Google AI Researchers Propose a Method for Highly Efficient and Stable Training of a 22B-Parameter ViT (ViT-22B)
Transferring pre-trained vision backbones has enhanced performance on various vision tasks, much like natural language processing. Larger datasets, scalable infrastructures, and innovative training techniques have boosted its rise. Despite this, language models have significantly outperformed vision models in terms of emergent capabilities at large scales. The highest dense language model has 540B parameters, the largest dense vision model has just 4B parameters, and a moderately parameterized model for an entry-level competitive language model often comprises over 10B parameters.
Language models have more than a trillion parameters, yet the biggest recorded sparse vision models only have 15B. Sparse models show the same tendency. The biggest dense ViT model to date, ViT-22B, is presented in this work. They identify pathological training instabilities that impede scaling the default recipe to 22B parameters and show architectural improvements that enable it. Moreover, they carefully design the model to provide model-parallel training with hitherto unheard-of efficiency. A thorough assessment suite of tasks, spanning from classification to dense output tasks, is used to determine if ViT-22B meets or exceeds the existing state-of-the-art.
With 22 billion parameters, ViT-22B is the biggest vision transformer model available. For instance, ViT-22B obtains an accuracy of 89.5% on ImageNet even when utilized as a frozen visual feature extractor. It achieves 85.9% accuracy on ImageNet in the zero-shot situation using a text tower trained to match these visual attributes. The model is also an excellent instructor; using it as a distillation objective, they educate a ViT-B student who scores an industry-leading 88.6% on ImageNet. Improvements in dependability, uncertainty estimates, and fairness tradeoffs accompany this performance. Lastly, the model’s properties more closely match how people see things, yielding a previously unheard-of form bias of 87%.
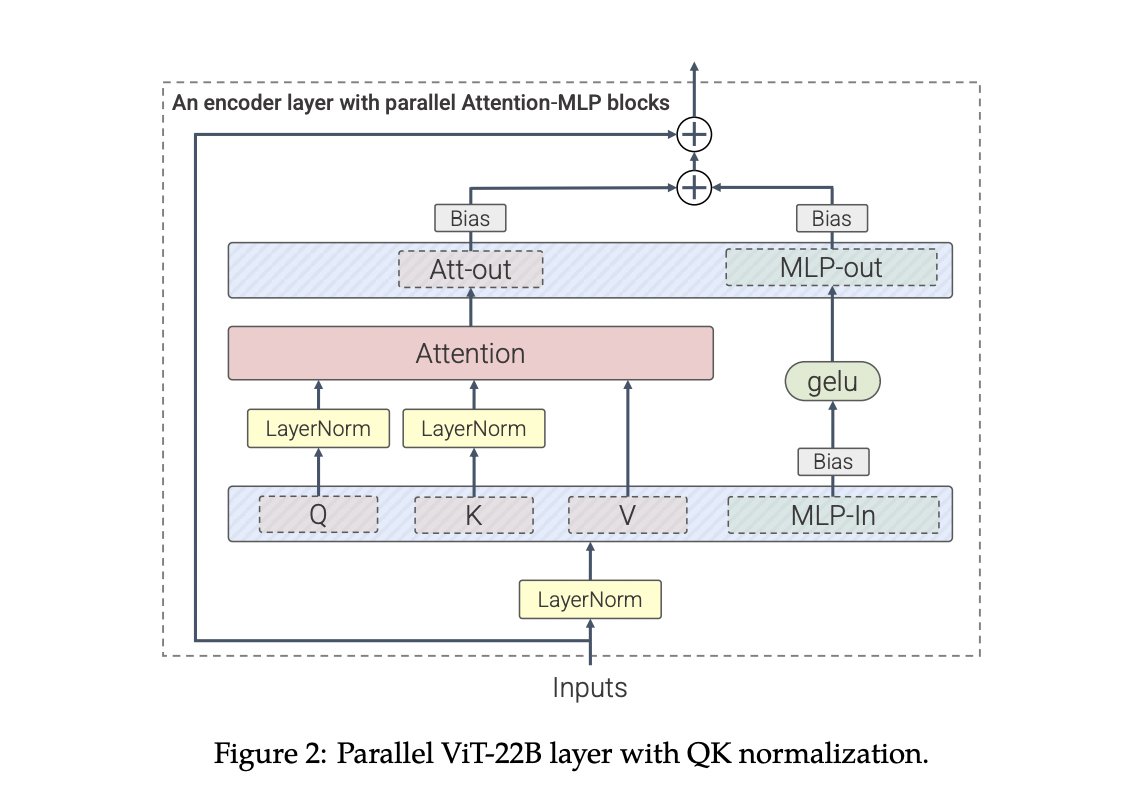
ViT-22B is a Transformer-based encoder model with parallel layers, query/key (QK) normalization, and omitted biases to increase efficiency and training stability at scale. Its architecture is similar to that of the original Vision Transformer.
Overlapping layers. Instead of sequentially applying the Attention and MLP blocks as in the traditional Transformer, ViT-22B does it in parallel. The linear projections from the MLP and attention blocks allow for different parallelization.
Normalization of QK. After a few thousand steps, they saw diverging training loss while growing ViT beyond earlier efforts. Particularly, models with about 8B parameters showed similar instability. It was brought on by abnormally high attention logit values, which produced attention weights that were practically one-hot and had almost no entropy. They use the method of applying LayerNorm on the queries and keys before the computation of the dot-product attention to address this and exclude biases from LayerNorms and QKV projections. After PaLM, all LayerNorms were applied without bias or centering, and the bias terms from the QKV projections were eliminated.
They demonstrate how the original design may be improved to achieve high hardware usage and training stability, producing a model that outperforms the SOTA on several benchmarks. In particular, excellent performance may be obtained by creating embeddings with the frozen model, then training thin layers on top of those embeddings. Their analyses further demonstrate that ViT-22B outperforms previous models in fairness and robustness and is more similar to people in terms of shape and texture bias. The code and dataset are yet to be released.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 14k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.