Google AI Proposes Easy End-to-End Diffusion-based Text to Speech E3-TTS: A Simple and Efficient End-to-End Text-to-Speech Model Based on Diffusion
In machine learning, a diffusion model is a generative model commonly used for image and audio generation tasks. The diffusion model uses a diffusion process, transforming a complex data distribution into simpler distributions. The key advantage lies in its ability to generate high-quality outputs, particularly in tasks like image and audio synthesis.
In the context of text-to-speech (TTS) systems, the application of diffusion models has revealed notable improvements compared to traditional TTS systems. This progress is because of its power to address issues encountered by existing systems, such as heavy reliance on the quality of intermediate features and the complexity associated with deployment, training, and setup procedures.
A team of researchers from Google have formulated E3 TTS: Easy End-to-End Diffusion-based Text to Speech. This text-to-speech model relies on the diffusion process to maintain temporal structure. This approach enables the model to take plain text as input and directly produce audio waveforms.
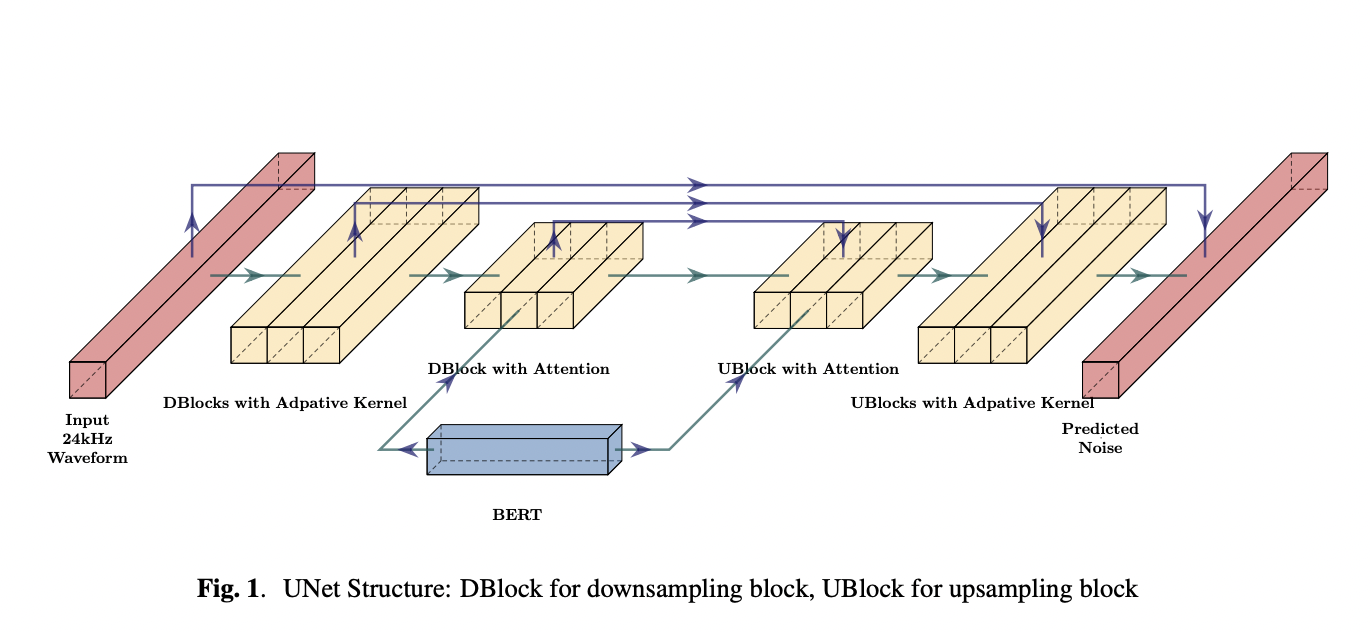
The E3 TTS model efficiently processes input text in a non-autoregressive fashion, allowing it to output a waveform directly without requiring sequential processing. Additionally, the determination of speaker identity and alignment occurs dynamically during diffusion. This model consists of two primary modules: A pre-trained BERT model is employed to extract pertinent information from the input text, and A diffusion UNet model processes the output from BERT. It iteratively refines the initial noisy waveform, ultimately predicting the final raw waveform.
The E3 TTS employs an iterative refinement process to generate an audio waveform. It models the temporal structure of the waveform using the diffusion process, allowing for flexible latent structures within the given audio without the need for additional conditioning information.
It is built upon a pre-trained BERT model. Also, the system operates without relying on speech representations like phonemes or graphemes. The BERT model takes subword input, and its output is processed by a 1D U-Net structure. It includes downsampling and upsampling blocks connected by residual connections.
E3 TTS uses text representations from the pre-trained BERT model, capitalizing on current developments in big language models. The E3 TTS relies on a pretrained text language model, streamlining the generating process.
The system’s adaptability increases as this model can be trained in many languages using text input.
The U-Net structure employed in E3 TTS comprises a series of downsampling and upsampling blocks connected by residual connections. To improve information extraction from the BERT output, cross-attention is incorporated into the top downsampling/upsampling blocks. An adaptive softmax Convolutional Neural Network (CNN) kernel is utilized in the lower blocks, with its kernel size determined by the timestep and speaker. Speaker and timestep embeddings are combined through Feature-wise Linear Modulation (FiLM), which includes a composite layer for channel-wise scaling and bias prediction.
The downsampler in E3 TTS plays a critical role in refining noisy information, converting it from 24kHz to a sequence of similar length as the encoded BERT output, significantly enhancing overall quality. Conversely, the upsampler predicts noise with the same length as the input waveform.
In summary, E3 TTS demonstrates the capability to generate high-fidelity audio, approaching a noteworthy quality level in this field.
Check out the Paper and Project Page. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Rachit Ranjan is a consulting intern at MarktechPost . He is currently pursuing his B.Tech from Indian Institute of Technology(IIT) Patna . He is actively shaping his career in the field of Artificial Intelligence and Data Science and is passionate and dedicated for exploring these fields.
Credit: Source link
Comments are closed.