Google AI Proposes a Two-Stage Model that Reconceives Traditional Image Quantization Techniques to Yield Improved Performance on Image Generation and Image Understanding

This Article Is Based On The Research Paper 'VECTOR-QUANTIZED IMAGE MODELING WITH IMPROVED VQGAN'. All Credit For This Research Goes To The Researchers of This Project 👏👏👏 Please Don't Forget To Join Our ML Subreddit
For various natural language generation and interpretation tasks, natural language processing models have recently enhanced their ability to acquire general-purpose representations, which has led to significant performance advances. Pre-training language models on big unlabeled text corpora have been a substantial factor in this success.
This pre-training formulation does not make any assumptions as far as input signal modalities go. Pre-quantifying images into discrete integer codes (expressed as natural numbers) and modeling them autoregressively has been used in several recent publications to improve image generating results significantly (i.e., predicting sequences one token at a time). To encode a picture into tokens, a convolutional neural network (CNN) is trained each corresponding to a specific patch of the image. It is then used to train a second-stage CNN or Transformer to simulate the distribution of encoded latent variables. After the training, the second step can be used to autoregressively produce a picture. Few studies have examined how the learned representation performs in subsequent discriminative tasks, despite its excellent performance in image formation (such as image classification).
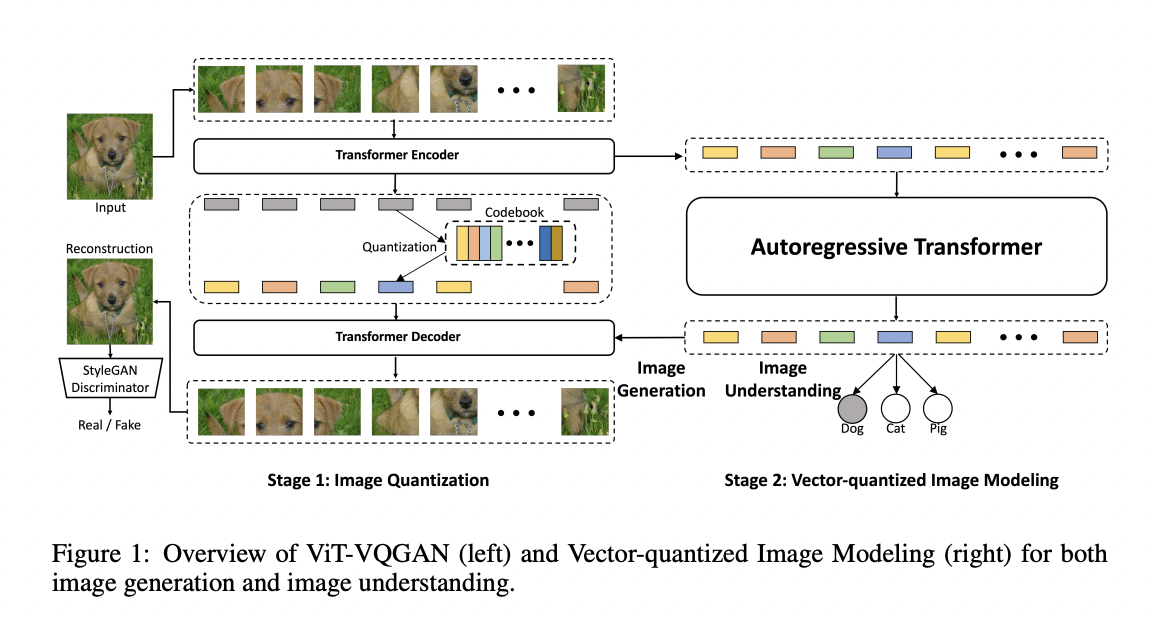
“Vector-Quantized Image Modeling with Improved VQGAN” proposes a two-stage model that reinvents classic image quantization methods to produce better picture generation and image understanding tasks. The first step is to encode an image into discrete latent codes of lesser dimensions using an image quantization model called VQGAN. A Transformer model models the quantized latent coding of an image. The Vector-quantized Picture Modeling (VIM) approach can be utilized for image production and unsupervised image representation learning. This article discusses several enhancements to the image quantizer and demonstrates that training a stronger image quantizer is a critical component for improving image production and understanding.
An algorithm for vector quantization of image data using ViT-VQGAN
The Vector-quantized Variational AutoEncoder (VQVAE), a CNN-based auto-encoder whose latent space is a matrix of discrete learnable variables and which is trained end-to-end, is a popular, contemporary model that quantizes pictures into integer tokens. With transformer-like elements in the form of attention blocks, VQGAN can capture remote interactions using fewer layers. Improved VQGAN introduces an adversarial loss to encourage high-quality reconstruction.
The CNN encoder and decoder can be replaced with ViT, which goes further. A low-dimensional latent variable space is projected from the encoder’s output into a linear projection, which allows to look up the integer tokens in that space. Additionally, the encoder output is decreased to a 32- or 8-dimension vector per code, encouraging the decoder to utilize token outputs better and improve model capacity and efficiency.

This ViT-VQGAN has been trained to encode images into discrete tokens, representing an 8×8 patch on the input image. Training a decoder-only Transformer for autoregressive prediction is done using the following tokens. By sampling token-by-token from the Transformer model’s output softmax distribution, VIM’s two-stage model may generate images without a prior understanding of their intended application.
For example, VIM can generate an image specific to the class in which it is being used (e.g., a dog or a cat). Prefixing a class-ID token before each picture token during training and sampling enables us to generate class-conditioned images.

A softmax layer (learnable) that projects the averaged features to class logits is inserted, similar to ImageGPT, to average the series of token attributes. This method helps collect intermediate aspects that are useful for learning representations. A linear projection layer is also fine-tuned to conduct ImageNet classification, a standard benchmark for testing picture understanding capabilities.
Results of Experimentation
All ViT-VQGAN models are trained on 128 CloudTPUv4 cores with a training batch size of 256. A 256×256 input image resolution is used for all models’ training. Compared to prior work, the pre-learned ViT-VQGAN image quantizer is supplemented by the training of Transformer models for both unconditional and class-conditioned picture synthesis.
Class-conditioned picture synthesis and unsupervised representation learning are evaluated using the well-known ImageNet benchmark. The Fréchet Inception Distance is used in the table below to demonstrate the class-conditioned image synthesis performance (FID). FID is increased to 3.07. (lower is preferable), which is a 58.6 percent improvement over the VQGAN model in comparison (FID 7.35). VQGAN’s Inception Score (IS) rises from 188.6 to 227.4, a 20.6% increase in the ability to understand images compared to VIM.

Afterward, a linear layer is fine-tuned to perform ImageNet classification, a popular benchmark for testing picture understanding abilities and testing the learned image representations. When it comes to picture interpretation, the model beats previous generative models, increasing classification accuracy from 60.3% (iGPT-L) to 73.2 percent using linear probing. As demonstrated by these results, VIM can generate high-quality images and learn picture representations.
Conclusion
Pre Training a Transformer to predict image tokens autoregressively while using better ViT-VQGAN image quantizers is called “Vector-quantized Image Modeling” (VIM). The proposed image quantization improvements yield improved outcomes for image production and comprehension.
Paper: https://arxiv.org/pdf/2110.04627.pdf
Source: https://ai.googleblog.com/2022/05/vector-quantized-image-modeling-with.html
Credit: Source link
Comments are closed.