Google AI Researchers Introduce MADLAD-400: A 2.8T Token Web-Domain Dataset that Covers 419 Languages
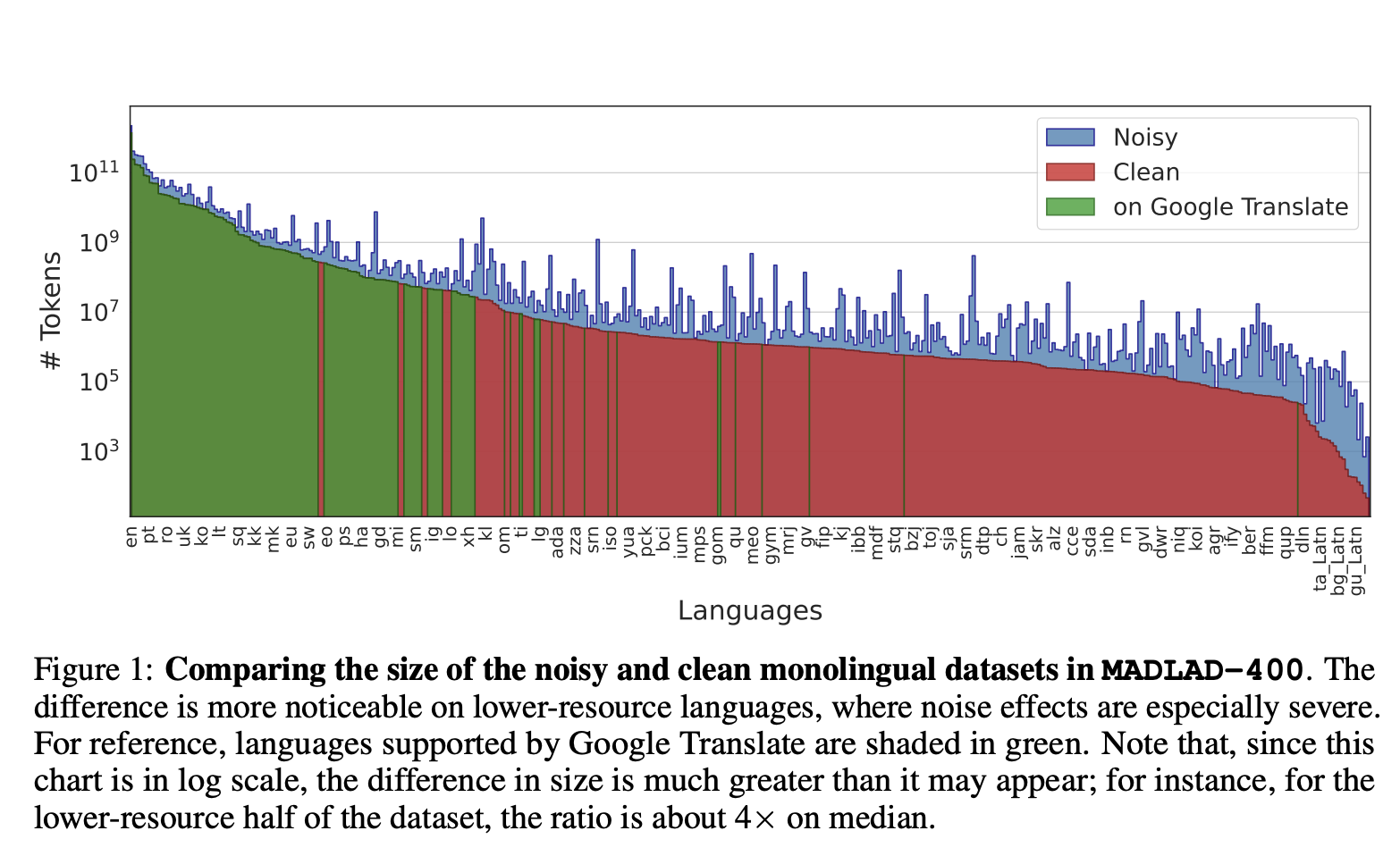
In the ever-evolving field of Natural Language Processing (NLP), the development of machine translation and language models has been primarily driven by the availability of vast training datasets in languages like English. However, a significant challenge for researchers and practitioners is the need for more diverse and high-quality training data for less commonly spoken languages. This limitation hampers the progress of NLP technologies for a wide range of linguistic communities worldwide. Recognizing this issue, a dedicated research team set out to create a solution, ultimately giving birth to MADLAD-400.
To understand the significance of MADLAD-400, we must first examine the current landscape of multilingual NLP datasets. Researchers have long relied on web-scraped data from many sources to train machine translation and language models. While this approach has yielded remarkable results for languages with abundant online content, it falls short when dealing with less common languages.
The research team behind MADLAD-400 recognized the limitations of this conventional approach. They understood that web-scraped data often comes with a host of challenges. Noise, inaccuracies, and content of variable quality are just a few issues that arise when relying on web data. Moreover, these problems are exacerbated when dealing with languages with limited digital presence.
In response to these challenges, the research team embarked on a mission to create a multilingual dataset that spans a wide range of languages and adheres to the highest standards of quality and ethical content. The result of their efforts is MADLAD-400, a dataset that promises to redefine how we train and develop NLP models for multilingual applications.

MADLAD-400 stands out as a testament to the dedication and meticulousness of the research team that crafted it. What sets this dataset apart is the rigorous auditing process it underwent. Unlike many multilingual datasets, MADLAD-400 did not rely solely on automated web scraping. Instead, it involved an extensive manual content audit in 419 languages.
The audit process was no small feat. It required the expertise of individuals proficient in various languages, as the research team carefully inspected and assessed data quality across linguistic boundaries. This hands-on approach ensured the dataset met the highest quality standards.
The researchers also documented their auditing process thoroughly. This transparency is invaluable for dataset users, providing insights into the steps taken to guarantee data quality. The documentation serves as a guide and a foundation for reproducibility, a key principle in scientific research.
In addition to manual audits, the research team developed filters and checks to enhance data quality further. They identified and addressed problematic content such as copyrighted material, hate speech, and personal information. This proactive approach to data cleaning minimizes the risk of undesirable content making its way into the dataset, ensuring that researchers can work confidently.
Furthermore, MADLAD-400 is a testament to the research team’s commitment to inclusivity. It encompasses a diverse array of languages, giving voice to linguistic communities that are often underrepresented in NLP research. MADLAD-400 opens the door to developing more inclusive and equitable NLP technologies by including languages beyond the mainstream.
While the creation and curation of MADLAD-400 are impressive achievements in their own right, the dataset’s true value lies in its practical applications. The research team conducted extensive experiments to showcase the effectiveness of MADLAD-400 in training large-scale machine translation models.
The results speak volumes. MADLAD-400 significantly improves translation quality across a wide range of languages, demonstrating its potential to advance the field of machine translation. This dataset provides a robust foundation for training models bridging language barriers and facilitating communication across linguistic divides.
Overall, MADLAD-400 stands as a pivotal achievement in multilingual natural language processing. With meticulous curation and a commitment to inclusivity, this dataset addresses pressing challenges and empowers researchers and practitioners to embrace linguistic diversity. It serves as a beacon of progress in the journey towards more equitable multilingual NLP, offering hope for a future where language technologies cater to a global audience.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Madhur Garg is a consulting intern at MarktechPost. He is currently pursuing his B.Tech in Civil and Environmental Engineering from the Indian Institute of Technology (IIT), Patna. He shares a strong passion for Machine Learning and enjoys exploring the latest advancements in technologies and their practical applications. With a keen interest in artificial intelligence and its diverse applications, Madhur is determined to contribute to the field of Data Science and leverage its potential impact in various industries.
Credit: Source link
Comments are closed.