Google AI Introduces Visually Rich Document Understanding (VRDU): A Dataset for Better Tracking of Document Understanding Task Progress
More and more papers are being created and stored by businesses in today’s digital age. Although these papers may include useful information, they are sometimes easy to read and comprehend. Invoices, forms, and contracts that are also visually complex present an even bigger difficulty. The layouts, tables, and graphics in such publications might make it challenging to parse out the useful information.
To close this knowledge gap and improve progress tracking on document understanding tasks, Google researchers have announced the availability of the new Visually Rich Document Understanding (VRDU) dataset. Based on the types of real-world documents typically processed by document understanding models, they present five criteria for an effective benchmark. The paper details how most commonly used datasets in the research community fall short in at least one of these areas, while VRDU excels in every one. Researchers at Google are pleased to share that the VRDU dataset and assessment code are now available to the public under a Creative Commons license.
The goal of the research branch, Visually Rich Document Understanding (VRDU), is to find ways to understand such materials automatically. Structured information like names, addresses, dates, and sums can be extracted from documents using VRDU models. Invoice processing, CRM, and fraud detection are just a few examples of how businesses might put this information to use.
VRDU faces a lot of obstacles. The wide range of document types represents one obstacle. Because of their intricate patterns and arrangements, visually rich papers present a further difficulty. VRDU models must be able to deal with imperfect inputs like typos and gaps in the data.
Despite the obstacles, VRDU is a promising and quickly developing field. VRDU models can aid firms in reducing costs and increasing efficiency while enhancing their operations’ precision.
Over the past few years, sophisticated automated systems have been developed to process and convert complicated business documents into structured objects. Manual data entry is time-consuming; a system that can automatically extract data from documents like receipts, insurance quotes, and financial statements might dramatically increase corporate efficiency by eliminating this step. Newer models built on the Transformer framework have shown significant accuracy improvements. These business processes are also being optimized with the help of larger models like PaLM 2. However, the difficulties observed in real-world use cases are not reflected in the datasets utilized in academic publications. This means that while models perform well on academic criteria, they underperform in more complex real-world contexts.
Measurement standards
First, researchers contrasted academic benchmarks (e.g., FUNSD, CORD, SROIE) with state-of-the-art model accuracy (e.g., with FormNet and LayoutLMv2) on real-world use cases. Researchers found that state-of-the-art models provided significantly less accuracy in practice than those used as academic benchmarks. Then, they compared common datasets with document understanding models to academic benchmarks and developed five conditions for a dataset to reflect the complexity of real-world applications accurately.
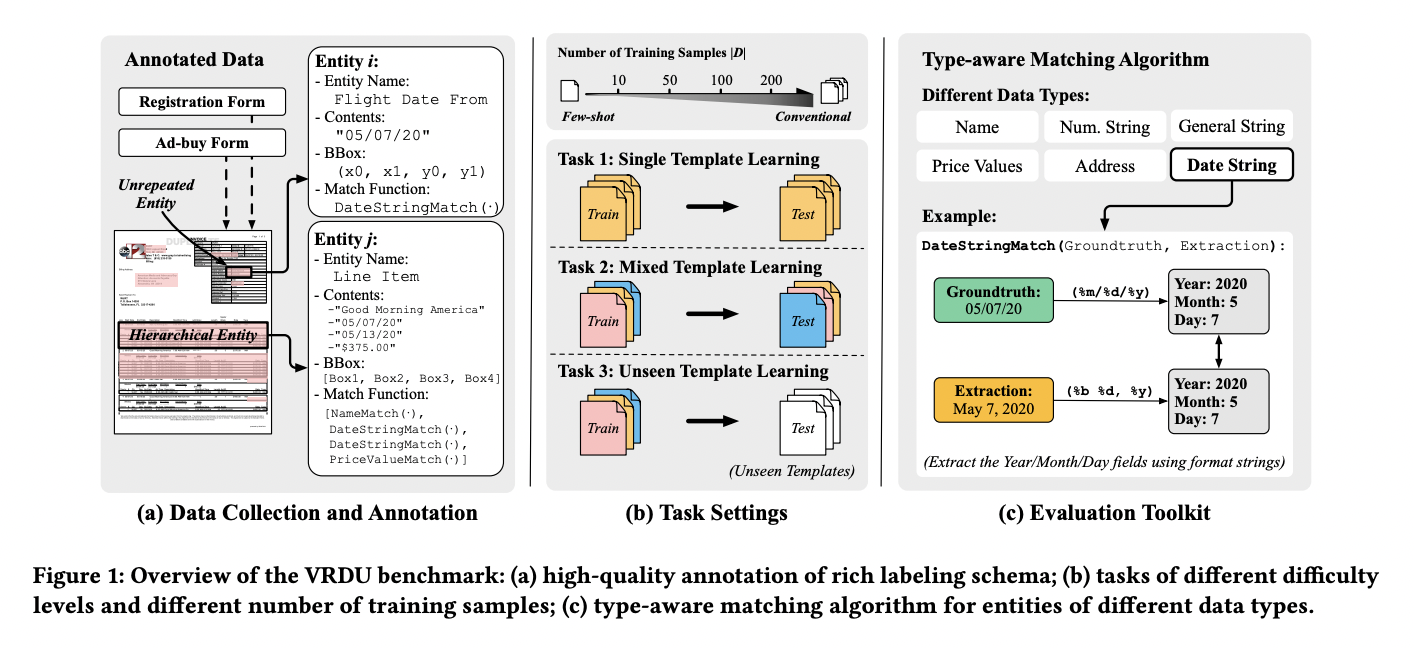
In their research, scientists encounter various rich schemas used for structured extraction. Numeric, text, date, and time information are just a few of the many sorts of entities’ data that might be necessary, optional, repeated, or even nested. Typical issues in practice should be reflected in extraction operations performed over simple flat schemas (header, question, answer).
Complex Layout Elements The documents should have a lot of different types of layout elements. Problems arise when documents incorporate tables, key-value pairs, single-column and double-column layouts, variable font sizes for various sections, images with captions, and footnotes. In contrast, the classic natural language processing research on long inputs often focuses on datasets where most papers are arranged in sentences, paragraphs, and chapters with section headers.
Templates with varying structures should be included in any useful benchmark. High-capacity models can quickly memorize the structure of a given template, making extraction from it a breeze. The train-test split of a benchmark should evaluate this ability to generalize to new templates/layouts because it is essential in practice.
Optical Character Recognition (OCR) results should be high quality for all submitted documents. This benchmark aims to eliminate the effects of varying OCR engines on VRDU performance.
Annotation at the Token Level: Documents should include ground-truth annotations that may be mapped back to matching input text, allowing individual tokens to be annotated as part of their respective entities. This contrasts the standard practice of passing along the text of the entity’s value to be parsed. This is essential for producing pristine training data, free from accidental matches to the supplied value, so researchers can focus on other aspects of their work. If the tax amount is zero, the ‘total-before-tax’ field on a receipt may have the same value as the ‘total’ field. By annotating at the token level, training data can be avoided in which both occurrences of the matching value are designated as ground truth for the ‘total’ field, leading to noisy examples.
Datasets and tasks in VRDU
The VRDU collection comprises two separate public datasets—the Registration Forms and Ad-Buy Forms datasets. These data sets offer instances that apply to real-world scenarios and meet all five of the benchmarks mentioned above criteria.
641 files in the Ad-buy Forms collection describe aspects of political advertisements. A TV station and an advocacy group have each signed an invoice or a receipt. Product names, air dates, total costs, and release times are only some details recorded in the documents’ tables, multi-columns, and key-value pairs.
There are 1,915 files in the Registration Forms collection that detail the background and activities of foreign agents who registered with the United States government. Important details concerning foreign agents engaged in activities that must be made public are recorded in each document. Name of the registrant, linked agency address, activities registered for, and other information.
Recent VRDU Developments
There have been many developments in VRDU in recent years. Large-scale linguistic models (LLMs) are one such innovation. Large-scale representational similarity measures (LLMs) are trained on large datasets of text and code and can be used to represent the text and layout of graphically rich texts.
The creation of “few-shot learning techniques” is another significant achievement. With few-shot learning approaches, VRDU models may quickly learn to extract information from novel document types. This is significant since it expands the kinds of texts to which VRDU models may be applied.
Google Research has made the VRDU benchmark available to the research community. Invoices and forms are two examples of visually rich documents included in the VRDU standard. There are 10,000 invoices in the invoices dataset and 10,000 forms in the forms dataset. The VRDU benchmark also features a well-thought-out set of tools for assessing performance.
Researchers in the field of VRDU will find the benchmark an invaluable tool. Researchers may now evaluate how well various VRDU models perform on the same text corpus. The VRDU benchmark is useful for more than just spotting problems; it can also assist in direct future study in the area.
- Structured data such as can be extracted from documents using VRDU models.
- Names, Addresses, Dates, Amounts, Products, Services, Conditions and Requirements.
- Several useful business procedures can be automated with the use of VRDU models, including:
- Handling Invoices, Marketing to and managing existing customers, Detection of Fraud Compliance, Reporting to Authorities.
- By decreasing the amount of hand-keyed information in systems, VRDU models can boost the precision of company operations.
- By automating the document-processing workflow, VRDU models can help businesses save time and money.
- Organizations can use VRDU models to boost customer satisfaction by expediting and perfecting their service.
The future of VRDU
The outlook for VRDU is optimistic. The development of LLMs and few-shot learning methods will lead to more robust and flexible VRDU models in the future. Because of this, VRDU models can be used to automate more business processes and with more types of documents.
When used to document processing and comprehension in the corporate world, VRDU could have a profound impact. Virtual Reality Document comprehension (VRDU) can save businesses time and money by automating the process of document comprehension, and it can also help to increase the accuracy of business operations.
Experiments presented by Google researchers further demonstrate the difficulty of VRDU tasks and the significant opportunity for improvement in contemporary models compared to the datasets generally utilized in the literature, where F1 scores of 0.90+ are typical. The VRDU dataset and evaluation code will be made publicly available in the hopes that it will aid in advancing the state of the art of document comprehension across research teams.
Check out the Paper and Google Blog. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 28k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.