Google AI Proposes Contrastive Captioner (CoCa): A Novel Encoder-Decoder Model That Simultaneously Produces Aligned Unimodal Image And Text Embeddings

Machine learning (ML) model developers frequently start with a basic backbone model that has been trained at scale and can be applied to a variety of downstream applications. Several popular backbone models in natural language processing, such as BERT, T5, and GPT-3 (also known as “foundation models”), are pre-trained on web-scale data and have exhibited general multi-tasking capabilities of zero-shot, few-shot, or transfer learning. Pre-training backbone models for many downstream jobs can amortize training costs, helping one overcome resource constraints when developing large-scale models instead of training over-specialized individual models.
Pioneering work in computer vision has demonstrated the ability of single-encoder models pre-trained for picture classification to capture generic visual representations useful for various downstream applications. Web-scale noisy image-text pairs have been used to train contrastive dual-encoder (CLIP, ALIGN, Florence) and generative encoder-decoder (SimVLM) techniques. Dual-encoder models are excellent at zero-shot picture categorization, but they are less suitable for common vision-language understanding. On the other hand, encoder-decoder approaches are good at image captioning and visual question answering but not retrieval-style tasks.
Google AI researchers provide a unified vision backbone model called Contrastive Captioner in “CoCa: Contrastive Captioners are Image-Text Foundation Models” (CoCa). The proposed model is a novel encoder-decoder strategy that generates aligned unimodal image and text embeddings and joint multimodal representations, making it versatile enough to be used for a variety of downstream applications. CoCa, in particular, produces cutting-edge performance on vision and vision-language tasks, including vision identification, cross-modal alignment, and multimodal understanding. It also learns extremely generic representations, allowing it to compete with or outperform thoroughly fine-tuned models using zero-shot learning or frozen encoders.
https://ai.googleblog.com/2022/05/image-text-pre-training-with.html
Method
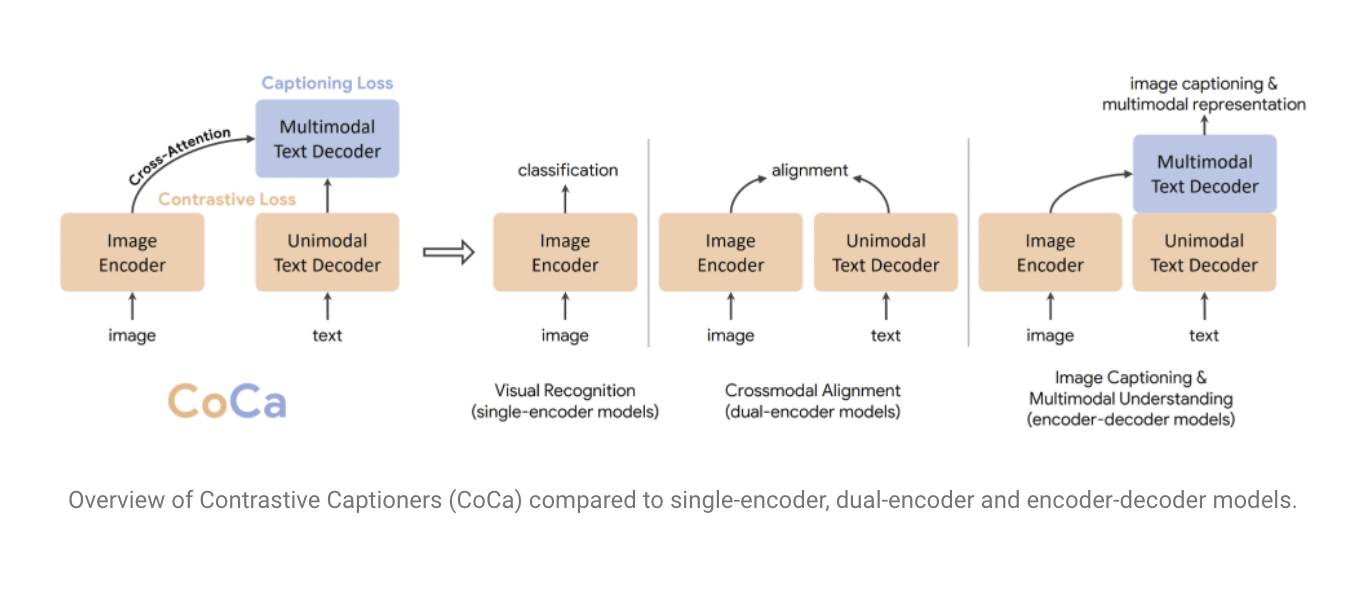
CoCa is a unified training system that effectively combines single-encoder, dual-encoder, and encoder-decoder paradigms by integrating contrastive loss and captioning loss on a single training data stream consisting of picture annotations and noisy image-text pairs.
For this purpose, They describe a new encoder-decoder architecture. The encoder is a vision transformer (ViT), and the text decoder transformer is split into two parts: a unimodal and a multimodal text decoder. They cascade multimodal decoder layers with cross-attention to picture encoder outputs to learn multimodal image-text terms for captioning loss. This approach maximizes the model’s versatility and universality in accommodating a wide range of jobs while also being trained effectively with only one forward and backward propagation for both training objectives, resulting in little computational overhead. As a result, the model can be trained from the ground up with costs comparable to a naive encoder-decoder model.
Results of Benchmarking
With minimal adaptation, the CoCa model can be fine-tuned directly on various activities. Their model obtains state-of-the-art performance on several famous vision and multimodal benchmarks, including
(1) visual recognition, Kinetics-400/600/700, and MiT;
(2) cross-modal alignment, MS-COCO, Flickr30K, and MSR-VTT; and
(3) multimodal understanding, VQA, SNLI-VE, NLVR2, and NoCaps.
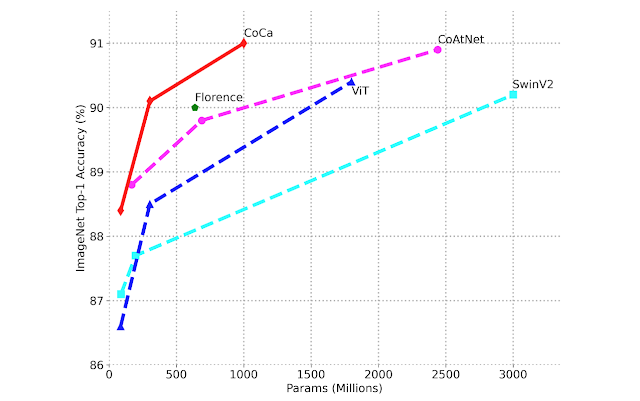
It’s worth noting that CoCa achieves these outcomes as a single model that adapts to all jobs while being significantly lighter than previous top-performing specialized models. CoCa, for example, achieves 91.0 percent ImageNet top-1 accuracy while only employing half the parameters of the latest state-of-the-art models. Furthermore, CoCa gains a power-generating capability for high-quality image descriptions.
CoCa is compared to other image-text backbone models (without task-specific modification) and a variety of state-of-the-art task-specialized models.
When comparing fine-tuned image classification scaling performance, Top-1 accuracy of ImageNet vs. model size.
CoCa created text captions using NoCaps photos as input.

Performance with No Shots
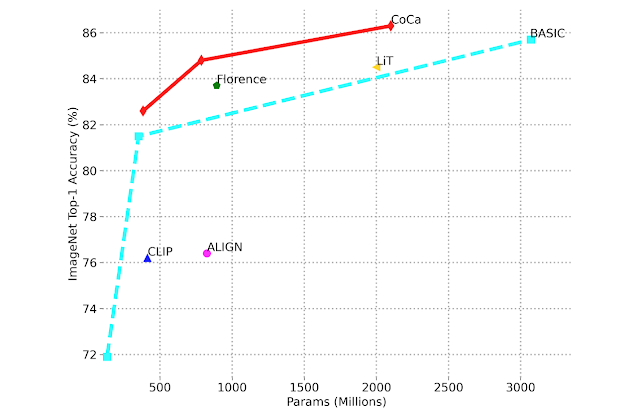
CoCa surpasses previous state-of-the-art models on zero-shot learning tasks, such as picture classification and cross-modal retrieval, and achieves exceptional performance with fine-tuning. On ImageNet, CoCa achieves 86.3 percent zero-shot accuracy while outperforming past models on challenging variation benchmarks such as ImageNet-A, ImageNet-R, ImageNet-V2, and ImageNet-Sketch. In comparison to previous approaches, CoCa achieves improved zero-shot accuracy with smaller model sizes, as seen in the image below.
Scaling performance of image categorization compared to zero-shot Top-1 accuracy of ImageNet vs. model size.
Representation of Frozen Encoders
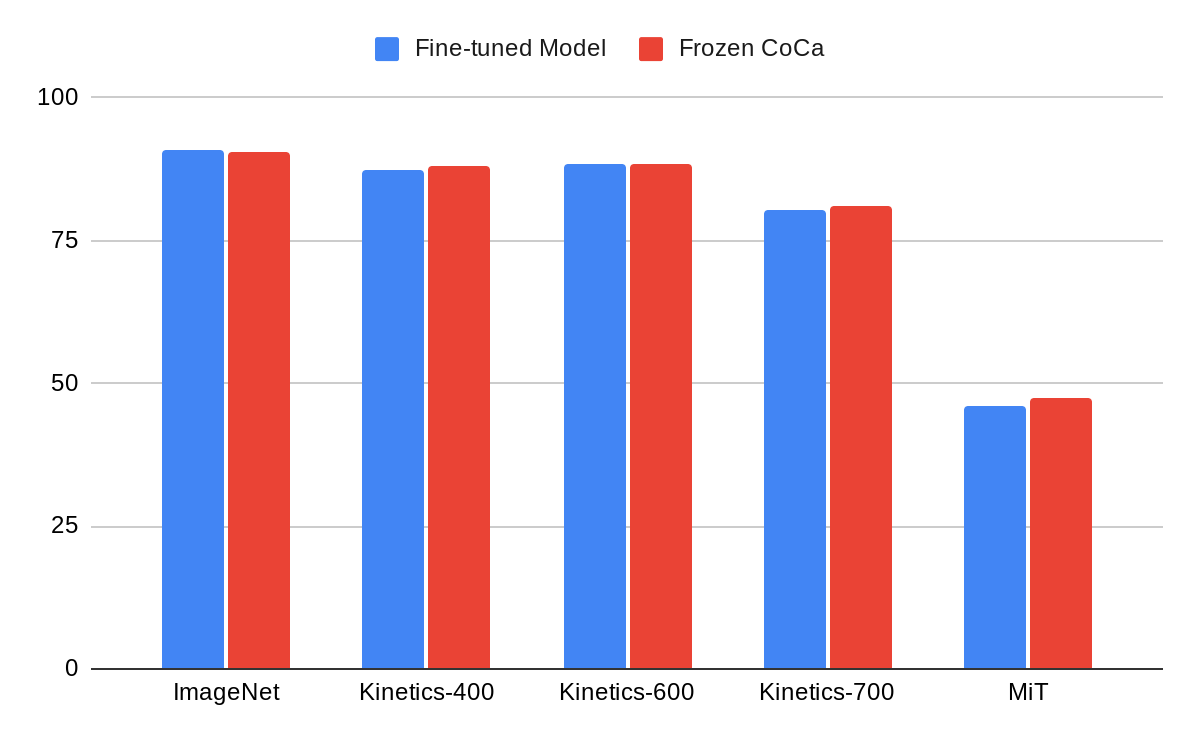
CoCa delivers performance comparable to the best-fine-tuned models using only a frozen visual encoder, which uses features extracted after model training to train a classifier rather than the more computationally costly effort of fine-tuning a model. On ImageNet, a frozen CoCa encoder with a learned classification head achieves 90.6 percent top-1 accuracy, superior to existing backbone models’ thoroughly fine-tuned performance. This approach also works exceptionally well for video recognition. They feed individual video frames into the CoCa frozen image encoder and employ attentional pooling to fuse output features before applying a learned classifier. On the Kinetics-400 dataset, this basic solution using a CoCa frozen image encoder achieves top-1 accuracy of 88.0 percent, demonstrating that CoCa learns a highly generic visual representation with the combined training objectives.
Comparison of the Frozen CoCa optical encoder with (many) fine-tuned models that perform best
Conclusion
Contrastive Captioner (CoCa) is a unique image-text backbone model pre-training paradigm. This straightforward strategy is adaptable to a wide range of vision and vision-language downstream problems, and it yields state-of-the-art results with few or no task-specific adjustments.
This Article is written as a summay by Marktechpost Staff based on the Research Paper 'CoCa: Contrastive Captioners are Image-Text Foundation Models'. All Credit For This Research Goes To The Researchers of This Project. Check out the paper, and blog. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.