowledge about human settings.
Pathdreamer Architecture
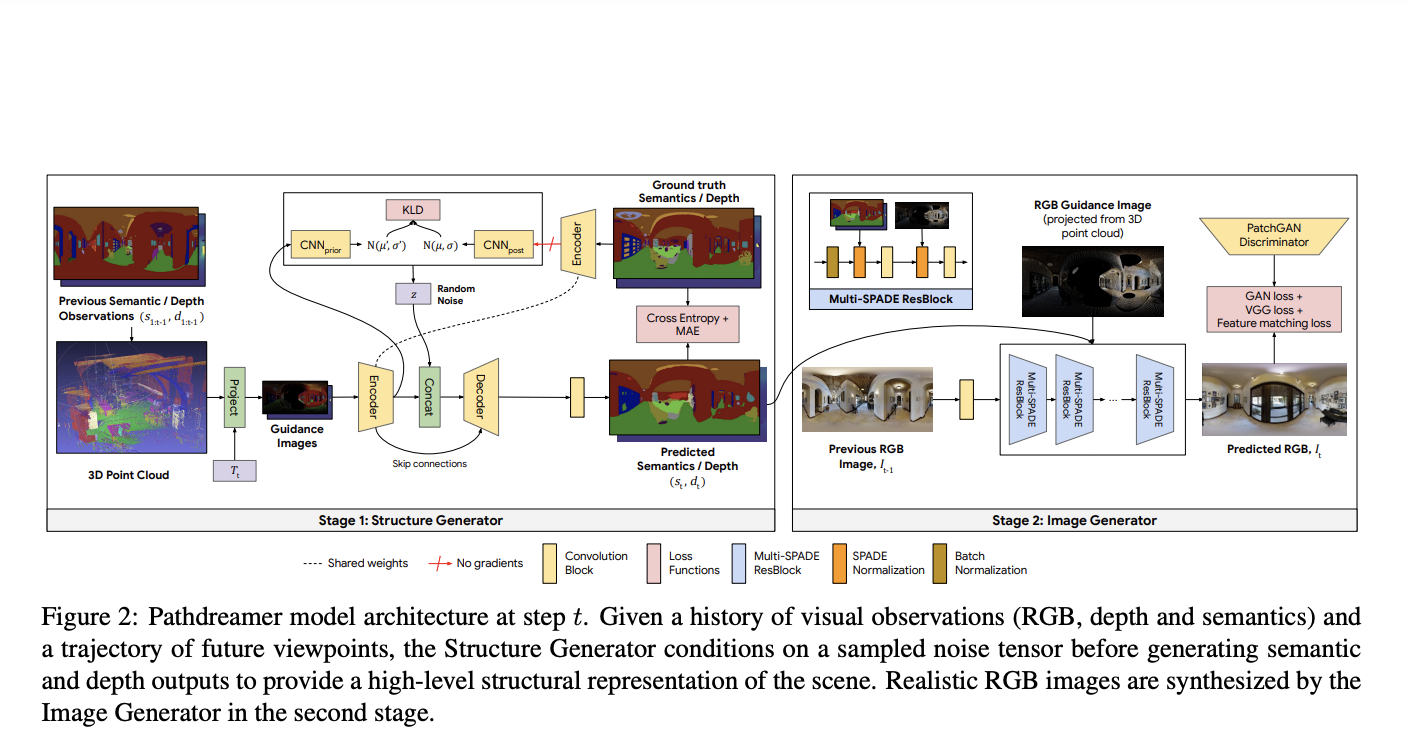
Pathdreamer takes a sequence of past observations as input and generates predictions for a trajectory of future places, which the agent interacting with the returned observations can offer upfront or iteratively. RGB, semantic segmentation and depth pictures are used in both the inputs and the predictions. Internally, Pathdreamer represents surfaces in the world with a 3D point cloud. The RGB colour value of each point in the cloud is labelled and the semantic segmentation class, such as wall, chair, or table.
When predicting visual observations in a new place, the point cloud is firstly re-projected into 2D in the new site to provide ‘guidance’ images. Pathdreamer then generates realistic high-resolution RGB, semantic segmentation, and depth using these images. New observations (actual or anticipated) are amassed in the point cloud as the model ‘moves.’ The use of a point cloud for memory has the advantage of temporal consistency: revisiting regions are represented in the same way as prior observations.

Pathdreamer works in two stages to convert guidance images into convincing and realistic results:
- In the first stage, the structure generator creates segmentation and depth pictures
- In the second stage, the image generator transforms them into RGB outputs.


The first stage conceptualizes a possible high-level semantic representation of the scene, which is then rendered into a realistic colour image in the second stage. Convolutional neural networks are used in both stages.
Many different scenes are possible in areas of high ambiguity, such as a location believed to be around a corner or in an unknown chamber. The structure generator is based on a noise variable, representing the stochastic information about the next location that is not recorded in the guide images, including principles from stochastic video production. Pathdreamer can synthesis varied landscapes by sampling multiple noise variables, allowing an agent to sample various conceivable outcomes for a given route. These various outputs are reflected in both the first stage output and in the generated RGB images.
Pathdreamer is capable of synthesizing realistic visuals as well as continuous video sequences after being trained with photographs and 3D environment reconstructions from Matterport3D. Because the output imagery is high-resolution and 360o, existing navigation agents may easily adapt it for use with any camera field of view.

Pathdreamer as a visual world model for improving task performance
The researchers employed Pathdreamer to Vision-and-Language Navigation (VLN) task. In VLN, an embodied agent is supposed to travel to a place in a realistic 3D world using natural language instructions. They used the Room-to-Room (R2R) dataset in which an instruction-following agent prepares ahead by simulating a variety of alternative passable paths through the environment, ranking each against the navigation instructions, and executing the best-ranked path. They analyzed the following three different scenarios:
- Ground-Truth setting in which the agent plans by engaging with the actual surrounding, i.e. through moving.
- Baseline setting in which the agent plans ahead without moving. Instead, it interacts with a navigation graph that encodes the building’s navigable pathways but does not provide any visual observations.
- Pathdreamer setting in which the agent plans ahead without moving by interacting with the navigation graph and receiving appropriate visual observations created by Pathdreamer.
The team observed that in the Pathdreamer setting when the agent plans ahead for three steps (approximately 6m), it achieves a navigation success rate of 50.4%. This score is remarkably higher than the 40.6% success rate in the Baseline setting without Pathdreamer. This demonstrates that Pathdreamer encodes meaningful and accessible visual, spatial and semantic knowledge about real-world indoor environments. The agent’s success rate is 59% in the Ground-Truth setting. However, they point out that in this situation, the agent must devote a significant amount of time and resources to physically exploring a large number of trajectories, which would be prohibitively expensive in a real-world setting.

In future, the team plans to apply Pathdreamer to other embodied navigation tasks, such as Object-Nav, continuous VLN, and street-level navigation.
Paper: https://arxiv.org/pdf/2105.08756.pdf
GitHub: https://github.com/google-research/pathdreamer
Source: https://ai.googleblog.com/2021/09/pathdreamer-world-model-for-indoor.html
Suggested
Credit: Source link
Comments are closed.