Google AI Introduces ViT-22B: The Largest Vision Transformer Model 5.5x Larger Than The Previous Largest Vision Model ViT-e
Transformers have demonstrated remarkable abilities in various natural language processing (NLP) tasks, including language modeling, machine translation, and text generation. These neural network architectures have been scaled up to achieve significant breakthroughs in NLP.
One of the main advantages of the Transformer architecture is its ability to capture long-range dependencies in text, which is crucial for many NLP tasks. However, this comes at the cost of high computational requirements, making it challenging to train large Transformer models.
Researchers have been pushing the limits of scaling Transformers to larger models in recent years, using more powerful hardware and distributed training techniques. This has led to significant improvements in language model performance on various benchmarks, such as the GLUE and SuperGLUE benchmarks.
Large Language Models (LLMs) such as PaLM and GPT-3 have demonstrated that scaling transformers to hundreds of billions of parameters improves performance and unlocks emergent abilities. However, the largest dense models for image understanding have only reached 4 billion parameters, despite research indicating that multimodal models like PaLI benefit from scaling their language and vision models. Therefore, the scientists decided to take the next step in scaling the Vision Transformer, motivated by the results from scaling LLMs.
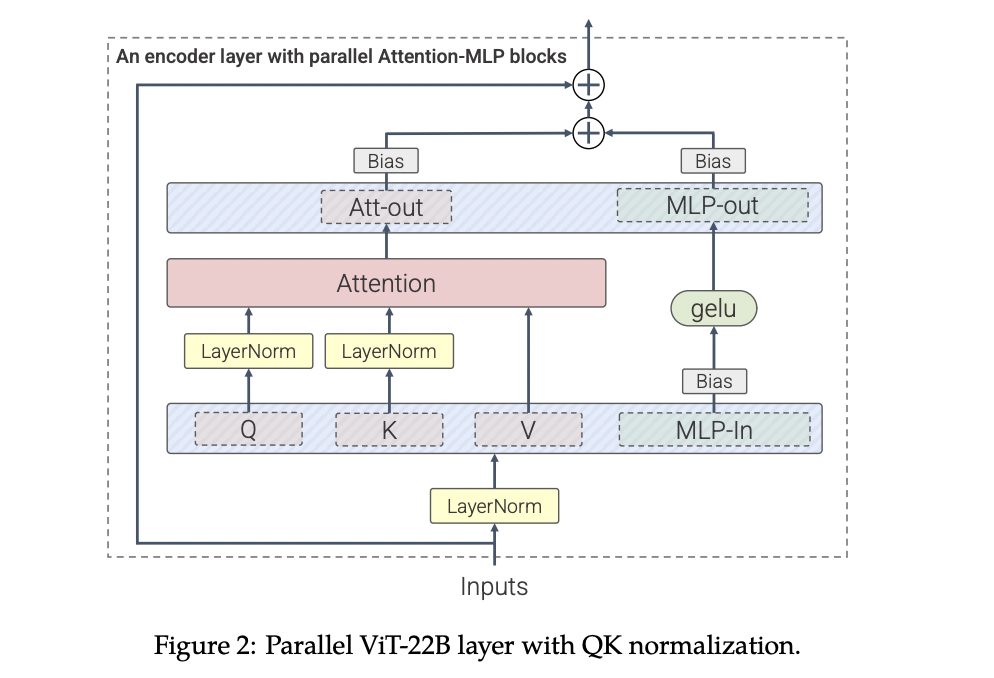
The article presents ViT-22B, the biggest dense vision model introduced to date, with 22 billion parameters, 5.5 times larger than the previous largest vision backbone, ViT-e, with 4 billion parameters. To achieve this scaling, the researchers incorporate ideas from scaling text models like PaLM, which includes improvements to training stability through QK normalization and training efficiency using a novel approach called asynchronous parallel linear operations. ViT-22B could be trained on Cloud TPUs with high hardware utilization with its modified architecture, efficient sharding recipe, and bespoke implementation. The model advances the state-of-the-art on many vision tasks with either frozen representations or full fine-tuning. Additionally, it has been successfully used in PaLM-e, which demonstrated that a large model combining ViT-22B with a language model could significantly advance state of the art in robotics tasks.
The researchers built on advancements in Large Language Models such as PaLM and GPT-3 to create ViT-22B. They used parallel layers, where attention and MLP blocks are executed parallel rather than sequentially as in the standard Transformer architecture. This approach was used in PaLM and reduced training time by 15%.
ViT-22B omits biases in the QKV projections and LayerNorms, which increases utilization by 3%. Sharding is necessary for models of this scale, and the team shard both model parameters and activations. They developed an asynchronous parallel linear operations approach, where communication of activations and weights between devices occur simultaneously as computations in the matrix multiply unit, minimizing the time waiting on incoming communication and increasing device efficiency.
Initially, the new model scale resulted in severe training instabilities. The normalization approach of Gilmer et al. (2023, upcoming) resolved these issues, enabling smooth and stable model training.
ViT-22B was evaluated with human comparison data and had state-of-the-art alignment with human visual object recognition. Like humans, the model has a high shape bias and mainly uses object shape to inform classification decisions. This suggests an increased similarity with human perception compared to standard models.
ViT-22B is the largest vision transformer model at 22 billion parameters and achieved state-of-the-art performance with critical architecture changes. It shows increased similarities to human visual perception and offers benefits in fairness and robustness. It uses frozen models to produce embeddings, and training thin layers on top yields excellent performance on several benchmarks.
Check out the Paper and Google Blog. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 17k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.

Niharika is a Technical consulting intern at Marktechpost. She is a third year undergraduate, currently pursuing her B.Tech from Indian Institute of Technology(IIT), Kharagpur. She is a highly enthusiastic individual with a keen interest in Machine learning, Data science and AI and an avid reader of the latest developments in these fields.
Credit: Source link
Comments are closed.