Google AI Introduces SimVLM: Simple Visual Language Model Pre-training With Weak Supervision

The visual language modeling method has lately emerged as a feasible option for content-based image classification. In this method, each image is converted into a matrix of visual words, and each visual word is assumed to be conditionally reliant on its neighbors.
While such cross-modal work has its challenges, significant progress has been made in vision-language modeling in recent years, with effective vision-language pre-training (VLP). Rather than learning two independent feature spaces, one for visual inputs and one for language inputs, this approach seeks to learn a single feature space from visual and verbal inputs.
Existing VLP frequently uses an object detector trained on labeled object detection datasets to extract regions-of-interest (ROI) and task-specific techniques (i.e., task-specific loss functions) to learn picture and text representations simultaneously. However, such approaches are less scalable because they require annotated datasets and time to build task-specific methods.
To solve this issue, Google researchers suggest a simple and effective VLP called SimVLM, which stands for “Simple Visual Language Model Pre-training with Weak Supervision.” SimVLM is trained on a large number of poorly aligned image-text pairs end-to-end with a unifying purpose comparable to language modeling. SimVLM’s ease of use allows for efficient training on such a large dataset, allowing the model to achieve best-in-class performance across six vision-language benchmarks.
Model Pre-Training
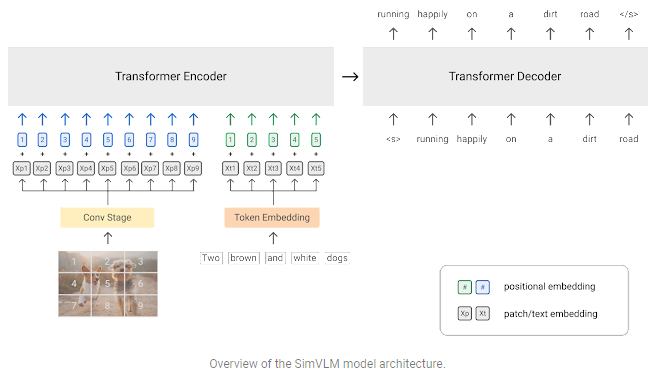
SimVLM uses a sequence-to-sequence framework and is trained with a one prefix language model (PrefixLM). PrefixLM receives the leading part of a sequence (the prefix) as inputs and predicts its continuation. In SimVLM, the prefix concatenates both the image patch sequence and the prefix text sequence received by the encoder for multimodal inputs (e.g., images and captions). The decoder then predicts how the textual sequence will continue.
Unlike previous VLP models that combined numerous pre-training losses, the PrefixLM loss is the only training target, simplifying the training process dramatically. SimVLM’s versatility and universality in supporting varied job settings are maximized with this method.
Finally, a transformer architecture has been used as the backbone of the model. Unlike previous ROI-based VLP techniques, it allows the model to take in raw images as inputs directly. Furthermore, the researchers have used a convolution stage consisting of the first three blocks of ResNet to extract contextualized patches.
For both image-text and text-only inputs, the model is pre-trained on large-scale web datasets. The team used the ALIGN training set, which contains around 1.8 billion noisy image-text pairs, for combining vision and language data. In addition, they used T5’s Colossal Clean Crawled Corpus (C4) dataset for text-only data, containing 800G web-crawled articles.
After pre-training, the model is fine-tuned on the multimodal tasks, including VQA, SNLI-VE, NLVR2, COCO Caption, NoCaps, and Multi30K En-De. SimVLM achieves state-of-the-art performance across all tasks despite being substantially simpler when compared to strong existing baselines such as LXMERT, VL-T5, UNITER, OSCAR, Villa, SOHO, UNIMO, VinVL.

Zero-Shot Generalization
As the researchers have trained SimVLM on a considerable quantity of data from both visual and textual modalities, they investigate whether it can accomplish the zero-shot cross-modality transfer on various tasks. This includes picture captioning, multilingual captioning, open-ended VQA, and visual text completion. They employed pre-trained SimVLM to decode multimodal inputs directly, with only text data fine-tuning or no fine-tuning at all. The results show that the model can produce high-quality image captions and descriptions, allowing for cross-lingual and cross-modality translation.

They decoded the pre-trained, frozen model on the COCO Caption and NoCaps benchmarks and then compared it with supervised baselines to quantify its performance. The findings demonstrate that SimVLM can achieve zero-shot captioning quality comparable to supervised algorithms even without supervised fine-tuning.

Paper: https://arxiv.org/pdf/2108.10904.pdf
Source: https://ai.googleblog.com/2021/10/simvlm-simple-visual-language-model-pre.html
Suggested
Credit: Source link
Comments are closed.