Google AI Researchers Propose A Structure-Aware Sequence Model, Called FormNet, To Mitigate The Sub-Optimal Serialization Of Forms For Document Information Extraction
This Article Is Based On The Research Paper 'FormNet: Structural Encoding beyond Sequential Modeling in Form Document Information Extraction' and Google article. All Credit For This Research Goes To The Researchers Of This Paper 👏👏👏 Please Don't Forget To Join Our ML Subreddit
Using sequence modeling, researchers have attained improved state-of-the-art performance on natural language and document processing tasks. Sequence models are machine learning self-attention models that input or output data sequences dependent on past input/output. To parse form-related documents, the prevalent practice is to serialize them first (typically from left to right, top to bottom) and then apply state-of-the-art sequence models to them. On the other hand, Standard serialization solutions suffer from the varying complexity of sophisticated form layouts, which frequently include tables, columns, boxes, and other elements. These particular issues in form-based document interpretation have largely gone neglected, despite their practical significance.
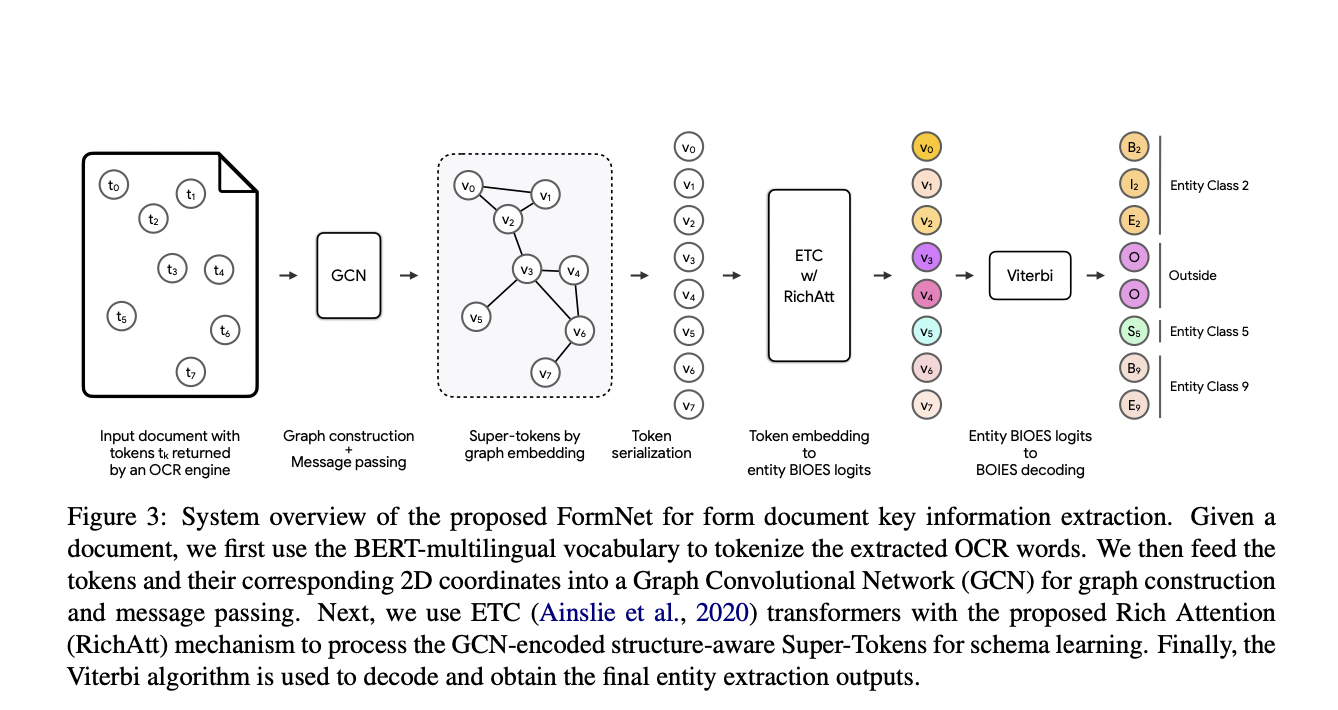
To make advancements in this field, a team of researchers from the Cloud AI team of Google Research wrote a research paper, “FormNet: Structural Encoding Beyond Sequential Modeling in Form Document Information Extraction, ” presented in ACL 2022. FormNet is a structure-aware sequence model that bridges the gap between plain sequence models and 2D convolutional models to reduce improper form serialization. The model architecture begins with a ‘Rich Attention’ mechanism, which uses the spatial relationships between tokens to calculate a more structurally relevant attention score. Then, using graph convolutional networks (GCN), ‘Super-Tokens’ are created by consolidating important information using embeddings from neighboring tokens. Relevant knowledge about how tokens are spatially related to each other in forms is extracted using these graphs. These Super-Tokens are then fed into a transformer model, which performs successive entity tagging and extraction.
The team also carried out a series of experiments using FormNet for document information retrieval. We first employ the BERT-multilingual vocabulary and optical character recognition (OCR) engine to detect and tokenize words in a form document. The tokens and 2D coordinates are then fed into a GCN for graph creation and message transmission. To continue processing the GCN-encoded structure-aware tokens for semantic entity extraction, we use Extended Transformer Construction (ETC) layers with the suggested Rich Attention technique. Finally, we decode and retrieve the final entities for output using the Viterbi method, which finds a sequence that maximizes the posterior probability.

The researchers concluded that FormNet outperforms prior methods despite employing smaller model sizes, less pre-training data, and eliminating the use of visual features through a series of studies. It also achieves state-of-the-art performance on CORD, FUNSD, and Payment benchmarks. Thus, despite substandard serialization, the ETC transformer excels in form understanding thanks to a new Rich Attention method and Super-Token components proposed by the team.
Source: https://ai.googleblog.com/2022/04/formnet-beyond-sequential-modeling-for.html
Paper: https://arxiv.org/pdf/2203.08411.pdf
Reference: https://analyticsindiamag.com/google-releases-formnet-works-on-improving-how-text-is-read-in-forms/
Credit: Source link
Comments are closed.