Google AI Proposes Multi-Modal Cycle Consistency (MMCC) Method Making Better Future Predictions by Watching Unlabeled Videos

Recent advances in machine learning (ML) and artificial intelligence (AI) are increasingly being adopted by people worldwide to make decisions in their daily lives. Many studies are now focusing on developing ML agents that can make acceptable predictions about the future over various timescales. This would help them anticipate changes in the world around them, including the actions of other agents, and plan their next steps. Making judgments require accurate future prediction necessitates both collecting important environmental transitions and responding to how changes develop over time.
Previous work in visual observation-based future prediction has been limited by the output format or a manually defined set of human activities. These are either overly detailed and difficult to forecast, or they are missing crucial information about the richness of the real world. Predicting “someone jumping” does not account for why they are jumping, what they are jumping onto, and so on. Previous models were also meant to make predictions at a fixed offset into the future, which is a limiting assumption because we rarely know when relevant future states would occur.
A new Google study introduces a Multi-Modal Cycle Consistency (MMCC) method, which uses narrated instructional video to train a strong future prediction model. It is a self-supervised technique that was developed utilizing a huge unlabeled dataset of various human actions. The resulting model operates at a high degree of abstraction, can anticipate arbitrarily far into the future, and decides how far to predict based on context.
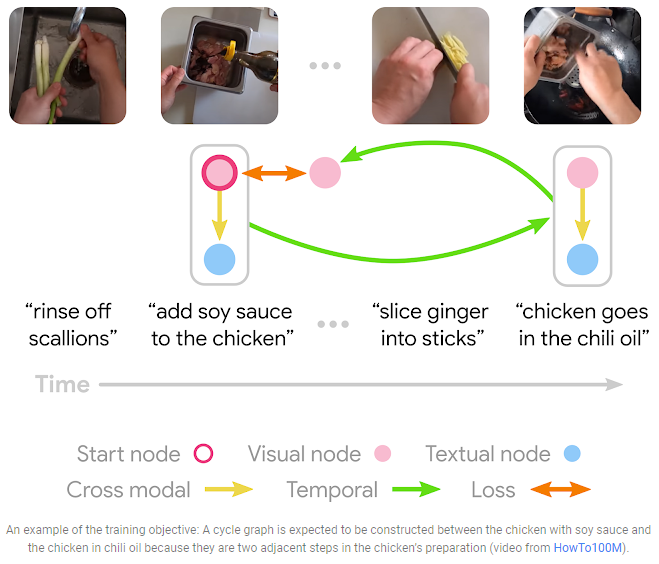
This method is based on representing narrated videos as graphs. The videos are viewed as a network of nodes, ranging from video frames to narrated text portions encoded by neural networks. MMCC creates a network from the nodes during training. For this, it employs cross-modal links to connect video frames and text segments that relate to the same state and temporal edges to connect the present and future. The temporal edges work in both modalities, starting with a video frame, some text, or both, and connecting to a future (or past) state. MMCC accomplishes this by learning a latent representation shared by frames and text and generating predictions in that space.
The researchers use the concept of cycle consistency to learn the cross-modal and temporal edge functions without supervision. The development of cycle graphs, in which the model creates a series of edges from a starting node to other nodes and back, is referred to as cycle consistency. To do this, the model first assumes that frames and text with the same timestamps are counterparts but eventually relaxes this assumption. The model then predicts a future state, and the most similar node to this prediction is chosen. After this, the model reverses the preceding processes by forecasting the present state backward from the future node, connecting the future node to the start node.
The cycle-consistency loss is the difference between the model’s forecast of the present from the future and the actual present. According to researchers, the training goal needs the anticipated future to have sufficient knowledge about its history to be invertible. This results in forecasts corresponding to meaningful changes in the same entities (e.g., tomato becoming marinara sauce). Furthermore, the resulting prediction in either modality is meaningful, which is ensured by including cross-modal edges.
MMCC is trained using only long video sequences and randomly sampled starting conditions (a frame or text excerpt), asking the model to find temporal cycles. After training, MMCC can identify meaningful cycles that capture complex changes in the video.

The temporal and cross-modal edge functions were learned end-to-end using the soft attention technique. This approach first calculates the likelihood of each node being the edge’s target node and then “picks” a node by averaging all available choices. The cyclic graph constraint makes few assumptions about the types of temporal edges the model should learn, as long as they create a cyclic pattern. This allows the creation of long-term temporal dynamics that are important for future predictions to evolve without the need for manual labeling of significant changes.
Zero-Shot Applications:
To identify important transitions over time in a video, MMCC assigns a “likely transition score” to each pair (A, B) of frames in the movie based on the model’s predictions – the closer B is to our model’s forecast of A’s future, the higher the score. The highest-scoring pairings of present and future frames found in previously unseen videos are then ranked according to this score and shown. By establishing an ordering that maximizes the overall confidence ratings across all adjacent frames in the sorted sequence, this approach can also be used to temporally sort an unordered collection of video frames without any fine-tuning.
The researchers use the top-k recall metric to test the model’s ability to foresee action in advance. This metric assesses the model’s ability to recover the correct future (higher is better).

The results show that MMCC surpasses previous self-supervised state-of-the-art models in inferring possible future actions on CrossTask, a dataset of instruction videos with labels identifying essential phases.
Paper: https://arxiv.org/abs/2101.02337
Reference: https://ai.googleblog.com/2021/11/making-better-future-predictions-by.html
Suggested
Credit: Source link
Comments are closed.