Google AI Propose A Novel Generative Modeling Framework Called ‘EHR-Safe’ For Generating Highly Realistic And Privacy-Preserving Synthetic EHR Data
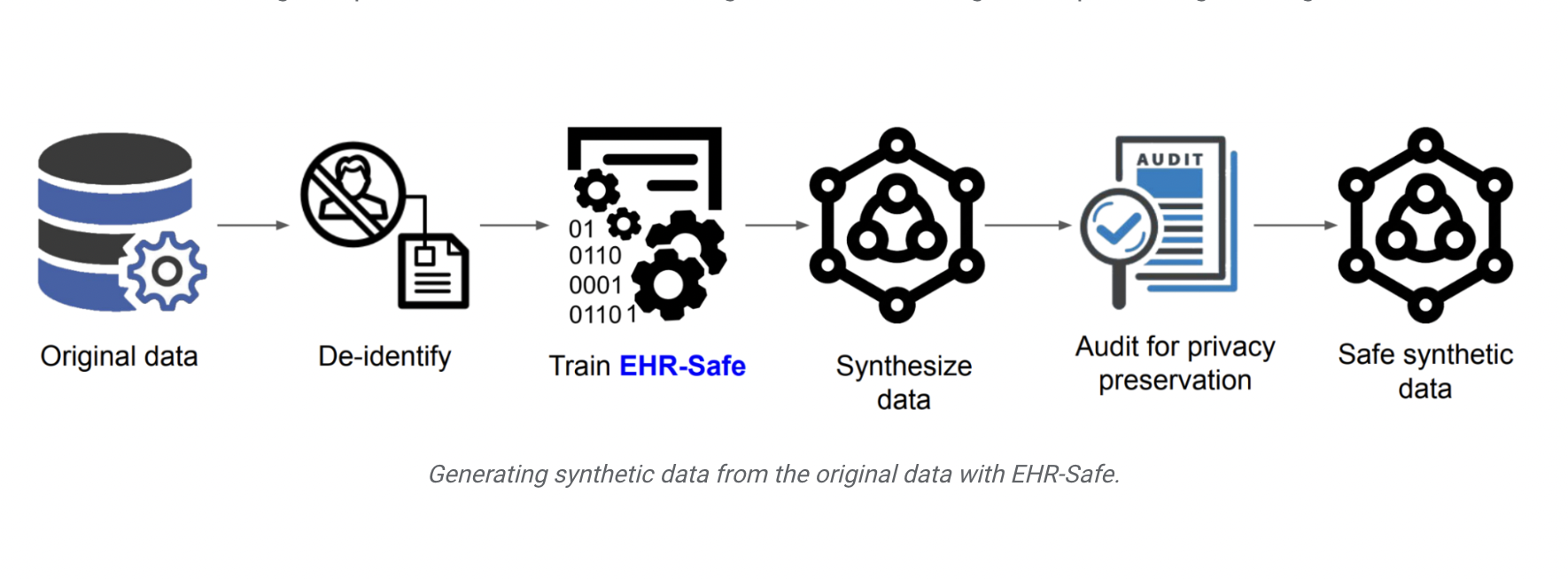
The potential of EHR to improve patient care, integrate performance measurements into clinical practice, and streamline clinical research is enormous. Diseases may be diagnosed using statistical estimation or machine learning models trained on electronic health record data (such as diabetes, tracking patient wellness, and predicting how patients respond to specific drugs). Both academics and industry professionals require access to data to construct such models. However, a key obstacle to data access remains data privacy concerns and patient confidentiality restrictions.
Traditional approaches to data anonymization are time-consuming and expensive. Even when the de-identification procedure is performed in line with established standards, they might distort essential information from the original dataset. This drastically reduces the data’s utility, making it vulnerable to privacy threats.
The New Google study presents EHR-Safe, a novel generative modeling method to achieve this goal. In their paper, “EHR-Safe: Generating High-Fidelity and Privacy-Preserving Synthetic Electronic Health Records,” they demonstrate that synthetic data can meet two essential properties: high fidelity and meet certain privacy measures.
Their papers discuss the challenges that need to be overcome before synthetic EHR data can be produced. The properties and distributions of EHR data are varied. Features can be either numerical (like blood pressure) or categorical, with various possible categories (e.g., medical codes, mortality outcome). While some of these may be constant, others may change over time, including routine or ad hoc laboratory measurements.
The team highlights that both categorical and numeric distributions can be severely asymmetrical. Variation in sequence lengths is often substantially higher than other time-series data since the frequency of visits varies greatly from patient to patient and from condition to condition. Since not all laboratory values and other input data are always collected, there can be a significant proportion of missing characteristics across patients and time points.
Sequential encoder-decoder architecture and generative adversarial networks (GANs) make up EHR-Safe. Direct modeling of raw EHR data is difficult for GANs due to the heterogeneity of EHR data. Therefore, the researchers suggest using a sequential encoder-decoder architecture to learn the mapping from raw EHR data to the latent representations and vice versa to get over this problem.
Esoteric distributions of numerical and categorical data are a significant obstacle to overcome when learning the mapping. The capacity to model uncommon situations is crucial, even if some values or numerical ranges predominate the distribution.
The team claims that transforming the data into distributions where encoder-decoder and GAN training is more stable is the key to working with such information. They are able to do this with the help of feature mapping and stochastic normalization techniques that transforms original feature distributions into uniform distributions without information loss. The encoder’s output of mapped latent representations is fed into an adversarial generator network (GAN).
After training on a large dataset, the encoder-decoder framework and GANs work together to allow EHR-Safe to produce synthetic heterogeneous EHR data from any input fed as a series of randomly sampled vectors.
The researchers focus on two actual EHR datasets to demonstrate the EHR-Safe system: MIMIC-III and eICU. These are inpatient datasets with missing data across various numerical and categorical characteristics.
For each characteristic, they quantitatively compare the statistical similarity between real and synthetic data. In most cases, the highest cumulative distribution function (CDF) difference between the original and the synthetic data is less than 0.03. This indicates that the original and synthetic data are statistically quite similar.
Their main focus during the assessment was on the fidelity metric, which assesses how well models trained on synthetic data generalize to real data. They evaluate the effectiveness of such a model compared to a similar model trained with real data. If the models perform similarly, the synthetic data successfully replicates the real-world environment. To that end, they focus on the mortality prediction task as one of EHR’s most promising future applications. When comparing the best model on real data to the best model on synthetic data, the difference is only 2.6% for MIMIC-GBDT III’s and 0.9% for eICU’s RF.
Across the board, they find privacy metrics are close to perfection. As a result, EHR-Safe is not merely memorization of the original train data, and the risk of understanding whether a sample of the original data is a member used for training the model is extremely near to random guessing. They also evaluate how well a classifier predicts when trained on actual data versus when trained on synthetic data. Their findings show that having access to synthetic data does not improve the prediction ability of individual features.
Check out the Paper and Google blog. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.