Google AI Introduces SoundStorm: An AI Model For Efficient And Non-Autoregressive Audio Generation
The job of audio production may be made accessible to the sophisticated Transformer-based sequence-to-sequence modeling techniques by modeling discrete representations of audio created by neural codecs. Speech continuation, text-to-speech, and general audio and music creation have all advanced quickly due to casting unconditional and conditional audio generation as sequence-to-sequence modeling. The pace of the discrete representation must be raised to produce high-quality audio by modeling the tokens of a neural codec, which leads to an exponential rise in codebook size or extended token sequences. Long token sequences also provide computational difficulties for autoregressive models, whose exponential development could be more practical owing to memory constraints.
The primary emphasis of this study done by researchers at Google is to develop SoundStorm; attention-based models, in particular, will have quadratic runtime complexity concerning the length of the sequence used to calculate self-attention. As a result, one of the main difficulties in audio creation is resolving the trade-off between perceived quality and runtime. At least three orthogonal approaches, or a combination of them, can be used to solve the problem of generating lengthy audio token sequences:
- Effective attention mechanisms
- Non-autoregressive, parallel decoding schemes
- Custom architectures tailored to the unique properties of the tokens produced by neural audio codecs
For future developments in long-sequence audio modeling, the unique structure of the audio token sequence has the most potential. However, the effective creation of lengthy, high-quality audio segments still needs to be improved when modeling the token sequence of neural audio codecs, either unconditionally or based on weak conditioning, such as text. Concretely, Residual Vector Quantization is the method used by SoundStream and EnCodec to quantize compressed audio frames. Each quantizer operates on the residual of the preceding one, and the number of quantizers determines the total bitrate.
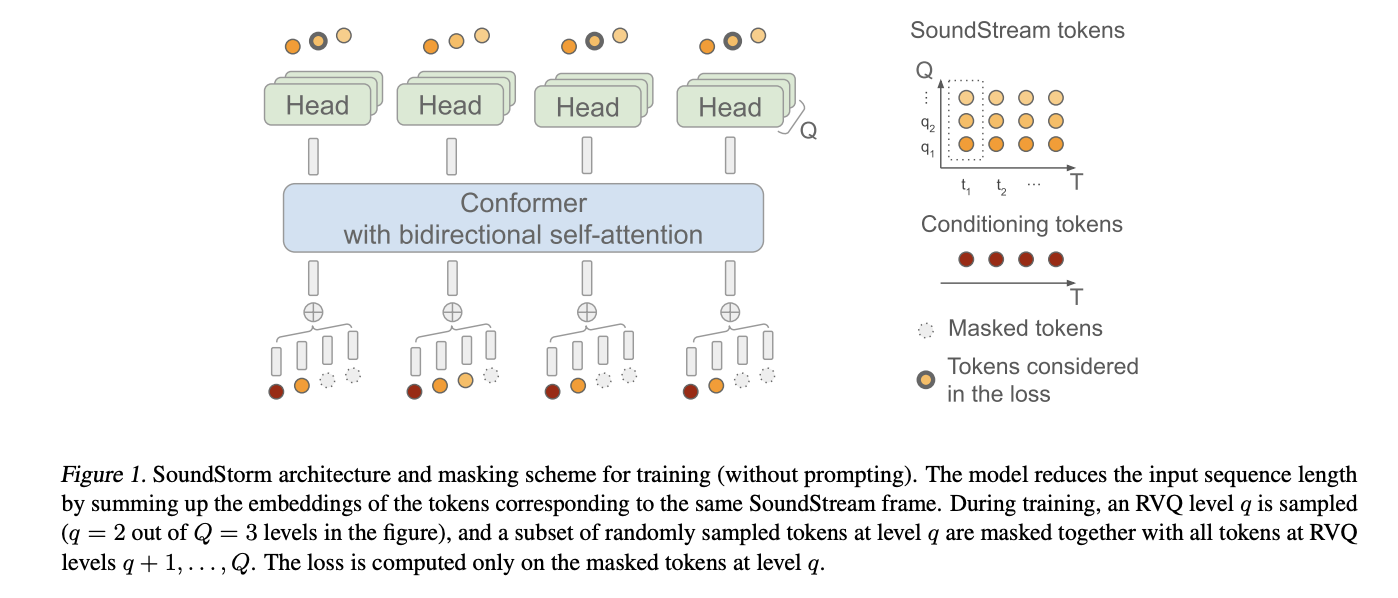
Tokens from smaller RVQ levels contribute less to the perceived quality. Therefore, the models and decoding strategies should consider this unique input structure for effective training and inference. They introduce SoundStorm, a quick and effective audio creation technique, in this work. SoundStorm uses an architecture tailored to the hierarchical structure of the audio tokens and a parallel, non-autoregressive, confidence-based decoding scheme for residual vector quantized token sequences to solve the issue of generating long audio token sequences. As a result, a hierarchical token structure is created, allowing for accurate factorizations and estimates of the joint distribution of the token sequence.
To forecast masked audio tokens created by SoundStream given a conditioning signal, such as the semantic tokens of AudioLM, SoundStorm uses a bidirectional attention-based Conformer. To ensure that the internal sequence length for the self-attention is equal to the number of SoundStream frames and independent of the number of quantizers in the RVQ, it adds up the tokens’ embeddings corresponding to a single SoundStream frame on the input side. Using the output embeddings, the masked target tokens are then predicted using separate heads operating at each RVQ level. SoundStorm begins with all audio tokens masking out at inference time. Given the conditioning signal, it fills in the masked tokens RVQ level-by-level across several iterations, predicting multiple tokens concurrently throughout an iteration within a level.
They provide a training masking approach replicating the inference process to support this inference scheme. They show that SoundStorm can take the place of both AudioLM’s stage two and stage three as its acoustic generator. Regarding speaker identification and acoustic circumstances, SoundStorm creates audio two orders of magnitude quicker than AudioLM’s hierarchical autoregressive acoustic generator while maintaining comparable quality. Additionally, they demonstrate how SoundStorm can create high-quality, lifelike conversations by combining it with the text-to-semantic modeling step of SPEAR-TTS. This allows one to manage spoken material, voice, and turn. They record a runtime of 2 seconds on a single TPU-v4 when synthesizing talks lasting 30 seconds.
Check out the Paper and Project. Don’t forget to join our 22k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.