Google AI Introduces ‘WIT’, A Wikipedia-Based Image Text Dataset For Multimodal Multilingual Machine Learning
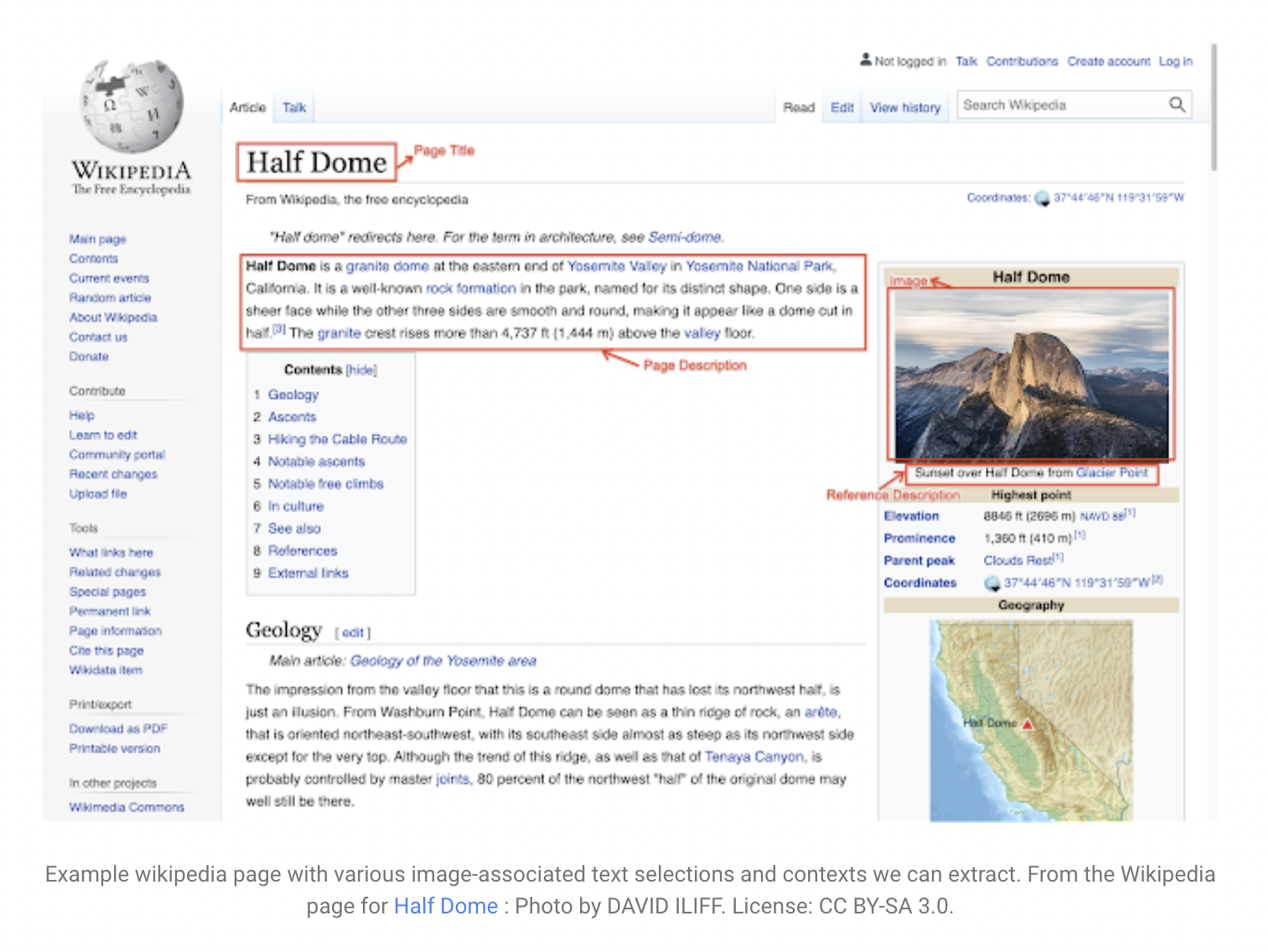

Image and text datasets are widely used in many machine learning applications. To model the relationship between images and text, most multimodal Visio-linguistic models today rely on large datasets. Historically, these datasets were created by either manually captioning images or crawling the web and extracting the alt-text as the caption. While the former method produces higher-quality data, the intensive manual annotation process limits the amount of data produced. The automated extraction method can result in larger datasets. However, it requires either heuristics and careful filtering to ensure data quality or scaling-up models to achieve robust performance.
To overcome these limitations, Google research team created a high-quality, large-sized, multilingual dataset called the Wikipedia-Based Image Text (WIT) Dataset. It is created by extracting multiple text selections associated with an image from Wikipedia articles and Wikimedia image links.

The WIT Dataset
The researcher planned to create a large dataset without sacrificing quality or concept coverage. As a result, they began by utilizing the largest online encyclopedia available today: Wikipedia. They started selecting images from Wikipedia pages and extracted various image-text associations and surrounding contexts. This yielded a curated database of 37.5 million entity-rich image-text examples in 108 languages, with 11.5 million unique images.
They employed a rigorous filtering process to refine the data further and ensure data quality. The process includes:
- Text-based filtering that ensures caption availability, length, and quality
- Image-based filtering that ensures that each image is a specific size with permissible licensing
- Image-and-text-entity–based filtering to ensure research suitability (e.g., excluding those classified as hate speech).
Human editors were given a set of random picture captions to evaluate. They universally concluded that 98 percent of the samples had good image caption alignment.
The WIT dataset offers multiple benefits, and a few of them are listed below:
- Highly Multilingual: WIT is the first large-scale, multilingual, multimodal dataset, with data in 108 languages.

- First Contextual Image-Text Dataset: Most multimodal datasets simply provide a single text caption (or numerous copies of a similar phrase) for every image. WIT is the first dataset to include contextual data, which can aid academics in modeling the impact of context on image captions and image selection.

WIT’s major textual fields: text captions, and contextual information, in particular, could be beneficial for research. WIT has extensive coverage in each of these fields, as seen below.

- A High-Quality Training Set and Evaluation Benchmark: The WIT evaluation sets serve as a challenging benchmark, even for state-of-the-art methods, thanks to Wikipedia’s vast coverage of varied ideas. The WIT test set has mean recall scores in the 40s for well-resourced languages and the 30s for under-resourced languages.
The team believes that the proposed dataset will help researchers to develop stronger, more robust models.
Under the Creative Commons license, the WIT dataset is available for download and use. In collaboration with Wikimedia Research and some external collaborators, Google AI announced that they would soon host a Kaggle competition using the WIT dataset.
Wikipedia has made accessible images at a 300-pixel resolution and Resnet-50–based image embeddings for the majority of the training and test datasets to aid research in this field. In addition to the WIT dataset, Kaggle will store all of this image data and give colab notebooks. Additionally, the participants will have access to a Kaggle discussion area to share code and communicate. This makes it simple for anyone interested in multimodality to get started and conduct experiments.
Github: https://github.com/google-research-datasets/wit
Research: https://arxiv.org/pdf/2103.01913.pdf
Source: https://ai.googleblog.com/2021/09/announcing-wit-wikipedia-based-image.html
Suggested
Credit: Source link
Comments are closed.