Google AI Introduces V-MoE: A New Architecture For Computer Vision Based On A Sparse Mixture Of Experts
Throughout the previous few decades, deep learning advances have contributed to outstanding outcomes on a wide range of tasks, including image classification, machine translation, and protein folding prediction. According to the researchers, deep learning models will be able to learn without the assistance of humans and will be adaptable to changes in their environment in the future. They should also solve a wide variety of reflexive and cognitive challenges.
The utilization of huge models and datasets, on the other hand, comes at the cost of enormous computational resources. According to recent research, large model sizes may be required for solid generalization and robustness. As a result, it’s become critical to train huge models while keeping resource needs low.
Implementing conditional computing, which works by activating different model elements for other inputs, is one way to address this issue. This is a considerably more promising strategy than activating the entire network for each information.
Researchers from Google AI present V-MoE, a new vision architecture based on a sparse mixture of experts. It can be used to train the world’s biggest vision model. V-MoE is transferred to ImageNet and displayed to showcase state-of-the-art accuracy. It has been observed that it performs marvels even with around 50% fewer resources than models of equivalent performance.
What is V-MoEs?
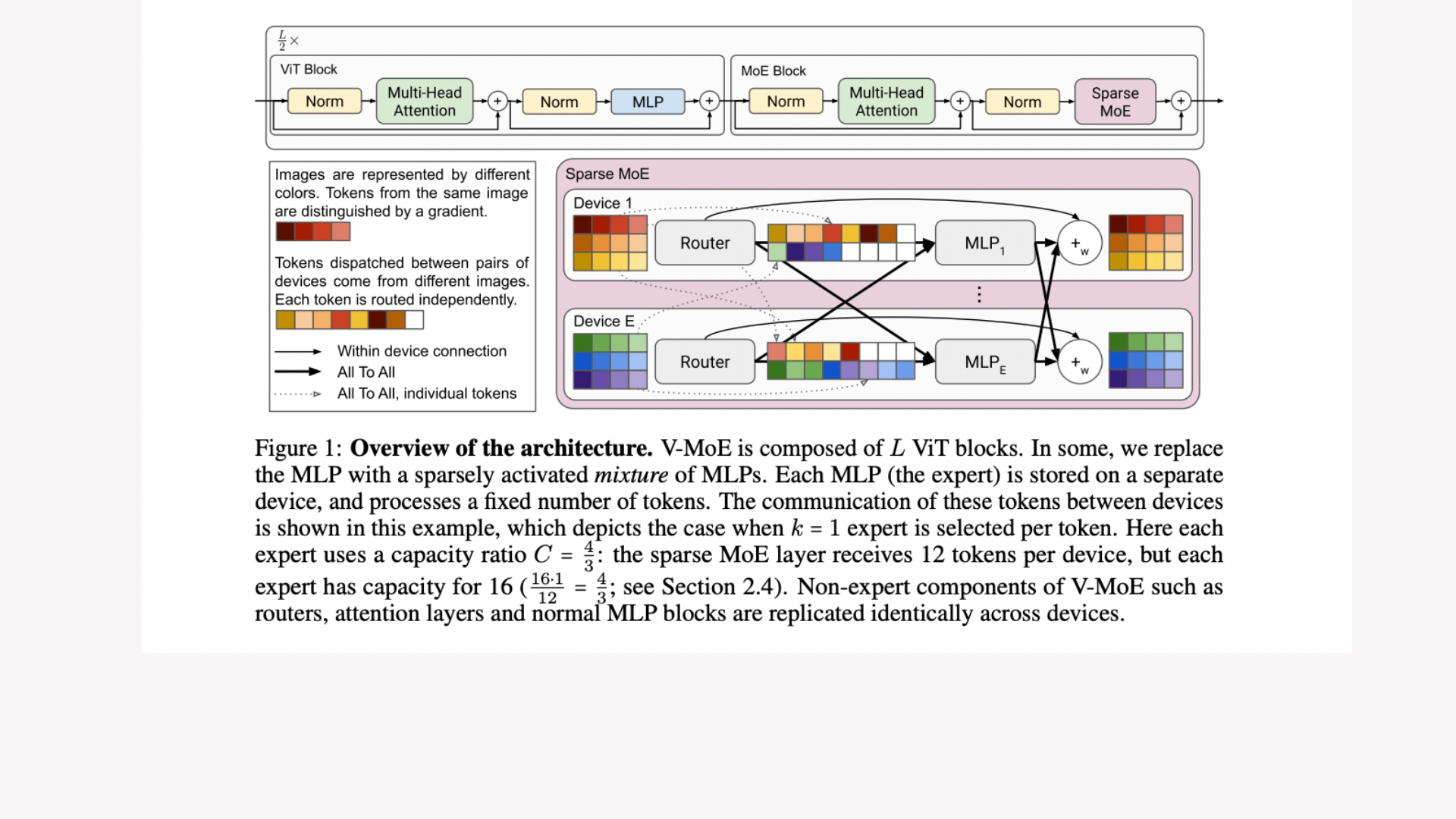
One of the better structures for vision jobs is Vision Transformers (ViT). First, ViT divides an image into tokens, which are square patches of equal size.
Some of the ViT architecture’s dense feedforward layers (FFN) are replaced with experts, a sparse combination of independent FFNs. For each token, a learnable router layer chooses which experts to use and how they should be weighted. Different tokens from the same image could be sent to various experts. Each token is only routed to a maximum of K experts out of a total of E. The values K and E are predetermined. This allows the model’s size to be scaled while maintaining a nearly constant calculation per token.

Experimental Findings:
The model is pre-trained on the JFT-300M dataset, which contains a significant number of photos. Using a new head, the model is then translated to new downstream tasks (such as ImageNet) (the last layer in a model).
Following that, two different transfer arrangements are investigated:
- Using all accessible samples of the new assignment to fine-tune the overall model.
- Using a few examples, freezing the pre-trained network and tweaking only the new head (known as few-shot transfer).
At a given amount of training computation, the sparse model outperforms its dense version or achieves similar performance considerably faster in both cases.
A 15-billion parameter model with 24 MoE layers is trained using an expanded version of JFT-300M to test the limitations of vision models. After fine-tuning, this large model obtained 90.35 percent test accuracy on ImageNet, which is close to the present state-of-the-art.
Limitations and Mitigation:
However, because dynamic buffers are inefficient due to hardware limits, models often employ a pre-defined buffer capacity for each expert. Once the expert is “full,” all assigned tokens over this capacity are dropped and not processed. As a result, more immense capabilities result in higher accuracy, but they also cost more to compute.
The researchers use this implementation limitation to make V-MoEs speedier at inference time. The network is compelled to skip some tokens in the expert levels by reducing the total combined buffer capacity below the number of tokens to be processed. Rather than arbitrarily deciding which tokens to skip, the model learns to arrange tokens according to their relevance score. This ensures high-quality forecasts while reducing calculation time. Batch Priority Routing is the name for this method (BPR).
To produce high-quality and more efficient inference predictions, it turns out that dropping the suitable tokens is required. BPR is far more resistant to low capacity. Overall, V-MoEs are found to be very adaptable at inference time. Without further training on the model weights, reducing the number of picked experts per token is possible to save time and calculation.
The Road Ahead:
There’s still so much to learn about the inner workings of sparse networks. As a result, the researchers looked at the V-MoE routing patterns.
One theory is that routers will learn to distinguish between experts and assign tokens to them based on semantic criteria. In the deeper levels of the network, some semantic clustering of the patches is noticed.
Researchers believe that conditional computation at scale for computer vision is just getting started. Dependent variable-length routes and heterogeneous expert architectures are also attractive directions. Sparse models can be advantageous in domains with a lot of data, such as large-scale video modeling. The researchers expect that by making their code and models open-source, they would attract and engage fresh researchers in this field.
Paper: https://arxiv.org/pdf/2106.05974.pdf
Reference: https://ai.googleblog.com/2022/01/scaling-vision-with-sparse-mixture-of.html
Suggested

Credit: Source link
Comments are closed.