Google AI Research Proposes TRICE: A New Machine Learning Algorithm for Tuning LLMs to be Better at Solving Question-Answering Tasks Using Chain-of-Thought (CoT) Prompting
The team of researchers from Google developed a new fine-tuning strategy to address the challenge of generating correct answers using LLMs. The strategy, called chain-of-thought (CoT) fine-tuning, optimizes the average log-likelihood of correct answers and aims to maximize the marginal log-likelihood of generating accurate responses, ultimately improving the overall performance of LLMs.
The study references several related methods for rationale generation in neural sequence models. These include fully supervised and few-shot approaches. The self-consistent CoT technique, successful in quantitative reasoning tasks, is highlighted for marginalizing over rationales at test time. STaR, which involves imputation or averaging over causes during training, is discussed. Other relevant works include TRICE, Markovian score climbing, ReAct, Reflexion, and recent research on tool use within language models.
The research explores the effectiveness of CoT prompting in improving LLMs by instructing them to generate answers step by step. It proposes fine-tuning LLMs using CoT prompts to maximize the marginal log-likelihood of developing correct answers, addressing the challenge of sampling from the posterior over rationales. The study introduces a Markov-chain Monte Carlo expectation-maximization algorithm, drawing inspiration from various related methods. It demonstrates its superior performance compared to other fine-tuning techniques on held-out examples.
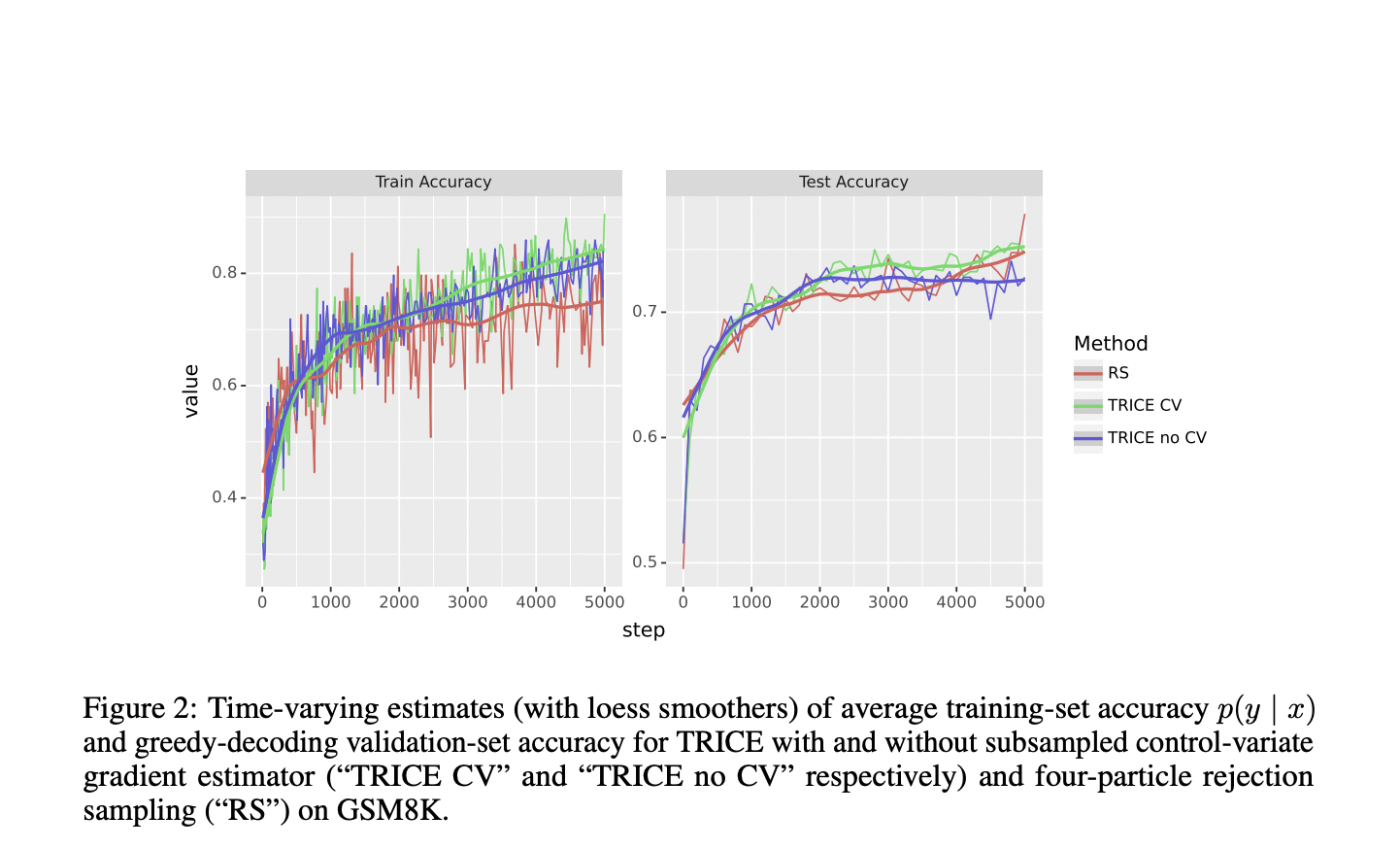
The approach incorporates a control-variate technique to reduce gradient estimate variance. Evaluation on GSM8K and BIG-Bench Hard tasks compares the proposed method to STaR and prompt-tuning with or without CoT. The methodology involves task-specific templates, prompts, and memory initialization settings, leveraging TRICE and STaR techniques and adopting rejection sampling, CoT prompt tuning, and direct prompt tuning with distinct initialization and optimization procedures.
The proposed MCMC-EM fine-tuning technique consistently outperforms other methods, including STaR and prompt-tuning with or without CoT, enhancing model accuracy on held-out examples. Evaluation of GSM8K and BIG-Bench Hard tasks demonstrates the technique’s effectiveness, offering a detailed summary of experimental results for each job in BIG-Bench Hard and providing comprehensive insights into the performance improvements achieved.
In conclusion, the research has presented a successful fine-tuning strategy for improving the accuracy of generating correct answers through CoT prompting. This technique has consistently outperformed other methods, resulting in better model accuracy on held-out examples, particularly in evaluating GSM8K and BIG-Bench Hard tasks. The proposed approach has also demonstrated the effectiveness of CoT prompts in training large language models for step-by-step problem-solving, ultimately leading to improved accuracy and interpretability. Additionally, the introduction of a control-variate technique has reduced gradient estimate variance. These findings highlight the potential for continued advancements in natural language processing and its application to problem-solving.
Future research directions include evaluating the MCMC-EM fine-tuning technique on diverse tasks and datasets to assess its generalizability. The exploration of treating tool use as a latent variable, akin to rationales in the study, may enhance language models in tool-use scenarios. Comparative studies with alternative methods like variational EM, reweighted wake-sleep, and rejection sampling could provide insights. Combining the MCMC-EM technique with other approaches may further boost performance and interpretability. Investigating the applicability of the control-variate technique in reducing gradient estimate variance across different training scenarios and domains is a valuable avenue for exploration.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.