Google AI Researchers Propose the Pathways Autoregressive Text-to-Image (Parti) Model, Which Generates High-Fidelity Photorealistic Images and Supports Content-Rich Synthesis

Human brains can develop complex scenarios based on descriptions, be it verbal or written. Replicating this to produce visuals based on such descriptions can open up creative applications in multiple fields, be it the arts, design, or multimedia content development. Recent text-to-image creation research, such as DALL-E and CogView, has made significant progress in producing high-fidelity pictures. It also has proved its worth in displaying generalization capabilities to previously unexplored pairings of objects and concepts. Both approach the problem as language modeling, converting textual descriptions into visual words. After this, they employ current sequence-to-sequence structures such as Transformers to understand the link between language inputs and visual outputs.
Visual tokenization effectively combines the perspective of text and pictures, allowing them to be handled as sequences of discrete tokens and hence susceptible to sequence-to-sequence models. For that purpose, DALL-E and CogView learned from a vast collection of potentially noisy text-image pairings using decoder-only language models, similar to GPT. Make-A-Scene extends this two-stage modeling method to accommodate text and scene-guided picture production.
Considerable past work on scaling big language models and developments in discretizing pictures and audio has been done. These models forego the use of discrete picture tokens in favor of diffusion models that create images directly. Compared to earlier work, these models enhance zero-shot Fréchet Inception Distance (FID) scores on MS-COCO and create pictures with significantly improved quality and aesthetic appeal. Now inputs in other modalities may be handled as language-like tokens, and autoregressive models for text-to-image creation remain tempting. The Pathways Autoregressive Text-to-Image (Parti) model is presented in this study. This model creates high-quality pictures from text descriptions, including photo-realistic images, paintings, sketches, and more. Researchers show that scaling autoregressive models with a ViT-VQGAN image tokenizer is an excellent technique for improving text-to-image creation. These models effectively incorporate and graphically represent world information.
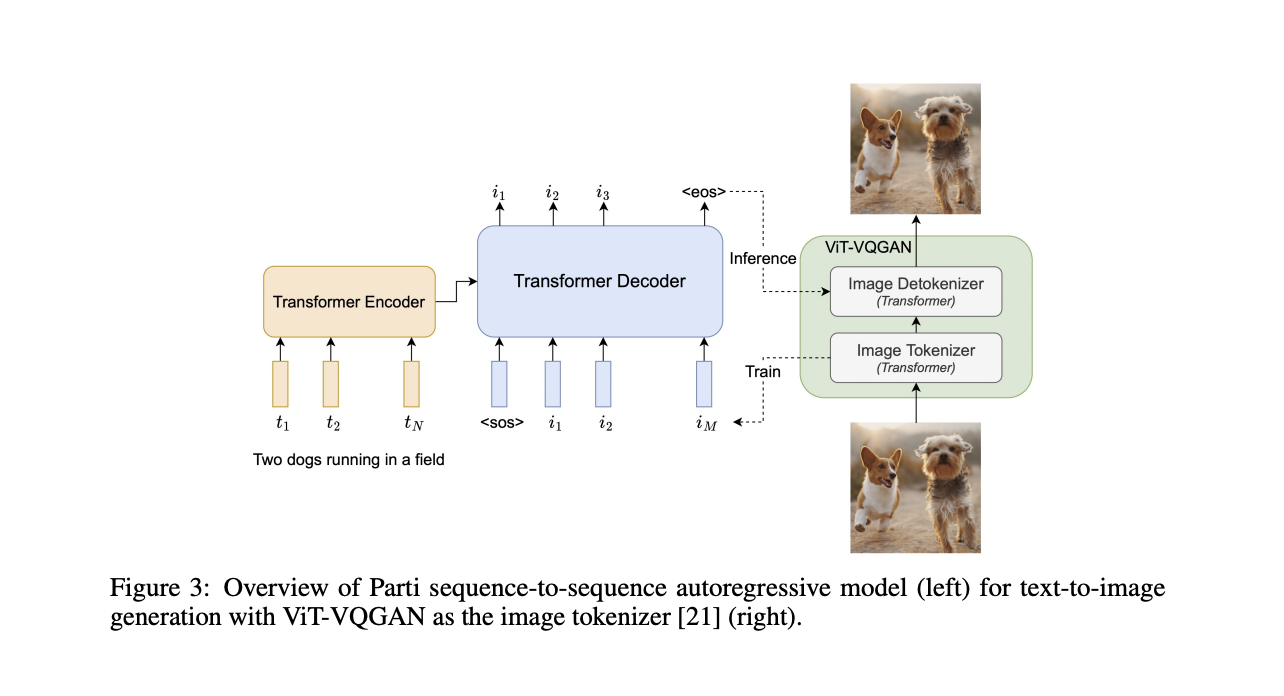
Parti is a sequence-to-sequence model based on the Transformer, a crucial architecture for various applications such as machine translation, voice recognition, conversational modeling, picture captioning, and many more. Parti uses text tokens as input to an encoder and an autoregressive decoder to predict discrete picture tokens. The image tokens are generated using the Transformer-based ViT-VQGAN image tokenizer, which provides higher-fidelity reconstructed outputs and uses less code.

Free-2 Min AI NewsletterJoin 500,000+ AI Folks
Parti is a basic idea: all its components – encoder, decoder, and picture tokenizer – are based on conventional Transformers. This ease of use allows researchers to grow their models using standard methodologies and current infrastructure. They expand the parameter size of Parti models up to 20B to investigate the boundaries of the two-stage text-to-image architecture. They see consistent quality gains regarding both text-image alignment and picture quality. On MS-COCO, the 20B Parti model obtains a new state-of-the-art zero-shot FID score of 7.23 and a finetuned FID score of 3.22.
The researcher’s primary contributions to this paper are as follows:
- Show that autoregressive models can achieve state-of-the-art performance, with 7.23 zero-shot and 3.22 finetuned FID on MS-COCO and 15.97 zero-shot and 8.39 finetuned FID on Localized Narratives.
- Scale matters: The largest Parti model is best at high-fidelity photo-realistic image generation and supports content-rich synthesis
- Implement a new comprehensive benchmark called PartiPrompts (P2) that sets a new standard for detecting the constraints of text-to-image generation models
A PyTorch implementation of Parti is available on GitHub.
This Article is written as a summary article by Marktechpost Staff based on the paper 'Scaling Autoregressive Models for Content-Rich Text-to-Image Generation'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper and github. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.