Google AI Researchers Propose a Meta-Algorithm, Jump Start Reinforcement Learning, That Uses Prior Policies to Create a Learning Curriculum That Improves Performance
This research summary is based on the paper 'Jump-Start Reinforcement Learning' Please don't forget to join our ML Subreddit
In the field of artificial intelligence, reinforcement learning is a type of machine-learning strategy that rewards desirable behaviors while penalizing those which aren’t. An agent can perceive its surroundings and act accordingly through trial and error in general with this form or presence – it’s kind of like getting feedback on what works for you. However, learning rules from scratch in contexts with complex exploration problems is a big challenge in RL. Because the agent does not receive any intermediate incentives, it cannot determine how close it is to complete the goal. As a result, exploring the space at random becomes necessary until the door opens. Given the length of the task and the level of precision required, this is highly unlikely.
Exploring the state space randomly with preliminary information should be avoided while performing this activity. This prior knowledge aids the agent in determining which states of the environment are desirable and should be investigated further. Offline data collected by human demonstrations, programmed policies, or other RL agents could be used to train a policy and then initiate a new RL policy. This would include copying the pre-trained policy’s neural network to the new RL policy in the scenario where we utilize neural networks to describe the procedures. This process transforms the new RL policy into a pre-trained one. However, as seen below, naively initializing a new RL policy like this frequently fails, especially for value-based RL approaches.
Google AI researchers have developed a meta-algorithm to leverage pre-existing policy to initialize any RL algorithm. The researchers utilize two procedures to learn tasks in Jump-Start Reinforcement Learning (JSRL): a guide policy and an exploration policy. The exploration policy is an RL policy trained online using the agent’s new experiences in the environment. In contrast, the guide policy is any pre-existing policy that is not modified during online training. JSRL produces a learning curriculum by incorporating the guide policy, followed by the self-improving exploration policy, yielding results comparable to or better than competitive IL+RL approaches.

How did the researchers approach the problem?
The guide policy can take any form:
- A scripted policy, a policy trained with RL
- A live human demonstrator.
The sole conditions are that the guide policy is fair and capable of selecting actions based on environmental observations. In an ideal world, the guide policy would achieve bad or mediocre ecological performance, but it would not be able to improve further with fine-tuning. JSRL can then use the progress of this guide policy to improve performance even further.
The guide policy is rolled out for a set number of steps at the start of training to get the agent closer to goal states. After that, the exploration policy takes over and continues to act in the environment to achieve these objectives. The number of steps done by the guide policy is steadily lowered as the exploration-performance policy increases until the exploration policy takes over altogether. This procedure generates a curriculum of starting states for the exploration policy so that each curriculum stage merely requires learning to achieve the initial conditions of previous curriculum stages.
How does it compare against IL+RL guidelines?
Because JSRL can employ a previously established policy to initialize RL, it’s a natural comparison to imitation and reinforcement learning (IL+RL) methods, which train on offline datasets before fine-tuning the pre-trained policies with a new online experience. On the D4RL benchmark tasks, JSRL compares to competitive IL+RL approaches. Simulated robotic control environments and collections containing offline data from human demonstrations, planners, and other learned policies are among the duties.
An offline dataset is learned and fine-tuned in online mode for each experiment. It’s also compared to algorithms like AWAC, IQL, CQL, and behavioral cloning, created particularly for each environment. While JSRL can be used in conjunction with any initial guide policy or fine-tuning method, IQL is employed as a pre-trained guide for fine-tuning. Each transition is a format (S, A, R, S’) sequence that defines the state the agent began in (S), the action the agent performed (A), the reward the agent earned (R), and the state the agent ended up in (S’) after completing action A. With as low as ten thousand offline transitions, JSRL appears to function well.
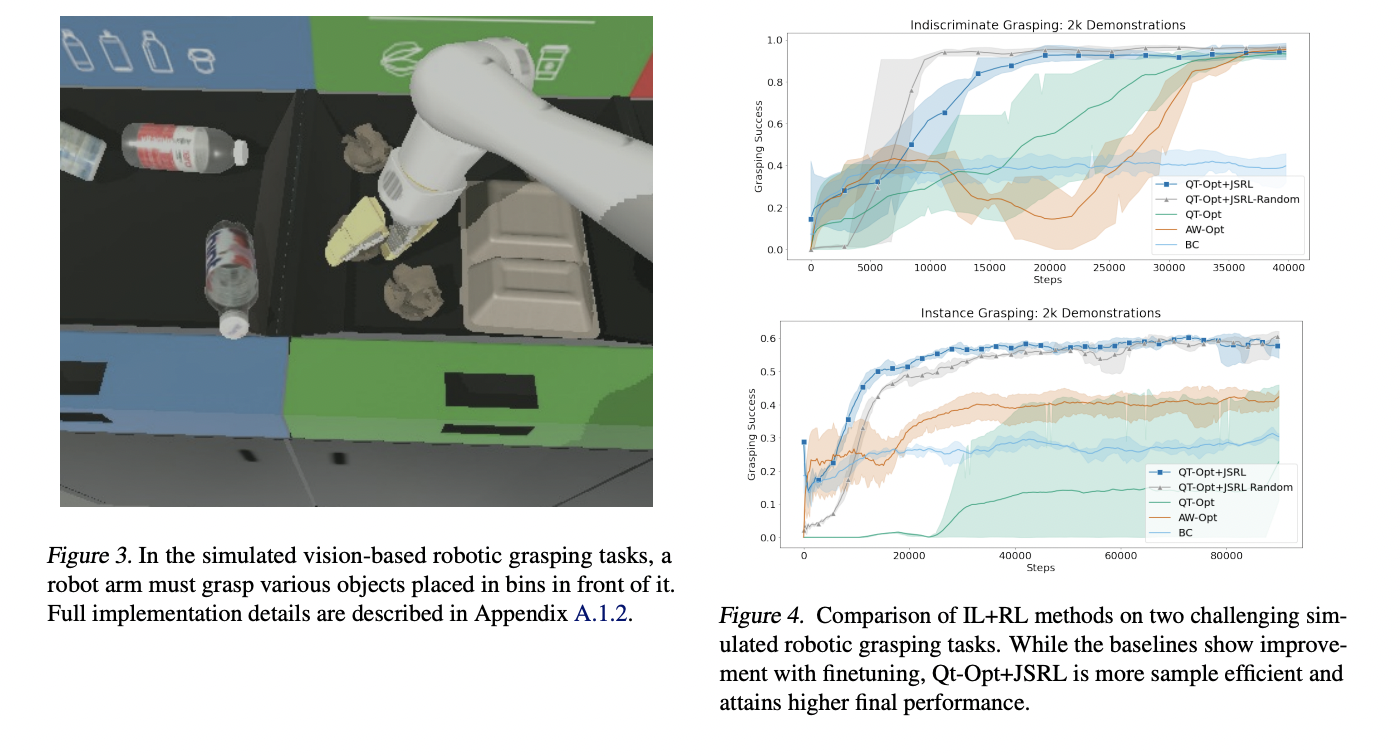
Robotic Tasks based on Vision:
Due to the curse of dimensionality, using offline data in complicated tasks like vision-based robotic manipulation is challenging. In terms of the amount of data necessary to learn good policies, the large dimensionality of both the continuous-control action space and the pixel-based state-space presents scaling issues for IL+RL approaches. To compare it to the JSRL tasks, the researchers focus on two challenging simulated robotic manipulation tasks: indiscriminate grasping (i.e., lifting any object) and instance grasping (i.e., lifting a specific target object). The QT-Opt+JSRL combination improves faster than any other strategy while having the highest success rate.
The researchers’ algorithm generates a learning curriculum by incorporating a pre-existing guide policy, followed by a self-improving exploration policy. Since it starts exploring from states closer to the goal, the exploration policy’s task is substantially simplified. The effect of the guide policy reduces as the exploration policy develops, resulting in a competent RL policy. The team hopes to use JSRL to problems like Sim2Real in the future and to see how they can use various guide policies to teach RL agents.
Paper: https://arxiv.org/pdf/2204.02372.pdf
Project: https://jumpstart-rl.github.io/
Reference: https://ai.googleblog.com/2022/04/efficiently-initializing-reinforcement.html
For Advertisement or Content Creation Service, Please Contact Us at [email protected] or check out our ad page here
Suggested
Credit: Source link
Comments are closed.