Google AI Study Presents Personalized ASR Models From Euphonia’s Corpus (Speech Corpora)

Millions of people suffer from speech problems, which can be caused by anything including neurological or genetic diseases, physical handicaps, brain damage, or hearing loss. Speech patterns such as stuttering, dysarthria, apraxia, and others that result from speech disorders make it difficult for people to express themselves and access voice-enabled devices.
With the increased computational power of deep learning systems and the availability of large training datasets, the accuracy of automated speech recognition (ASR) technologies has improved. However, their performance is still unsatisfactory for many people with speech difficulties, rendering the technology unsuitable for many speakers who could benefit from it.
The Google AI team recently released the findings of their research, which intended to make personalized ASR models accessible to more people. To accomplish this, the researchers expanded the existing disordered speech data and focused on generating personalized ASR models based on this corpus. Compared to out-of-the-box speech models trained on ordinary speech, this approach produces highly accurate models that can improve the word mistake rate by up to 85% in some domains.
Google shares the results of the two studies presented at Interspeech 2021:
Impaired Speech Data Collection
The team collected audio samples of speakers with speech impairments of differing degrees of severity across various conditions. With over 1 million utterances, Euphonia’s corpus is one of the largest and most diversely disordered speech corpus (in terms of disorder categories and severity). This large dataset enabled considerable improvements in ASR accuracy for various sorts of unusual speech.
Participants used their personal hardware (laptop or phone, with and without headphones) to collect the recorded voice data instead of an idealistic lab-based setup that would collect studio-quality recordings.
They prioritized scripted speech to save transcribing costs while retaining good transcript conformity. Prompts were displayed on a browser-based recording tool, and participants read them. The prompts included phrases for Home automation (“Turn on the TV.”), caregiver discussions (“I am hungry.”), and casual conversations (“How are you doing?”). The majority of the participants were given a list of 1500 phrases, with 1100 unique phrases and 100 phrases repeated four times each.
Speech professionals performed a comprehensive auditory-perceptual speech assessment while listening to a subset of utterances for each speaker. They then provided the speaker-level metadata of each speaker:
- Speech disorder type (e.g., stuttering, dysarthria, apraxia)
- Rating 24 features of abnormal speech (e.g., hypernasality, articulatory imprecision, dysprosody)
- Recording quality.
Personalized ASR Models
Each personalized model employs a typical RNN-Transducer (RNN-T) ASR model that is fine-tuned solely with data from the target speaker.

As speech sound abnormalities were the most common in the corpus, the researchers focused on adjusting the encoder network, which is the element of the model that deals with the unique acoustics of a given speaker. They noticed that updating only the bottom five (out of eight) encoder layers while freezing the top three (as well as the joint and decoder layers) produced the best results and efficiently avoided overfitting. They use a configuration of SpecAugment that is carefully adjusted to the prevailing characteristics of disordered speech to make these models more resilient against background noise and other acoustic influences.
They first trained ASR models for around 430 speakers who recorded at least 300 utterances. Furthermore, they used a test set of 10% of the utterances to calculate the word error rate (WER) for the personalized model and the unadapted base model.

Across all severity levels and illnesses, this personalized strategy resulted in remarkable improvements. The median WER for short phrases from the home automation area declined from roughly 89 per cent to 13 per cent, even for significantly impaired speech. Other domains, such as conversational and caregiver, had significant accuracy improvements as well.
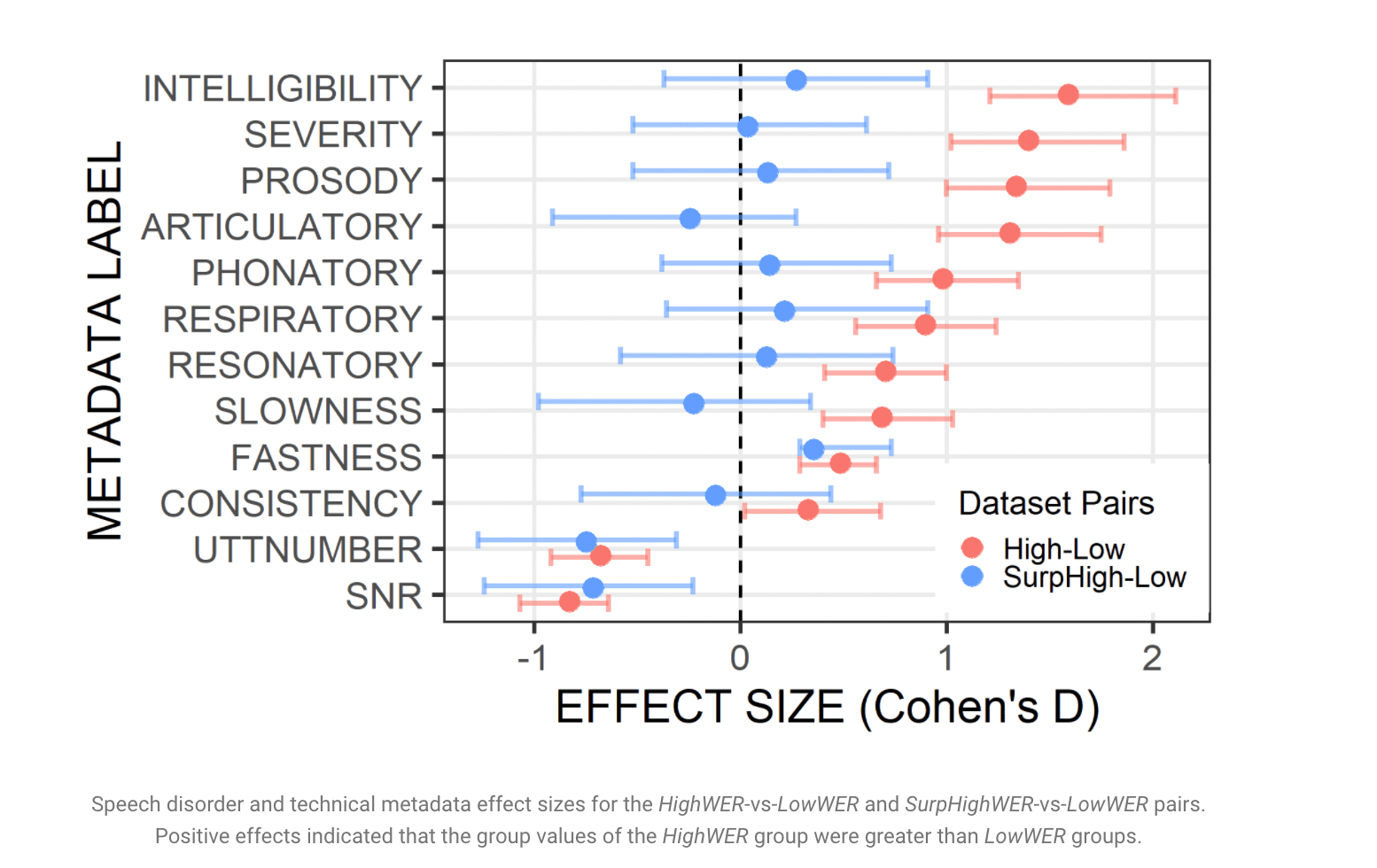
The researchers looked at different subgroups to figure out why personalization doesn’t work. The first subgroup (HighWER) consisted of speakers with high and low personalized model WERs. Participants with typical speech or mild speech impairment of the HighWER group were grouped into SurpHighWER.
ASR is likely to be impacted differently by different diseases and speech problem presentations. The HighWER group’s distribution of speech disorder types suggests that dysarthria caused to cerebral palsy was particularly challenging to simulate. The median severity was likewise higher in this group, which is unsurprising.
The team looked at the differences in the metadata between the participants who had poor (HighWER) and great (LowWER) ASR performance to determine the speaker-specific and technical elements that affect ASR accuracy.
Overall speech severity in the LowWER group was considerably lower than in the HighWER group. The most prominent atypical speech qualities in the HighWER group were intelligence and severity; however, other speech aspects such as improper prosody, articulation, and phonation also emerged. These speech characteristics have been shown to lower overall speech intelligibility.

Three speech professionals transcribed 30 utterances per speaker independently. The tailored ASR models were then compared to human listeners. The finding suggests that tailored ASR models had lower WERs on average than human listeners, with gains increasing with severity.
Source: https://ai.googleblog.com/2021/09/personalized-asr-models-from-large-and.html
Research (Disordered Speech Data Collection: Lessons Learned at 1 Million Utterances from Project Euphonia): https://www.isca-speech.org/archive/interspeech_2021/macdonald21_interspeech.html
Research (Automatic Speech Recognition of Disordered Speech: Personalized models outperforming human listeners on short phrases): https://www.isca-speech.org/archive/interspeech_2021/green21_interspeech.html
Suggested
Credit: Source link
Comments are closed.