Google AI Researchers Propose ‘CMT-DeepLab’: A Transformer-Based Machine Learning Framework For Panoptic Segmentation Designed Around Clustering
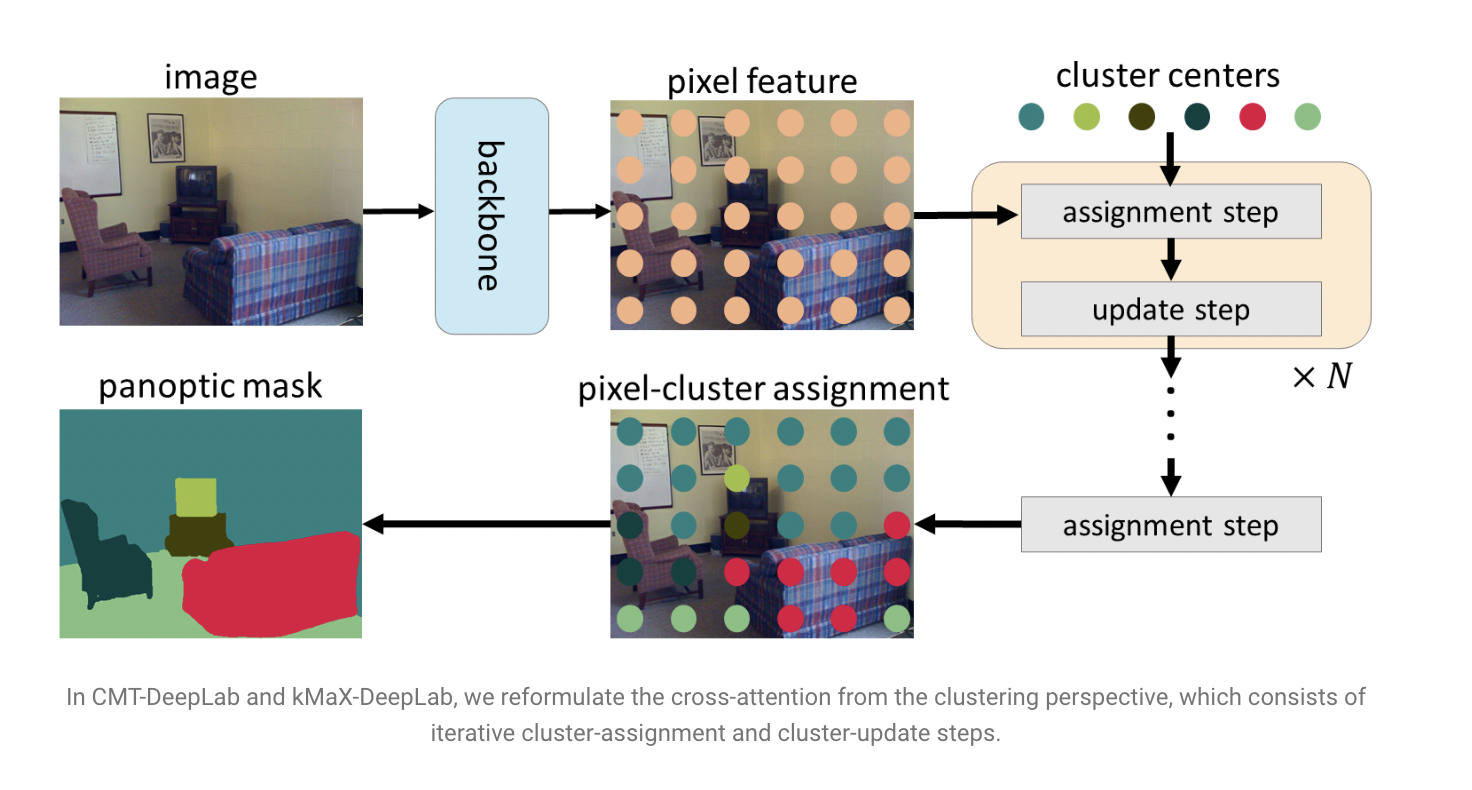
Panoptic(Pan = All and Optic = Vision) segmentation is the technique in Computer Vision that separates each object in the image into individual parts. After that, these parts are labeled in different colors and then classified. Still, the difference between Panoptic and other segmentation techniques is that it’s viewed as the global or unified view of segmentation rather than using two different approaches. Only one is enough. CMT-Deeplab is a framework built by Research Scientists at Google Research to ease the process of building a Panoptic Segmentation model by shifting the approach from proxy-based systems to end-to-end systems, which enhances all of its functions through the use of transformer encoders. The Core idea behind this is to take in the input and predict every object in the image and then create a binary mask prediction using these objects and mask embedding vectors(to develop high-definition images).
Transformers are a novel architecture that solves sequence to sequence tasks while handling long-range dependencies. Transformers are used standalone or combined with CNN(Convolutional Neural Networks), significantly boosting computer vision tasks. Proxy Based Panoptic Segmentation – To achieve a total output, it uses two neural networks, FCN(Fully Convolutional Network) and Mask R-CNN but yielded inaccurate and inconsistent results. Still, with the introduction of a mask transformer, it can produce results more accurately and reliably. End-To-End Panoptic segmentation- Results are created by combining Instance(combination of Box detection and Box-based segmentation) and Semantic segmentation.
The first step starts with the pixel encoder that extracts the features of the image then the parts are sent to the pixel decoder which due to the inclusion of Transformers enhances the pixels and through the use of upsampling layers it creates high resolution objects,the problem arouses because the transformer architecture is built for object detection and not for object segmentation and to overcome the shortcomings of the transformer type architecture we turn to clustering by doing softmax operations in different dimensions with the goal of clustering the most similar object queries together the softmax operations are applied to the image spatial dimension,to obtain the final output softmax is performed on the thing queries to ensure that each pixel finds the most similar pixel to each other although there are some issues with this approach as well with one being that the object queries are sparsely updated because of the softmax updated to a very large dimension,second the output update can only be updated once therefore the pixels have only one chance to update the information.for this, the equations for transformer-based Panoptic segmentation had to be modified to fit the Clustering situation. The equation below solves our problems by updating the cluster features by pooling pixel features according to the cluster assignment (C are the cluster centers), which improves the framework’s performance significantly.
Z T × F = (softmaxN (F × CT))T × F.
We now try to modify the transformer decoder to solve our issues through a new clustering-based approach through methods like Residual path between Cluster assignments where we stack the transformer decoder on top of each other, and then we add a residual connection between clustering results. We solve the first problem of Sparse query update by combining the proposed cluster center update with the original cross attention. We solve the second problem by utilizing the clustering result to perform an update on the pixel features using the features of the cluster center.
In conclusion, the CMT-Deeplab framework improves the panoptic segmentation significantly while also lowering its complex process because of end-to-end based systems, which helps in increasing the quality of prediction through mask transformers and redefining the object queries and incorporates the cluster center update, which significantly can’t enrich the learned cross-attention maps and further facilitates the segmentation prediction.
This Article is written as a summary article by Marktechpost Staff based on the research paper 'CMT-DeepLab: Clustering Mask Transformers for Panoptic Segmentation'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper and reference article. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.