Google AI Research Introduces Byte-Stream Sequence Models For Efficient Sequence Modeling For On-Device Machine Learning ML
Today, the demand for an on-device machine learning model interface has increased. Some important factors contributing to this increased demand include rising compute-intensive applications, the need to keep data on devices for privacy and security reasons, and more. On-device inference, however, poses various difficulties, from modeling to demand platform support.
Previous research integrates an innovative embedding generation method (called projection-based embeddings, or pQRNN) with effective architectures like QRNN and has shown its suitability for various classification challenges. By adding distillation methods, the end-to-end quality is improved even more. Yet, it could not be applied to larger and more complex vocabularies.
For on-device modeling, the token-free models introduced in ByT5 are an excellent place to start because they can handle pre-training and scalability difficulties without needing to grow the model. This is achievable because the vocabulary size for the embedding tables can be decreased from 30,000 to 256 using these approaches, as they consider text inputs as a stream of bytes. The transition from word-level representation to byte stream representation lengthens the sequences linearly. This may result in a large rise in processing costs and inference lag.
A new Google research introduces three new byte-stream sequence models for the SeqFlowLite library—ByteQRNN, ByteTransformer, and ByteFunnelTransformer—all of which may be pre-trained on unsupervised data and customized for particular tasks. These models use a fast character Transformer-based model that operates directly at the byte level using gradient-based subword tokenization (GBST) approach. Further, it employs a “soft” tokenization approach allowing learning token boundaries and short sequence lengths.
The researchers combine pQRNN with platform enhancements, including in-training quantization, to create an end-to-end model dubbed ByteQRNN. To feed the input string into a smaller embedding table with a vocabulary size of 259, they first utilize a ByteSplitter operation to split the input text into a byte stream.
The GBST layer has in-training quantization and combines byte-level representations with the effectiveness of subword tokenization while enabling end-to-end learning of latent subwords. This layer receives the output from the embedding layer. By counting and combining each subword block length with scores at each stridden token point, they “soft” tokenize the byte stream sequences. After this, they feed the tolerable sequence length of the downsampled byte stream to the encoder layer.
The researchers also suggest that the output of the GBST layer can be compressed to a shorter sequence length for efficient encoder computation or used by an encoder.
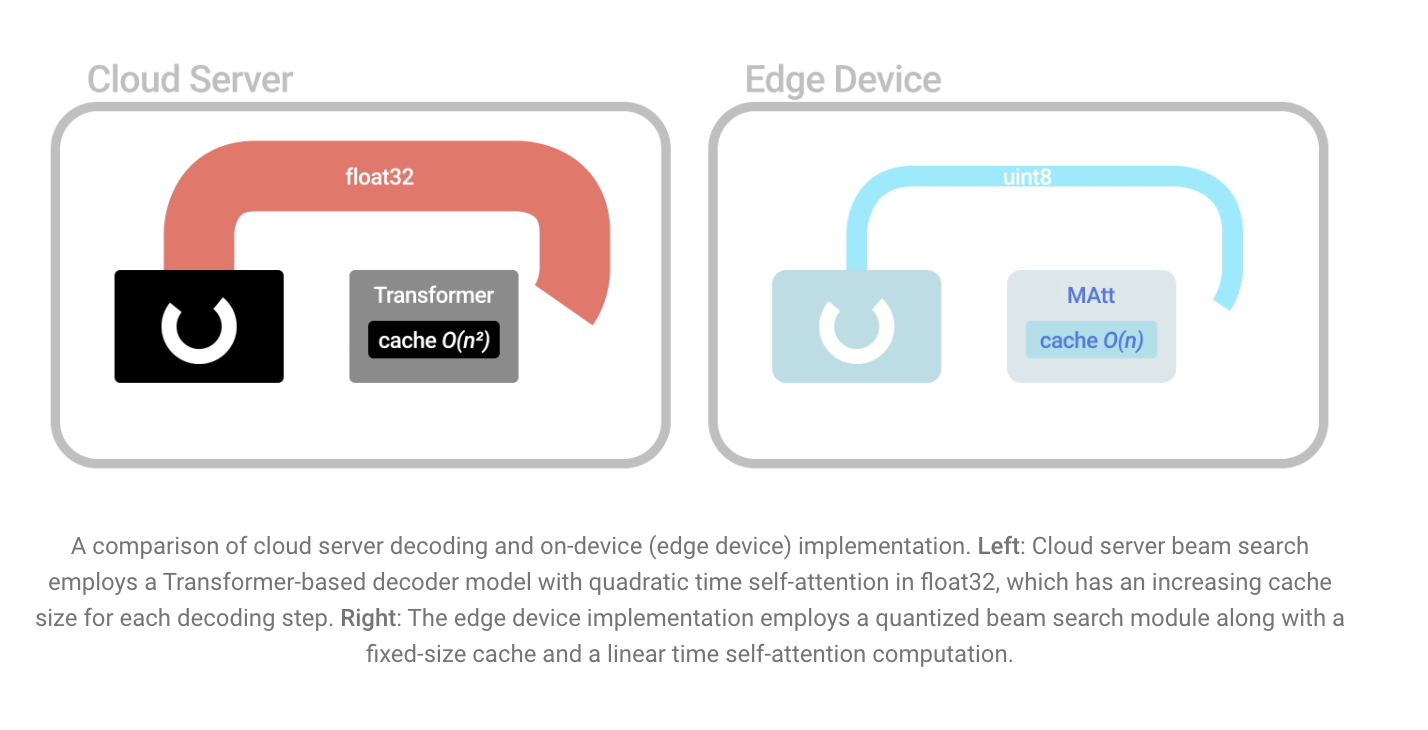
They take a step further to create an efficient sequence-to-sequence (seq2seq) model in addition to the input embeddings. They supplement ByteQRNN with a Transformer-based decoder model and a quantized beam search.
The end-to-end delay is decreased by the decoder Transformer model’s usage of a merged attention sublayer (MAtt) to transform the decoder self-complexity attention from quadratic to linear. MAtt uses a fixed-size cache for decoder self-attention for each decoding step instead of a standard transformer decoder’s growing cache size.
The team evaluates ByteQRNN’s performance using the area under the curve (AUC) measure on the civil comments dataset and contrasts it with pre-trained ByteQRNN and BERT. Their findings show that the refined ByteQRNN, despite being 300 times smaller, improves the overall quality and gets its performance closer to the BERT models.
The resulting models scale well to low-compute devices because SeqFlowLite models support in-training quantization, which lowers model sizes by one-fourth. To achieve the best results, they pre-trained both BERT and byte stream models using multilingual data sources relevant to the task.
This Article is written as a research summary article by Marktechpost Staff based on the Google AI research article. All Credit For This Research Goes To Researchers on This Project. Checkout the article and github link. Please Don't Forget To Join Our ML Subreddit
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.