Google AI Introduces Reincarnating Reinforcement Learning RL That Reuses Prior Computation to Accelerate Progress
Reinforcement Learning RL, which falls under the Machine Learning umbrella, focuses on training intelligent agents to make decisions by using related experiences. This could include flying a stratospheric balloon, designing a hardware chip, or playing a video game. RL is very generalized, and one common trend in RL research is designing agents that can learn from an idea without any prior knowledge about the problem.
tabula rasa RL systems are an exception for solving large-scale RL problems rather than a norm. Large-scale RL systems such as OpenAI Five have achieved human-level performance on Dota2 after undergoing multiple algorithmic/architectural changes during the development cycle. The modification process is a necessity and usually lasts for months, and necessitating such changes from scratch without retraining is an expensive process.
tabula rasa RL is inefficient in terms of its computational ability as it cannot tackle computationally demanding problems. The computational barrier to enter in RL research will become even more higher as we go into deep RL and move towards more challenging and complex issues to address these inefficiencies of tabula rasa RL we are here studying “Reincarnating Reinforcement Learning: Reusing Prior Computation To Accelerate Progress.”
An alternative approach to RL research is to induce prior computational work such as learned models, policies, logged data, etc., which can be reused or transferred between the design iterations of one RL agent to another in contrast to many other RL agents which have to be developed from scratch. But there needs to be more effort to leverage the computational work in RL research, which is where Reincarnating RL kicks in.
Reincarnating RL (RRL) is more efficient and computationally friendly as compared to training from scratch. RRL democratizes research to solve complex RL problems without excessive computational resources. RRL can provide a benchmarking paradigm that allows researchers to continually improve existing training agents on issues that impact the real world, such as chip design and balloon navigation. Whereas in real-world RL use cases are likely to be used in scenarios where prior computational work is available. RRL has never been studied as a research problem on its own, and we argue for developing a general purpose RRL approach as opposed to prior as-hoc solutions.
Depending on the kind of prior computational work, various RRL problems can be discovered. A case study has been presented on setting of Policy to Value reincarnating RL (PVRL) to efficiently transfer an existing sub-optimal policy to a standalone value based RL agent. An approach directly maps a given environment state to an action, value-based agents estimate the effectiveness in terms of future rewards allowing them to learn from previously collected data.
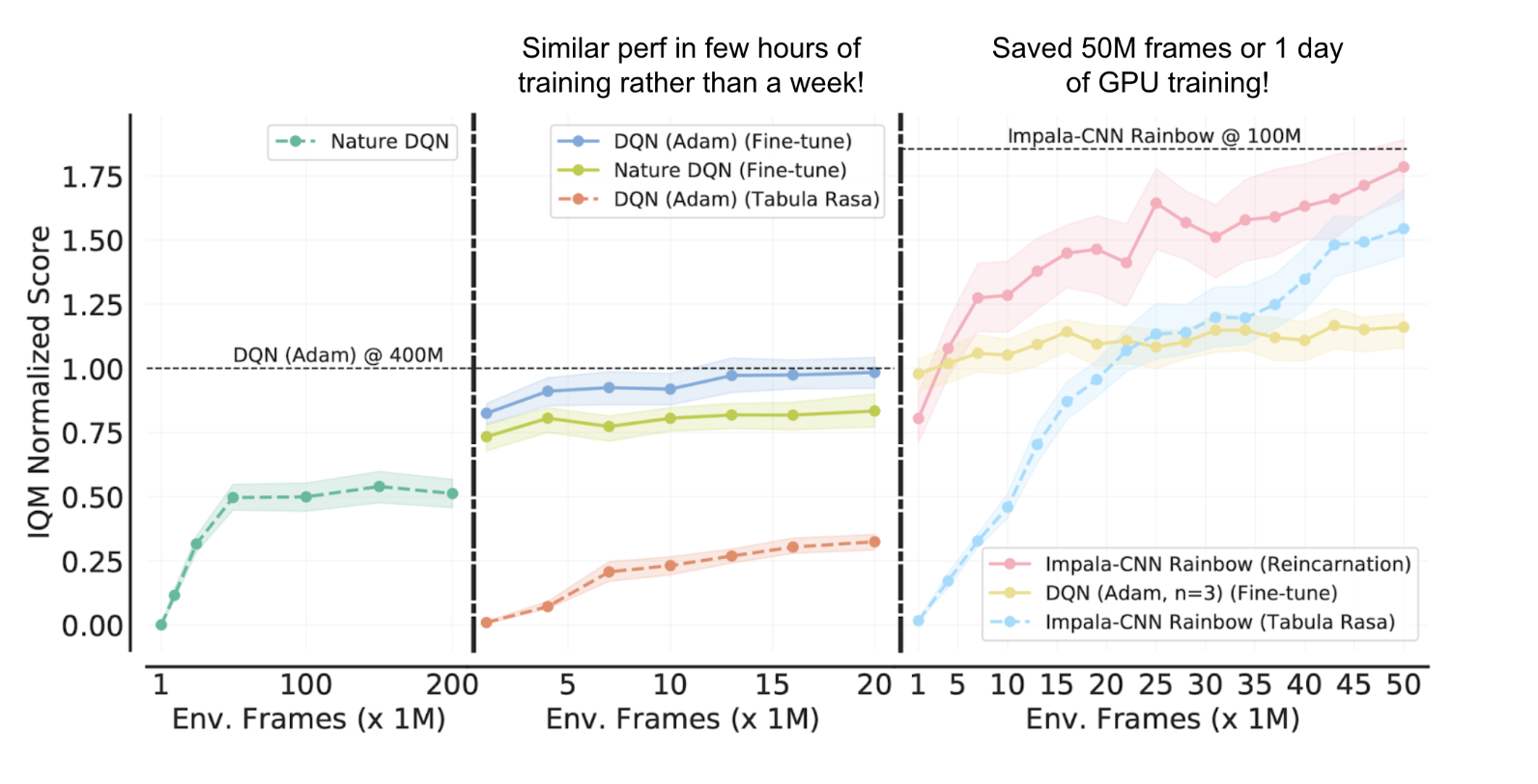
For a PVRL algorithm to be useful, it should be Teacher Agnostic, Weaning off the teacher, and Compute / Sample Efficient. Considering the PVRL algorithm requirements, we evaluate if the approach designed to reach the goal will suffice. These approaches result in minor improvements over tabular rasa or degrade the performance when weaning off the teacher. To overcome these limitations, a technique called QDagger is introduced in which the agent distills knowledge from the suboptimal teacher using an imitation algorithm simultaneously using its environment interactions. We begin with a deep Q-network (DQN) agent that has been trained for 400M environment frames and utilizes it as the teacher for reincarnating student agents that have only been trained on 10M frames, with the teacher being tapered off over the first 6M frames. For evaluation, interquartile mean (IQM) from the RLiable library is used, and for Atari games QDagger RRL method outperforms.
RRL approach is further examined on Arcade Learning Environment, an essential deep RL benchmark. A nature DQN agent is first taken using the RMSProp optimizer and fine-tuned with Adam optimizer creating a DQN (Adam) agent. We also show that a DQN (Adam) agent can be trained from scratch, we show that using 40 times less data and computation, fine-tuning Nature DQN with the Adam optimizer can match the performance. Fine-tuning is limited to the 3-layer convolutional architecture when using the DQN (Adam) agent as a starting point. So instead of starting from scratch with training, we propose a more general reincarnation method that uses recent architectural and algorithmic advancements.
These findings suggest that previous research may have been improved by using an RRL strategy to design agents rather than retraining agents from scratch.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'Reincarnating Reinforcement Learning: Reusing Prior Computation to Accelerate Progress'. All Credit For This Research Goes To Researchers on This Project. Check out the paper, code, project and reference article.
Please Don't Forget To Join Our ML Subreddit
![]()
Avanthy Yeluri is a Dual Degree student at IIT Kharagpur. She has a strong interest in Data Science because of its numerous applications across a variety of industries, as well as its cutting-edge technological advancements and how they are employed in daily life.
Credit: Source link
Comments are closed.