Google AI Research Introduces Listwise Preference Optimization (LiPO) Framework: A Novel AI Approach for Aligning Language Models with Human Feedback
Aligning language models with human preferences is a cornerstone for their effective application across many real-world scenarios. With advancements in machine learning, the quest to refine these models for better alignment has led researchers to explore beyond traditional methods, diving into preference optimization. This field promises to harness human feedback more intuitively and effectively.
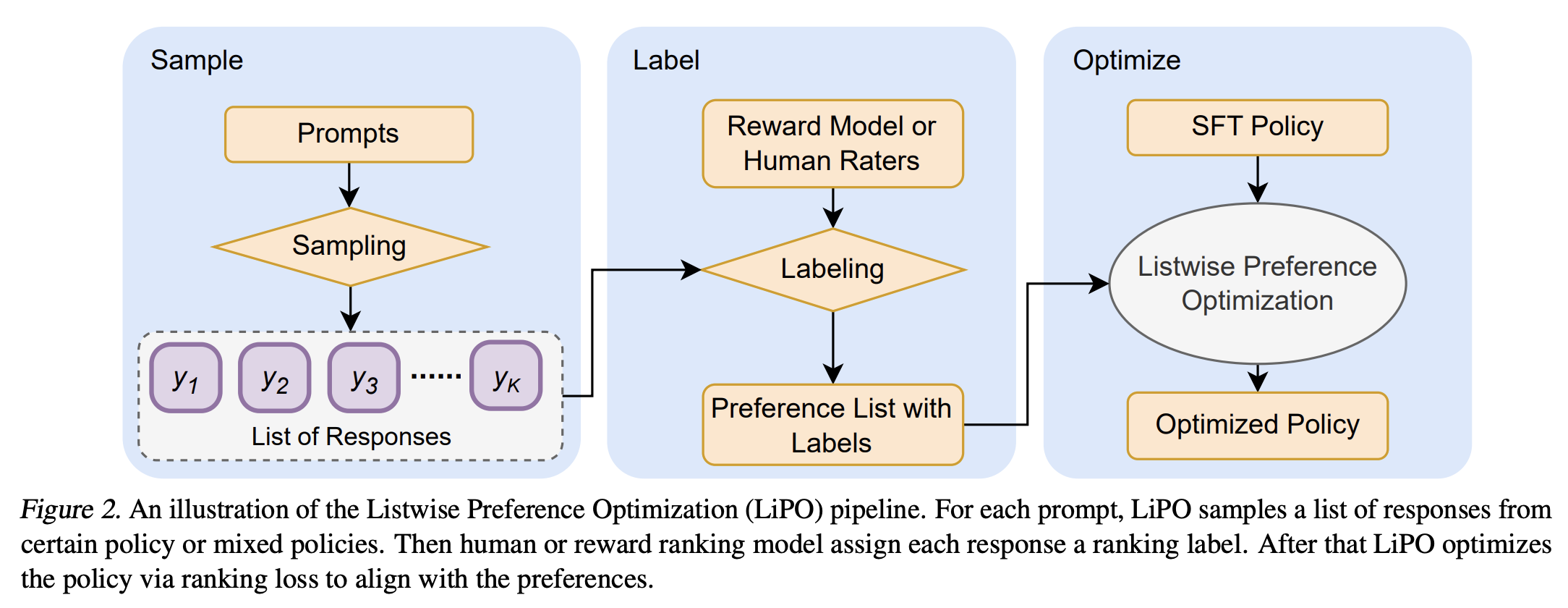
Recent developments have shifted from conventional reinforcement learning from human feedback (RLHF) towards innovative approaches like Direct Policy Optimization (DPO) and SLiC. These methods optimize language models based on pairwise human preference data, a technique that, while effective, only scratches the surface of potential optimization strategies. A groundbreaking study by Google Research and Google Deepmind researchers introduces the Listwise Preference Optimization (LiPO) framework, which reframes LM alignment as a listwise ranking challenge, paralleling the established Learning-to-Rank (LTR) domain. This innovative approach aligns with the rich tradition of LTR. It significantly expands the scope of preference optimization by leveraging listwise data – where responses are ranked in lists to economize the required evaluative efforts.
At the heart of LiPO lies the recognition of the untapped potential of listwise preference data. Traditionally, human preference data is processed pairwise, a method that, while functional, does not fully exploit the informational richness of ranked lists. LiPO transcends this limitation by proposing a framework that can more effectively learn from listwise preferences. Through an in-depth exploration of various ranking objectives within this framework, the study spotlights LiPO-λ, which employs a cutting-edge listwise ranking objective. Demonstrating superior performance over DPO and SLiC, LiPO-λ showcases the distinct advantage of listwise optimization in enhancing LM alignment with human preferences.
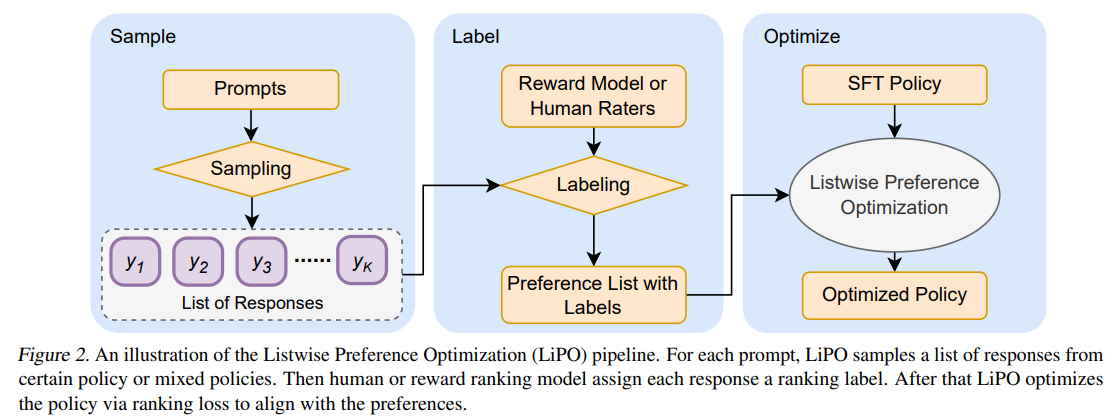
The core innovation of LiPO-λ lies in its sophisticated utilization of listwise data. By conducting a comprehensive study of ranking objectives under the LiPO framework, the research highlights the efficacy of listwise objectives, particularly those previously unexplored in LM preference optimization. It establishes LiPO-λ as a benchmark method in the field. This method’s superiority is evident across various evaluation tasks, setting a new standard for aligning LMs with human preferences.
Diving deeper into the methodology, the study rigorously evaluates the performance of different ranking losses unified under the LiPO framework through comparative analyses and ablation studies. These experiments underscore LiPO-λ’s remarkable ability to leverage listwise preference data, providing a more effective means of aligning LMs with human preferences. While existing pairwise methods benefit from including listwise data, LiPO-λ, with its inherently listwise approach, capitalizes on this data more robustly, laying a solid foundation for future advancements in LM training and alignment.
This comprehensive investigation extends beyond merely presenting a new framework; it bridges the gap between LM preference optimization and the well-established domain of Learning-to-Rank. By introducing the LiPO framework, the study offers a fresh perspective on aligning LMs with human preferences and highlights the untapped potential of listwise data. Introducing LiPO-λ as a potent tool for enhancing LM performance opens new avenues for research and innovation, promising significant implications for the future of language model training and alignment.

In conclusion, this work achieves several key milestones:
- It introduces the Listwise Preference Optimization framework, redefining the alignment of language models with human preferences as a listwise ranking challenge.
- It showcases the LiPO-λ method, a powerful tool for leveraging listwise data to enhance LM alignment and set new benchmarks in the field.
- It bridges LM preference optimization with the rich tradition of Learning-to-Rank, offering novel insights and methodologies that promise to shape the future of language model development.
The success of LiPO-λ not only underscores the efficacy of listwise approaches but also heralds a new era of research at the intersection of LM training and Learning-to-Rank methodologies. This study propels the field forward by leveraging the nuanced complexity of human feedback. It sets the stage for future explorations to unlock the full potential of language models in serving human communicative needs.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 37k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.