Google AI Research Propose A Self-Supervised Approach for Reversibility-Aware Reinforcement Learning

Reinforcement learning(RL) is a machine learning training method that rewards desired behaviors and punishes undesired ones. RL is a typical approach that finds application in many areas like robotics and chip design. In general, an RL agent can perceive and interpret its ecosystem.
RL is successful in unearthing methods to solve an issue from the ground up. However, it tends to struggle in training an agent to understand the repercussions and reversibility of its actions. It is vital to ensure the appropriate behavior of the agents in its environment that also increases the performance of RL agents on several challenging tasks. To make sure agents behave safely, they require a working knowledge of the physics of the ecosystem in which they are operating.
Google AI proposes a novel and feasible way to estimate the reversibility of agent activities in the setting of reinforcement learning. In this outlook, researchers use a method called Reversibility-Aware RL that adds a separate reversibility approximation component to RL’s self-supervised course of action. The agents can be trained either online or offline to guide the RL policy towards reversible behavior.
Working:
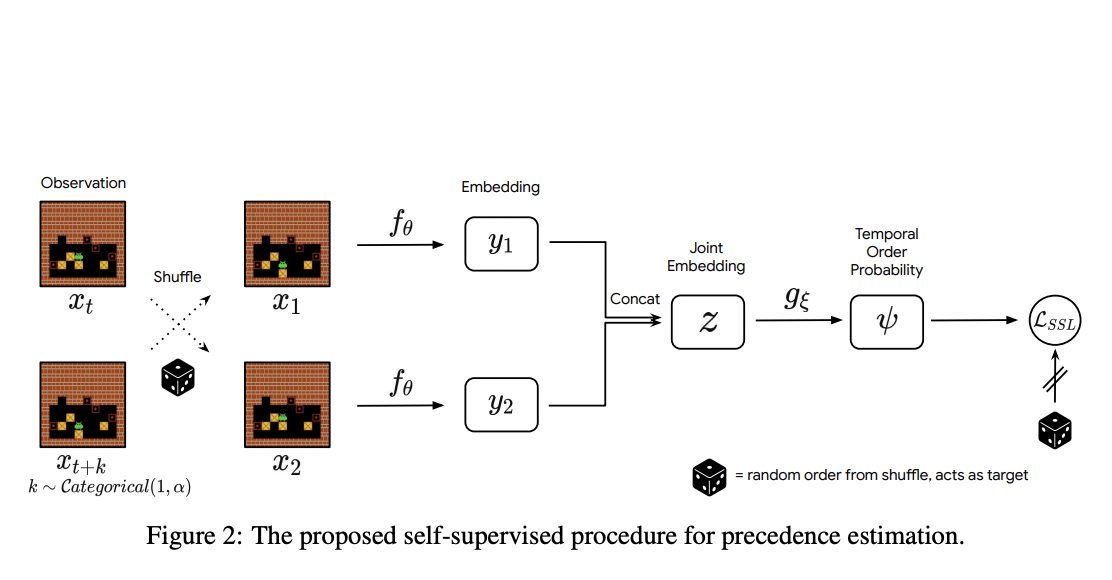
A theoretical explanation touches upon a concept called empirical reversibility, which measures the probability that an event A precedes another event B, knowing that A and B both occur. The reversibility component appended to the RL procedure learns from interactions and is a self-supervised model that can be trained without the dependency of the agent. Self-supervised essentially means that the model does not require data to be labeled with the reversibility of the actions.
In exercise, one sample pairs of events from a cluster of interactions, shuffles them, and trains the neural network to rebuild the original sequence of activities. The network’s performance is assessed and distilled by comparing its prognosis against the ground reality derived from the timestamps of the factual data. Certain events are temporally distant and can not be ordered. In that case, events are sampled in a temporal window of predetermined dimensions. A transition is deemed irreversible if the neural network’s confidence that event A happens before event B is higher than a chosen threshold. The prediction possibilities that we revive from this estimator are used as a stand-in for reversibility.

Incorporating reversibility into RL:
Two synchronous algorithms based on reversibility approximation are :
- Reversibility-Aware Exploration (RAE): An auxiliary reward function is created by analyzing consecutive observations. If a particular action picked up by an agent is deemed irreversible, it receives a reward corresponding to the environment’s reward minus a positive, fixed penalty. Although this approach does not exclude such actions, it does make them far-fetched.
- Reversibility-Aware Control (RAC): It is an action-conditioned counterpart of RAE that is more involved in the process. In this case, when the agent picks up an irreversible action, the action selection process is repeated until a reversible action is chosen.
In terms of applications, the researchers claim that RAE is more suitable for directed exploration, as it only encourages reversible behavior and avoids irreversible actions. RAC is preferred in safety-first, real-world scenarios, where irreversible behavior is to be banned altogether. Both algorithms can be used online or offline with minor changes, ensuring that the basic tailoring of the models remains true to its logic.
An evaluation of both the propounded models in various example scenarios:
- Avoiding (but not prohibiting) irreversible side-effects:
The base rule for a safe RL is to reduce irreversible interactions as a warning. A synthetic environment where an agent in an open field is tasked with reaching a goal is required to validate such proposals. The ecosystem shall remain uninterrupted if the agent follows the already established pathway. Otherwise, the environment will get disturbed; however, this would not result in a penalty.
- Safe interactions by prohibiting irreversibility:
The models were tested against the prototypical Cartpole task. It is found that combining RAC with any given RL agent will never fail, given that an appropriate threshold is selected for the probability that action is irreversible. Here, RAC overshadows RAE by providing safe, reversible interactions from the very first step in the environment.
- Avoiding deadlocks in Sokoban:
Sokoban is a video game in the genre ‘puzzle’. The player controls the crates and boxes in a warehouse, putting them in storage locations while avoiding irretrievable situations.
In a typical RL model, early iterations of the agent act in a near-random manner to inspect the ecosystem, which gets stuck very often. Such RL agents either fail to solve Sokoban puzzles or are pretty inefficient at it.
The IMPALA, a state-of-the-art model-free RL agent, was compared with an IMPALA+RAE agent’s performance in the Sokoban environment. It is found that the agent with the combined IMPALA+RAE policy is in a checkmate situation sporadically, which results in superior scores. In this task, it is nearly impossible to flag actions as irreversible as they can be reversed only if the agent takes a set of given additional steps.
The researchers look forward to implementing these ideas in large-scale and safety-critical applications in the future.
Paper: https://arxiv.org/abs/2106.04480
Google Blog: https://ai.googleblog.com/2021/11/self-supervised-reversibility-aware.html
Suggested
Credit: Source link
Comments are closed.