Google AI Introduces ScreenAI: A Vision-Language Model for User interfaces (UI) and Infographics Understanding
The capacity of infographics to strategically arrange and use visual signals to clarify complicated concepts has made them essential for efficient communication. Infographics include various visual elements such as charts, diagrams, illustrations, maps, tables, and document layouts. This has been a long-standing technique that makes the material easier to understand. User interfaces (UIs) on desktop and mobile platforms share design concepts and visual languages with infographics in the modern digital world.
Though there is a lot of overlap between UIs and infographics, creating a cohesive model is made more difficult by the complexity of each. It is difficult to develop a single model that can efficiently analyze and interpret the visual information encoded in pixels because of the intricacy required in understanding, reasoning, and engaging with the various aspects of infographics and user interfaces.
To address this, in a recent Google Research, a team of researchers proposed ScreenAI as a solution. ScreenAI is a Vision-Language Model (VLM) that has the ability to comprehend both UIs and infographics fully. Tasks like graphical question-answering (QA), which may contain charts, pictures, maps, and more, have been included in its scope.
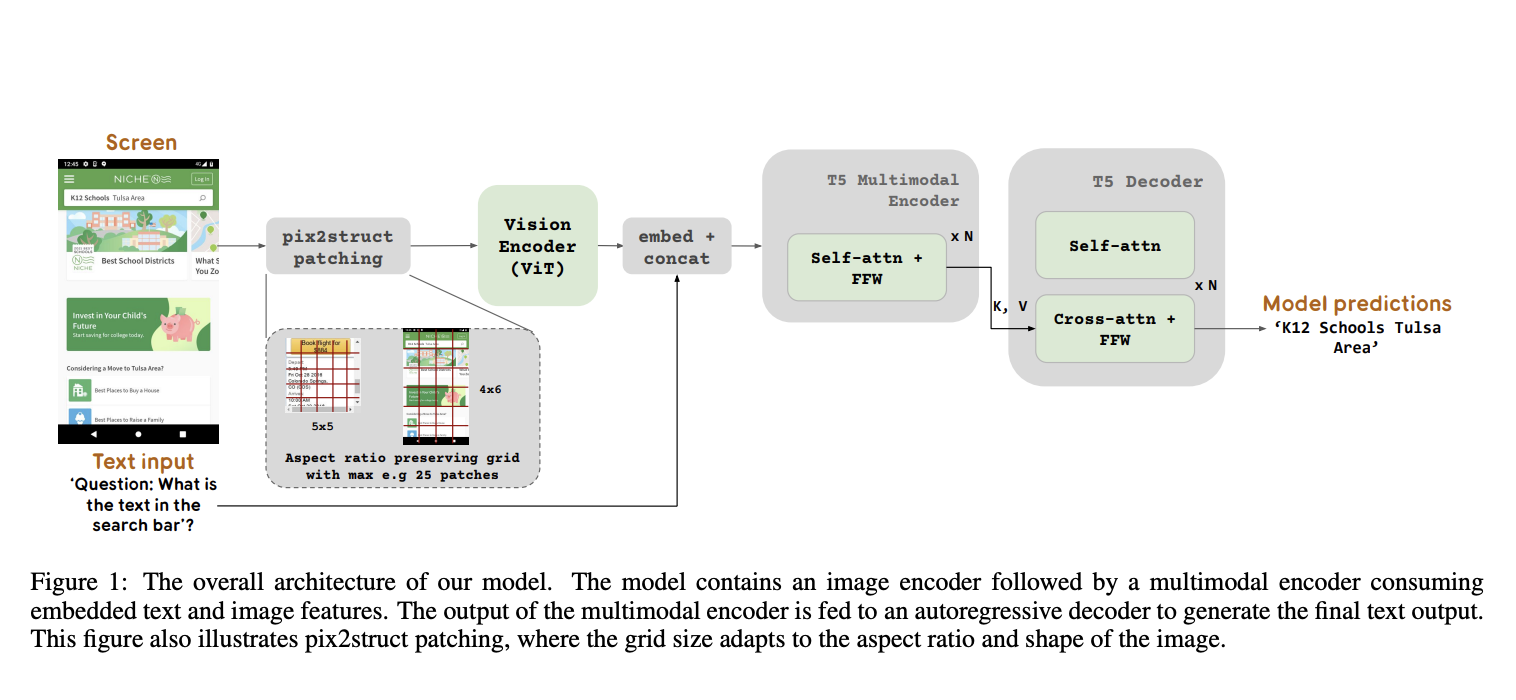
The team has shared that ScreenAI can manage jobs like element annotation, summarization, navigation, and additional UI-specific QA. To accomplish this, the model combines the flexible patching method taken from Pix2struct with the PaLI architecture, which allows it to tackle vision-related tasks by converting them into text or image-to-text problems.
Several tests have been carried out to demonstrate how these design decisions affect the model’s functionality. Upon evaluation, ScreenAI produced new state-of-the-art results on tasks like Multipage DocVQA, WebSRC, MoTIF, and Widget Captioning with under 5 billion parameters. It achieved remarkable performance on tasks including DocVQA, InfographicVQA, and Chart QA, outperforming models of comparable size.
The team has made available three additional datasets: Screen Annotation, ScreenQA Short, and Complex ScreenQA. One of these datasets specifically focuses on the screen annotation task for future research, while the other two datasets are focused on question-answering, thus further expanding the resources available to advance the field.
The team has summarized their primary contributions as follows:
- The Vision-Language Model (VLM) ScreenAI concept is a step towards a holistic solution that focuses on infographic and user interface comprehension. By utilizing the common visual language and sophisticated design of these components, ScreenAI offers a comprehensive method for understanding digital material.
- One significant advancement is the development of a textual representation for UIs. During the pretraining stage, this representation has been used to teach the model how to comprehend user interfaces, improving its capacity to comprehend and process visual data.
- To automatically create training data at scale, ScreenAI has used LLMs and the new UI representation, making training more effective and comprehensive.
- Three new datasets, Screen Annotation, ScreenQA Short, and Complex ScreenQA, have been released. These datasets allow for thorough model benchmarking for screen-based question answering and the suggested textual representation.
- ScreenAI has outperformed larger models by a factor of ten or more on four public infographics QA benchmarks, even with its low number of 4.6 billion parameters.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 37k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.