Google AI Introduces Translatotron 2 For Robust Direct Speech-To-Speech Translation

The Natural Language Processing (NLP) domain is experiencing remarkable growth in many areas, including search engines, machine translation, chatbots, home assistants and many more. One such application of S2ST (speech-to-speech translation) is breaking language barriers globally by allowing speakers of different languages to communicate. It is therefore extremely valuable to humanity in terms of science and cross-cultural exchange.
Automatic S2ST systems are typically made up of a series of subsystems for speech recognition, machine translation, and speech synthesis. However, such cascade systems may experience longer latency, information loss (particularly paralinguistic and non-linguistic information), and compounding errors between subsystems.
In 2019, Google AI introduced Translatotron, the first model that directly translates speech between two languages. This direct S2ST model could be trained end-to-end in a short amount of time and had the unique ability to keep the source speaker’s voice (which is non-linguistic information) in the translated speech. Despite its capacity to produce high-fidelity translated speech that sounds realistic, it nevertheless underperformed compared to a strong baseline cascade S2ST system.
Google’s recent study presents the improved version of Translatotron, which significantly enhances performance. Translatotron 2 employs a new way for transferring the voices of the source speakers to the translated speech. Even when the input speech involves numerous speakers speaking in turn, the updated technique to voice transference is successful while also decreasing the potential for misuse and better complying with our AI Principles.
Translatotron 2 Architecture
The main components of this new model are:
- A voice encoder.
- A target phoneme decoder.
- A target speech synthesizer.
- An attention module that connects them all.
The encoder, attention module, and decoder work together to be comparable to a traditional direct speech-to-text translation (ST) model.

The key changes made in Translatotron 2 are listed below:
- The output from the target phoneme decoder is one of the inputs to the spectrogram synthesizer in Translatotron 2. It is, therefore, easy to train and performs better as a result of its strong conditioning.
- The spectrogram synthesizer used in Translatotron 2 is duration-based, which remarkably improves the robustness of the synthesized speech.
- The attention-based connection in Translatotron 2 is driven by the phoneme decoder instead of the spectrogram synthesizer. This aligns the acoustic information the spectrogram synthesizer sees with the translated material it’s synthesizing, allowing each speaker’s voice to be preserved throughout speaker turns.
Strong Voice Retention
By conditioning its decoder on a speaker embedding generated by a separately trained speaker encoder, the original Translatotron preserved the source speaker’s voice in the translated speech. However, if a clip of the target speaker’s recording was provided as the reference audio to the speaker encoder, or if the target speaker’s embedding was directly available, this approach allowed it to generate the translated speech in a different speaker’s voice. This had the potential to be used to spoof audio with arbitrary content.
Keeping this in mind, Translatotron 2 is built with just one speech encoder that handles both language understanding and voice capture. This restricts trained models to reproduce non-source voices.
The researchers used a modified version of PnG NAT, a TTS model capable of cross-lingual voice transmission. The modified PnG NAT model adds a separately learned speaker encoder, allowing zero-shot voice transference.
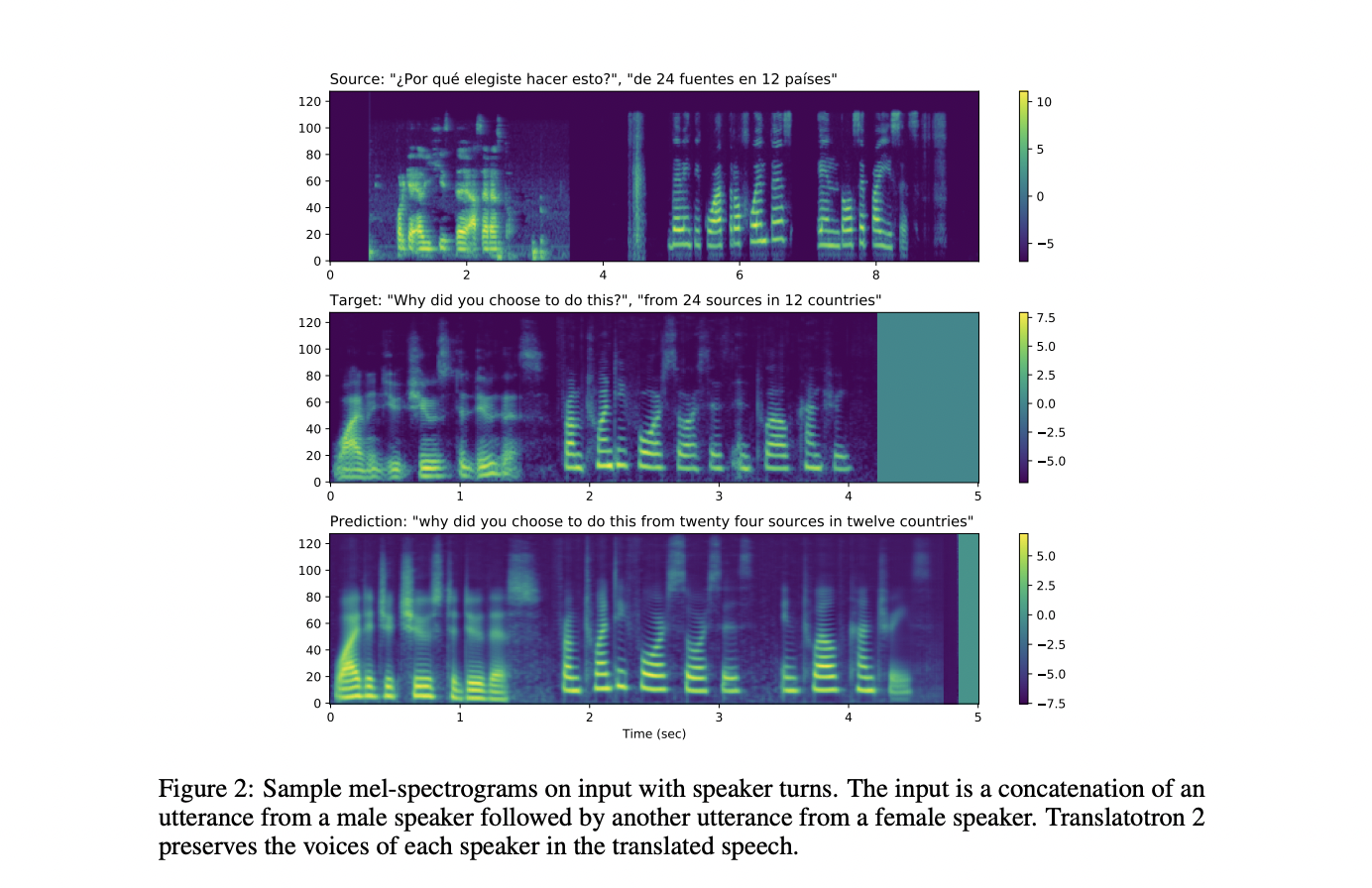
Furthermore, they propose ConcatAug, a simple concatenation-based data augmentation technique. This enables S2ST models to keep each speaker’s voice in the translated speech when the input speech contains many speakers speaking in turn. By randomly picking pairs of training examples and concatenating the source speech, target speech, and target phoneme sequences into new training examples, this method augments the training data on the fly. The model can learn from examples with speaker turns since the samples contain two speakers’ voices in both the source and destination speech.
Input (Spanish):
TTS-synthesized reference (English):
Translatotron 2 (without ConcatAug) prediction (English):
Translatotron 2 (with ConcatAug) prediction (English):
Translatotron 2 consistently outperforms the original Translatotron in terms of translation quality, speech naturalness, and speech resilience in tests on three different corpora. It excelled in the challenging Fisher corpus in particular.



The researchers also evaluated the model’s performance on a multilingual set-up, in which the model translated speech from four distinct languages into English. The language of the input voice is not provided; therefore, the model had to figure it out on its own. Translatotron 2 surpasses the original Translatotron by a wide margin on this task. The results suggest that Translatotron 2’s translation quality is comparable to a baseline speech-to-text translation model. These findings demonstrate that Translatotron 2 is very effective on multilingual S2ST.

Paper: https://arxiv.org/abs/2107.08661
Source: https://ai.googleblog.com/2021/09/high-quality-robust-and-responsible.html
Suggested
Credit: Source link
Comments are closed.