Google AI Introduces Task Affinity Groupings (TAG): A Method That Determines Which Tasks Should Be Trained Together In Multi-Task Neural Networks

The majority of machine learning (ML) models are designed to learn one task at a time. However, there may be times when learning from a variety of related activities at the same time improves modeling performance. This is handled in the multi-task learning domain in which many objectives are simultaneously learned within the same model.
An obvious question to ask here is how do we decide on tasks to be trained together?
A multi-task learning model typically uses the knowledge it learns during training on one task to reduce the loss on other tasks included in the network’s training. When compared to the performance of training a new model for each task, this information transfer results in a single model that can make many predictions and may have improved accuracy for those predictions. On the other side, training a single model to do several tasks may result in model capacity competition, resulting in poor performance, which is common when tasks are unrelated.
An exhaustive search of all conceivable combinations of multi-task networks for a set of tasks is one straightforward way to identify the subset of tasks on which a model should train. However, because the number of possible combinations grows exponentially with the number of jobs in the set, the cost of this search can be prohibitive, especially when there are a large number of tasks. The collection of activities to which a model is applied may evolve over time which complicates it further.
This costly analysis would have to be performed anytime tasks were added to or removed from the set of all tasks to generate new groups. Furthermore, as models’ scale and complexity grow, even approximation task grouping techniques that analyze only a portion of feasible multi-task networks may become unacceptably expensive and time-consuming to evaluate.
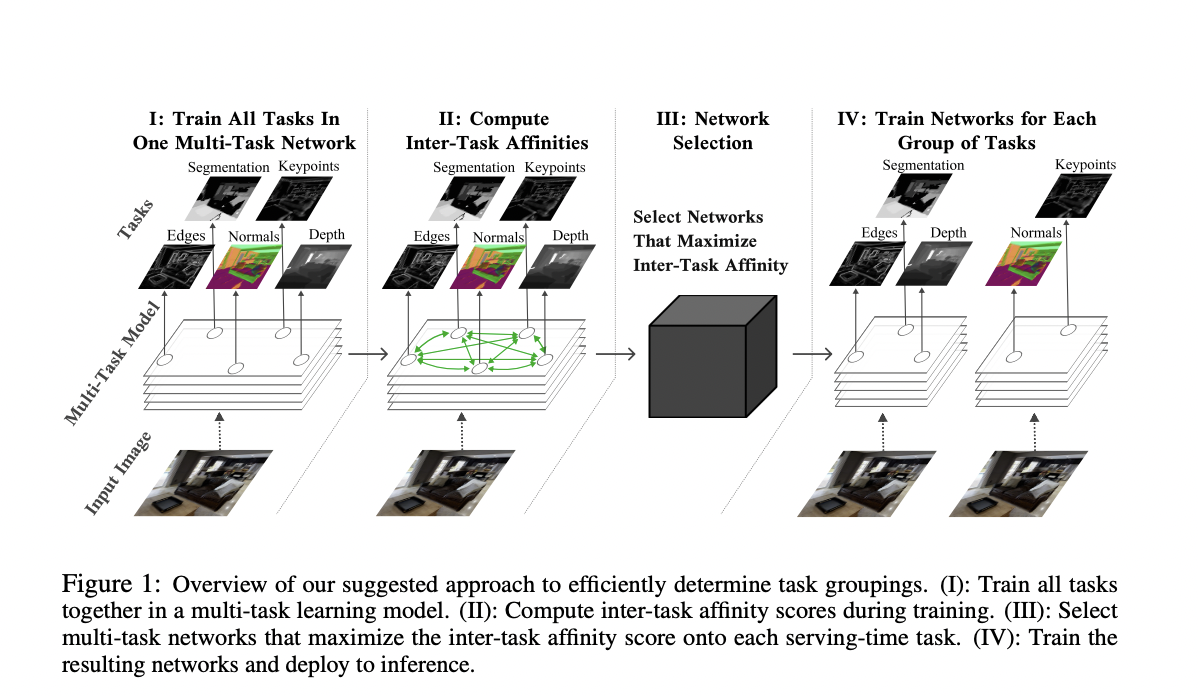
Task Affinity Groupings (TAG) is a novel strategy introduced by Google AI that decides which tasks in multi-task neural networks should be trained together. Their methods aim to break down a large number of jobs into smaller subsets so that overall performance is maximized.
To do this, it trains all tasks in a single multi-task model and evaluates the impact of one task’s gradient update on the model’s parameters on the loss of the other tasks in the network. This amount is referred to as inter-task affinity.

Source: https://ai.googleblog.com/2021/10/deciding-which-tasks-should-train.html
Task Affinity Groupings (TAG)
The researcher was inspired by meta-learning, a branch of machine learning in which a neural network adapts quickly to a new and previously unknown task. MAML, one of the most well-known meta-learning algorithms, performs a gradient update to the models’ parameters for a series of tasks. It then updates its initial set of parameters to minimize the loss for a subset of those tasks computed at the updated parameter values.
MAML uses this strategy to train the model to learn representations that will minimize the loss for the weights after one or more training steps rather than for the current set of weights. Because MAML optimizes for the future rather than the present, it trains a model’s parameters to adapt to a previously unknown task quickly.
TAG uses a similar approach to obtain insight into the training processes of multi-task neural networks. It does this by updating the model’s parameters with respect to only one task, analyzing how this change will affect the other tasks in the multi-task neural network, and then undoing the update. This approach is then repeated for each subsequent task to collect data on how each task in the network interacts with others. After that, training resumes as usual, with the model’s shared parameters updated for each task in the network.
The team collected these numbers and analyzed their dynamics over time. Their results suggest that specific tasks have consistently positive interactions, while others have hostile relationships. A network selection method can use this information to combine tasks to maximize inter-task affinity, depending on how many multi-task networks the practitioner can use during inference.
The findings show that TAG is capable of selecting quite strong task categories. According to researchers, TAG is competitive with the previous state-of-the-art methods on the CelebA and Taskonomy datasets while running 32x and 11.5x quicker, respectively. This speedup amounts to 2,008 fewer Tesla V100 GPU hours to detect task groupings on the Taskonomy dataset.
Overall, the results of the experiments show that grouping tasks to optimize inter-task affinity has a substantial correlation with overall model performance.
Paper: https://arxiv.org/abs/2109.04617
Github: https://github.com/google-research/google-research/tree/master/tag
Source: https://ai.googleblog.com/2021/10/deciding-which-tasks-should-train.html
Suggested
Credit: Source link
Comments are closed.