Google AI Propose A Patch-Based Multi-Scale Image Quality Transformer (MUSIQ) To Bypass The Convolutional Neural Network (CNN) Constraints On Fixed Input Size And Predict The Image Quality Effectively On Native-Resolution Images
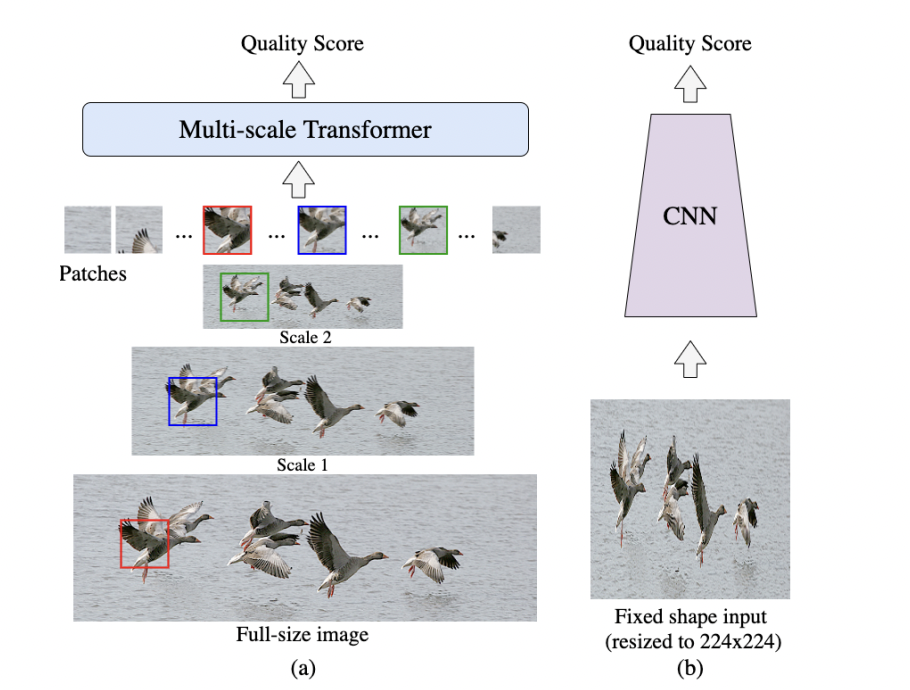
The evaluation of image quality (IQA) is a crucial area of study for comprehending and enhancing the visual experience. In order to give users a better visual experience, it is vital to understand images’ aesthetic and technical quality. IQA uses models to create a link between an image and the user’s assessment of its quality. Modern, cutting-edge IQA techniques like NIMA are built on convolutional neural networks (CNNs). However, the batch training constraint regarding fixed shape input frequently degrades their performance. The input photographs are typically enlarged and cropped to a set shape to accommodate this, compromising the image quality.
Google Research introduced “MUSIQ: Multi-scale Image Quality Transformer,” published at ICCV 2021, to address these problems. This patch-based multi-scale image quality transformer (MUSIQ) can accurately forecast the picture quality on native-resolution images by bypassing the CNN restrictions on the fixed input size. This suggested method can capture image quality at varying granularities using a multi-scale image representation. To support the positional embedding in the multi-scale representation, a unique hash-based 2D spatial embedding and scale embedding are also proposed. MUSIQ was put to the test on four sizable IQA datasets in order to be evaluated. It showed consistent state-of-the-art results on the PaQ-2-PiQ, KonIQ-10k, and SPAQ technical quality datasets and equivalent performance to state-of-the-art models on the AVA aesthetic quality dataset.
MUSIQ’s main selling point is that it takes on the problem of teaching IQA using full-size input images. Unlike CNN models, which are frequently restricted to set resolution, it can take inputs with various aspect ratios and resolutions. To do this, a multi-scale representation of the input image was first created, encompassing both the original resolution image and its downsized variations. Following the creation of the picture pyramid, the images are divided into fixed-size patches at various scales and fed into the model. The image’s aspect ratio is preserved after resizing to protect the composition.
The multi-aspect-ratio multi-scale input must be encoded into a sequence of tokens, collecting pixel, spatial, and scale information, as images of varied resolutions make up the patches. To do this, the team created three encoding elements for MUSIQ. A patch encoding module is included in the first component to encode patches taken from the multi-scale representation. The second component consists of a unique hash-based spatial embedding module to encode the 2D spatial position for each patch. The third component is a learnable scale embedding to encode different scales. Researchers successfully encoded the multi-scale input as a series of tokens, which they then used as the Transformer encoder’s input.
The researchers followed the conventional procedure of appending an additional learnable “classification token” (CLS) to the final image quality score prediction. The final picture representation is the CLS token state at the Transformer encoder output. Furthermore, a fully connected layer is built on top to forecast the IQS. MUSIQ is compatible with all Transformer variations because it just modifies the input encoding, another critical feature that will be useful to the community.
On a variety of sizable IQA datasets, MUSIQ was assessed. For each dataset, the correlation between the model prediction and the mean opinion score of the human evaluators, as measured by Spearman’s rank correlation coefficient (SRCC) and Pearson linear correlation coefficient (PLCC), was given. Better congruence between model predictions and human evaluation is shown by higher PLCC and SRCC. It was concluded that MUSIQ performs better on PaQ-2-PiQ, KonIQ-10k, and SPAQ than other approaches. Notably, the PaQ-2-PiQ test set is made up exclusively of sizable images, each of which has at least one dimension of more than 640 pixels. This is quite difficult for standard deep learning methods, which call for scaling. On the full-size test set, MUSIQ can perform noticeably better than earlier techniques, demonstrating the durability and efficiency of the system.
It is also important to note that earlier CNN-based techniques frequently needed testing samples of up to 20 different cropping for each image. Additionally, because CNN-based approaches sample a variety of crops, they can introduce randomness into the outcome while also increasing the inference cost for each crop. On the other hand, MUSIQ only needs to execute the inference once because it accepts the full-size image as input and can thus directly learn the optimum aggregate of information across the entire image. The team also noticed that MUSIQ tends to concentrate on more global areas on the scaled photos and on more detailed areas on the whole, high-resolution images. This demonstrates how the model can pick up image quality at various granularities.
Simply stated, Google’s multi-scale image quality transformer (MUSIQ) can process full-size image input with a range of resolutions and aspect ratios. The model can capture the image quality at various granularities by translating the input image into a multi-scale representation with global and local views. MUSIQ can be used in various situations where task labels are sensitive to image resolution and aspect ratio, although it was created for IQA. One may find more information on the model in their GitHub repository.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'MUSIQ: Multi-scale Image Quality Transformer'. All Credit For This Research Goes To Researchers on This Project. Check out the paper, github link and reference article.
Please Don't Forget To Join Our ML Subreddit
![]()
Asif Razzaq is an AI Journalist and Cofounder of Marktechpost, LLC. He is a visionary, entrepreneur and engineer who aspires to use the power of Artificial Intelligence for good.
Asif’s latest venture is the development of an Artificial Intelligence Media Platform (Marktechpost) that will revolutionize how people can find relevant news related to Artificial Intelligence, Data Science and Machine Learning.
Asif was featured by Onalytica in it’s ‘Who’s Who in AI? (Influential Voices & Brands)’ as one of the ‘Influential Journalists in AI’ (https://onalytica.com/wp-content/uploads/2021/09/Whos-Who-In-AI.pdf). His interview was also featured by Onalytica (https://onalytica.com/blog/posts/interview-with-asif-razzaq/).
Credit: Source link
Comments are closed.