Google AI Researchers Propose SAVi++: An Object-Centric Video Model Trained To Predict Depth Signals From A Slot-Based Video Representation
The complexity of the natural world, which is made up of different entities, results from the combined, largely autonomous actions of the entities. To forecast the future of the world and influence certain outcomes, one must understand this compositional structure.
Objects interact when they are near together, have Spatio-temporal coherence, and have persistent, latent traits that guide their behavior over long epochs. In machine learning, object-centric representations have the potential to significantly enhance sampling efficiency, robustness, visual reasoning, and interpretability of learning algorithms, just as they are essential for human understanding. Learning about repeating objects, such as vehicles, traffic signals, and pedestrians, as well as the laws governing their interactions, is necessary for generalization across contexts.
Human brains do not naturally possess the ability to group edges and surfaces into unitary, bounded, and persistent object representations; rather, this ability is learned by experience beginning in infancy. Such an inductive bias in deep learning has been proposed in slot-based architectures, which divide object information into non-overlapping but interchangeable pools of neurons. The resulting representational modularity can help with prediction and causal inference for tasks that come after.
Finding the compositional structure of real-world dynamic visual situations in an unsupervised manner has been a major difficulty in computer vision. The first concentration was on single-frame, synthetic RGB images, but it was difficult to expand this work to video and more complicated scenarios. The understanding that a color-intensity pixel array is not the only readily available source of visual information, at least not to human perceptual systems, was a crucial realization for further advancement.
Recent innovations use optical flow as a prediction target to create object-centric representations of dynamic environments that include intricate 3D scanned items and realistic backdrops. To learn how to distinguish between background and static objects, motion prediction alone is insufficient. Additionally, cameras themselves are sensitive to movement in real-world application domains like self-driving automobiles, which significantly affects frame-to-frame motion as a prediction signal in non-trivial ways.
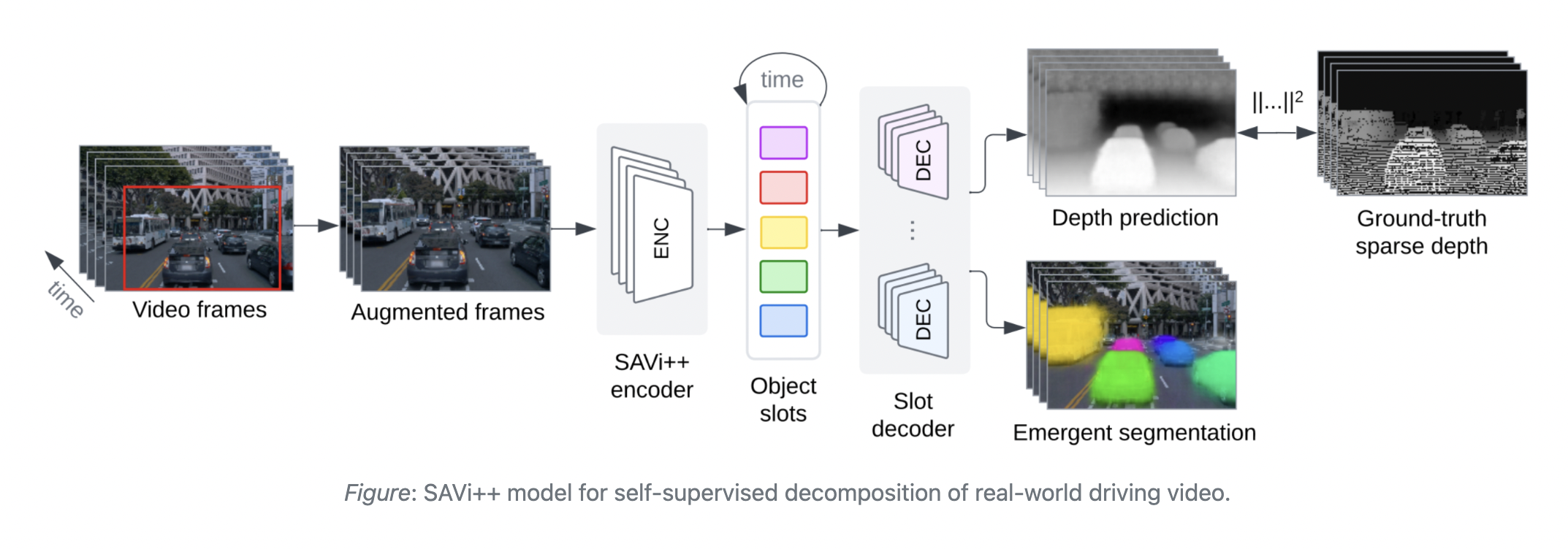
An improved slot-based video model, known as SAVi++, was recently presented by Google researchers. SAVi++ takes advantage of depth information that is easily accessible via RGB-D cameras and LiDAR sensors to get qualitative improvements in object-centric representations. Without employing direct segmentation or tracking supervision, SAVi++ is the first slot-based, end-to-end trained model that successfully separates complicated objects in naturalistic, real-world video sequences.
Researchers discovered that SAVi++ was able to handle films with complex forms and backdrops, as well as a large number of objects per scene, on the multi-object video (MOVi) benchmark, which contains synthetic videos of high visual and dynamic complexity. The method improved on SAVi by allowing for both stationary and moving cameras as well as both static and dynamic objects. In real-world driving videos from the Waymo Open dataset, researchers showed that SAVi++, trained with sparse depth signals collected from LiDAR, enables emergent object deconstruction and tracking.
Conclusion
In a recent study, Google researchers showed that object tracking and segmentation could be produced using depth signals, which provide information on scene geometry in large-scale video data. To find a straightforward yet effective set of changes to an existing state-of-the-art object-centric video model (SAVi), the team used a series of synthetic multi-object video benchmarks with increasing complexity. This allowed them to bridge the gap between simple synthetic driving videos and complex real-world driving videos. The research represents a first step toward developing complete trainable systems that can learn to see the environment in an object-centric, deconstructed manner without requiring close human supervision. This finding shows that object-centric deep neural networks are not fundamentally restricted to straightforward synthetic environments, despite the fact that there are still numerous unresolved issues.
This Article is written as a summary article by Marktechpost Staff based on the paper 'SAVi++: Towards End-to-End Object-Centric Learning from Real-World Videos'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper, project. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.