Google AI Researchers Develop Code as Policies (CaP), a Robot-Centric Formulation of Language Model-Generated Programs Executed on Physical Systems
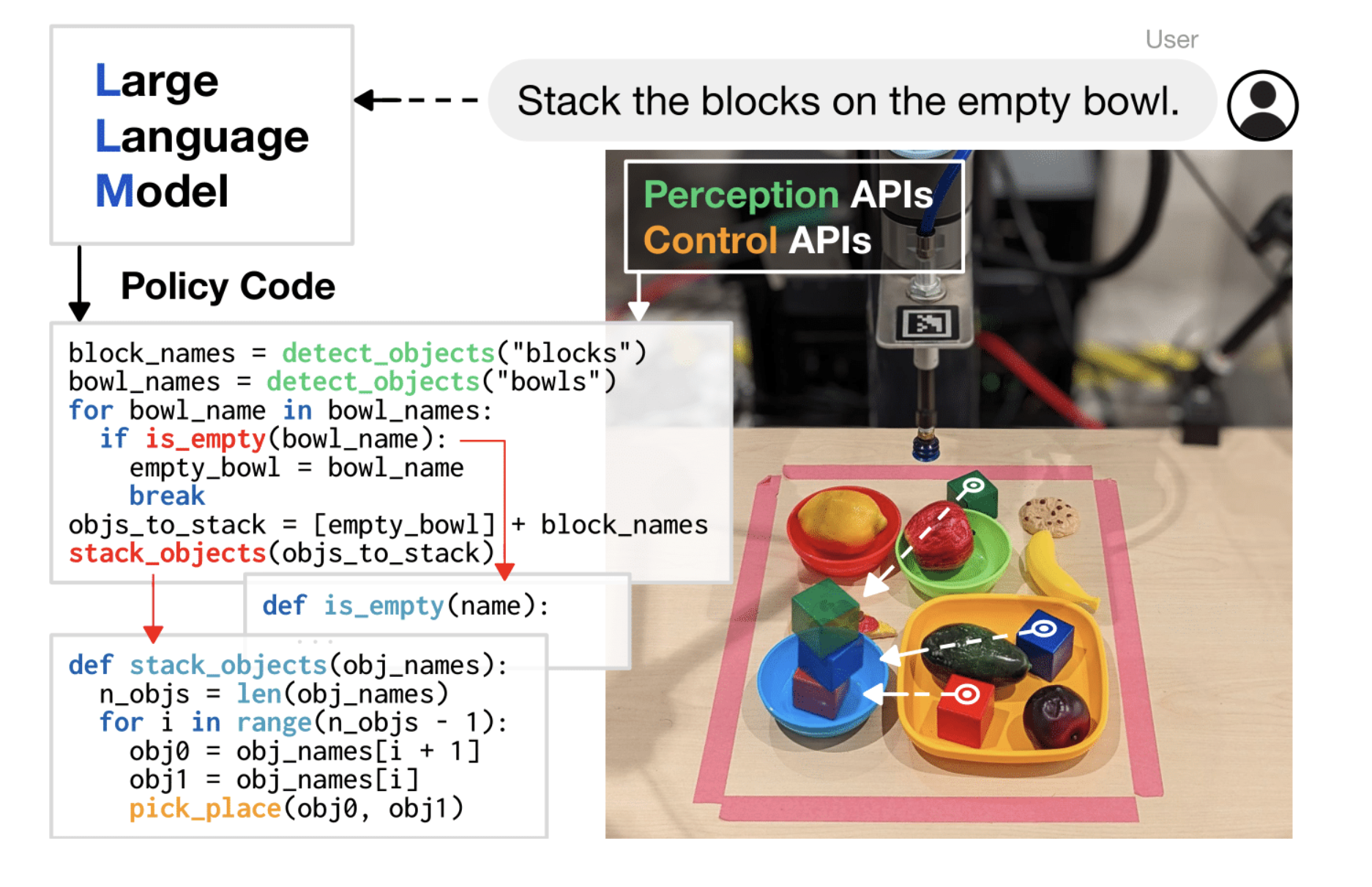
What if, in response to human commands, robots could develop their programming to interact with the outside world? It turns out that the most modern language models, like PaLM, are capable of complex reasoning because they have been trained on millions of lines of code. They demonstrate that current language models are effective at producing code that can control robot behavior in addition to ordinary code. When provided with numerous sample instructions and their accompanying code, language models may take in new instructions and automatically generate new code that reassembles API calls, creates new functions, and expresses feedback loops to create new behaviors at runtime.

Programming robots with code to identify objects, sequential orders to move actuators, and feedback loops to indicate how the robot should complete a task is a standard method for controlling them. Although these programs can be expressive, they can be time intensive and require domain knowledge to re-program policies for each new assignment.
To investigate this potential, Google researchers created Code as Policies (CaP), a robot-centric formulation of language model-generated programs run on physical systems. By allowing language models to execute progressively more difficult robotic tasks with the full expression of general-purpose Python code, CaP expands on their earlier work, PaLM-SayCan. With CaP, they advocate leveraging language models to prompt robots to create code directly. CaP enables a single system to carry out several sophisticated and varied robotic tasks without requiring task-specific training.
An Alternative Approach to Robot Generalization
CaP uses a code-writing language model to generate new code for new instructions when presented with hints and examples. Hierarchical code generation, which forces language models to recursively define new functions, build up their libraries over time, and self-architect a dynamic codebase, is the key component of this method. With a 39.8% pass@1 on HumanEval, a benchmark of hand-written coding problems used to measure the functional correctness of synthesized programs, and hierarchical code generation advances the state-of-the-art in both robotics and traditional code-gen benchmarks in natural language processing (NLP) subfields.
Various arithmetic operations and feedback loops based on language can be expressed in code-writing language models. Programs that employ the Pythonic language model can compose new behaviors at runtime using familiar logic constructs like sequences, selection (if/else), and loops (for/while). For spatial-geometric reasoning, they can also utilize third-party libraries to interpolate points (NumPy), analyze and create shapes (Shapely), etc. These models may transform precise quantities (such as velocities) to ambiguous descriptions (“faster” and “to the left”) depending on the context to elicit behavioral responses. They can also generalize to new instructions.
CaP inherits language model features that have nothing to do with writing code, like the ability to support instructions in languages other than English and emojis. This is compatible with systems with factorized perception and control, and it imparts some generalization without requiring the extensive data collection necessary for end-to-end robot learning.

Code-writing models express cross-embodied plans for robots with various morphologies that carry out the same task in multiple ways based on the accessible APIs (perception-action spaces). This research presents a brand-new open-source benchmark for language model evaluation on robotics-related code generation tasks. Larger models perform better overall across most metrics and that hierarchical code generation enhances the generalization of “productivity” the most.
Limitations
CaPs have trouble understanding commands that are much more complicated or operate at a higher level of abstraction. Since there are no instances of creating complicated 3D structures, it would be difficult for CaPs to, for example, “build a home with the blocks” in the tabletop domain. Their method assumes that all given commands are doable, and they cannot predict the utility of the created code in advance.
Open-Source Publication
On the project website, which includes other real-world demos with videos and produced code, they posted the code necessary to duplicate their tests and an interactive simulated robot demo.
Conclusion
Robots that can adapt their behavior and increase their skills as necessary will eventually use code as policies. This may be helpful, but the flexibility also introduces potential hazards because synthesized programs may cause unexpected behaviors with actual hardware if they are not carefully examined at runtime. With built-in safety checks that limit the control primitives the system can access, they can reduce these dangers, but more effort is required to guarantee that new combinations of well-known primitives are as secure. They encourage open discussion about reducing these dangers while increasing the favorable effects of more general-purpose robots.
This Article is written as a research summary article by Marktechpost Staff based on the research article 'Robots That Write Their Own Code'. All Credit For This Research Goes To Researchers on This Project. Check out the reference article and code.
Please Don't Forget To Join Our ML Subreddit
![]()
Ashish kumar is a consulting intern at MarktechPost. He is currently pursuing his Btech from the Indian Institute of technology(IIT),kanpur. He is passionate about exploring the new advancements in technologies and their real life application.
Credit: Source link
Comments are closed.