Google AI Research Introduces GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
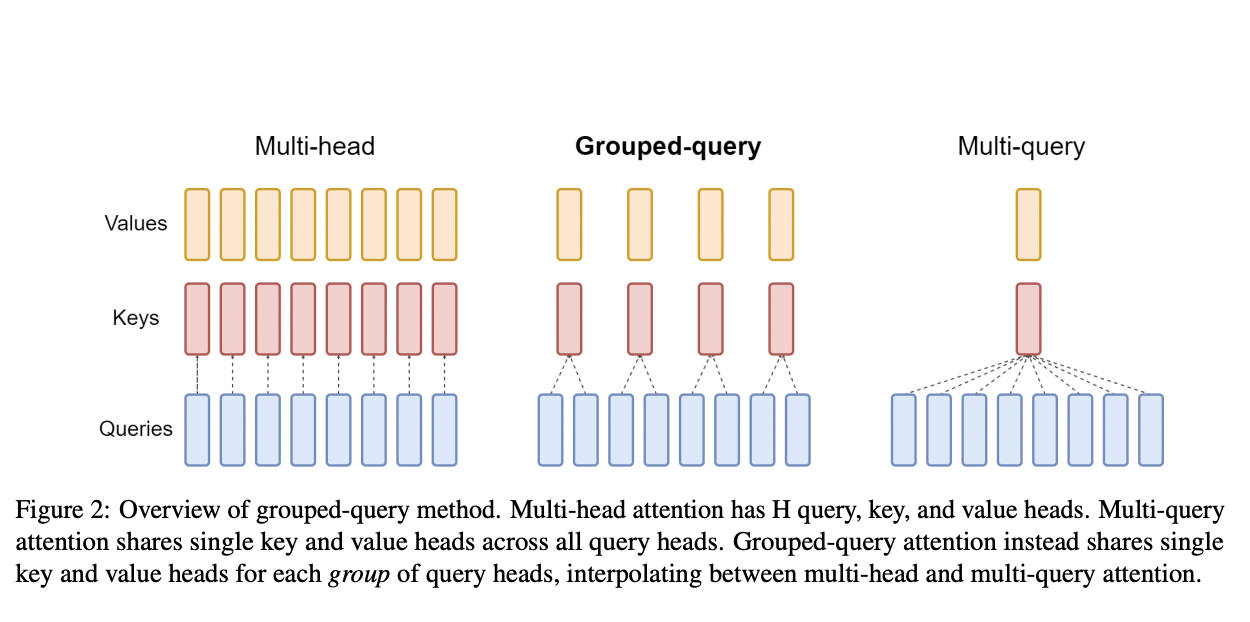
In the enchanting world of language models and attention mechanisms, picture a daring quest to accelerate decoder inference and enhance the prowess of large language models. Our tale unfolds with the discovery of multi-query attention (MQA), a captivating technique that promises speedier results. Multi-query attention (MQA) expedites decoder inference through the employment of a single key-value head.
However, its efficiency is countered by the potential for a decline in quality. Furthermore, there may be hesitation in training a separate model solely dedicated to hastening inference. Despite its benefits, the use of MQA is linked with drawbacks such as quality degradation and training instability. Moreover, the feasibility of developing distinct models optimized for both quality and inference is questioned due to potential limitations.
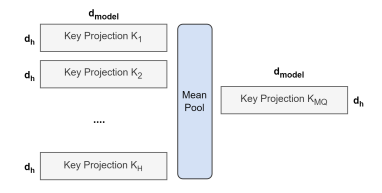
The above figure demonstrates the overview of conversion from multi-head to multi-query attention. Key and value projection matrices from all heads are mean pooled into a single head.
The paper introduces two contributions aimed at enhancing the efficiency of large language models during inference. Firstly, it demonstrates that language model checkpoints employing multi-head attention (MHA) can be uptrained, as outlined by Komatsuzaki et al. in 2022, to incorporate multi-query attention (MQA) with a minimal fraction of the original training compute. This approach offers a cost-effective means of obtaining both rapid multi-query functionality and high-quality MHA checkpoints.
Secondly, the paper suggests grouped-query attention (GQA) as an interpolation between multi-head and multi-query attention, utilizing single key and value heads for each subgroup of query heads. The research illustrates that uptrained GQA achieves quality levels close to multi-head attention while maintaining a speed comparable to that of multi-query attention.
Employing language models for swift responses becomes expensive due to the high memory demand for loading keys and values. Although multi-query attention addresses this issue by cutting down on memory usage, it does so at the cost of reducing the model size and accuracy. The proposed approach involves transforming multi-head attention models into multi-query models using only a fraction of the original training. Furthermore, the introduction of grouped-query attention, a combination of multi-query and multi-head attention, maintains quality comparable to multi-head attention while operating at a speed nearly as fast as multi-query attention.
In conclusion, the objective of this paper is to enhance the efficiency of language models in handling substantial amounts of information while minimising computer memory usage. This is particularly crucial when dealing with longer sequences, where assessing quality poses challenges. The evaluation for summarization involves using a metric called Rouge score, with an acknowledgment of its imperfect nature. Due to certain limitations in the testing methodology, the certainty of the correctness of our choices is not absolute.
Additionally, a direct comparison of our XXL GQA model with a counterpart trained from scratch was not conducted, preventing a clear understanding of its performance relative to starting anew. Lastly, the evaluations focused exclusively on models engaged in both reading and generating information. There are other popular models dedicated solely to information generation, and there is a belief that our GQA approach may prove more effective for them compared to an alternative technique known as MQA.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Janhavi Lande, is an Engineering Physics graduate from IIT Guwahati, class of 2023. She is an upcoming data scientist and has been working in the world of ml/ai research for the past two years. She is most fascinated by this ever changing world and its constant demand of humans to keep up with it. In her pastime she enjoys traveling, reading and writing poems.
Credit: Source link
Comments are closed.