Google DeepMind Introduces NaViT: A New ViT Model which Uses Sequence Packing During Training to Process Inputs of Arbitrary Resolutions and Aspect Ratios
The Vision Transformer (ViT) rapidly replaces convolution-based neural networks because of its simplicity, flexibility, and scalability. A picture is segmented into patches, and each patch is linearly projected to a token, forming the basis of this model. Input photos are usually squared up and divided into a set number of patches before being used.
Recent publications have investigated potential departures from this model: FlexiViT allows for a continuous range of sequence length and therefore computes cost by accommodating varied patch sizes within a single design. This is accomplished by randomly selecting a patch size during each training iteration and using a scaling technique to accommodate numerous patch sizes in the initial convolutional embedding. Pix2Struct’s alternate patching approach, which maintains the aspect ratio, is invaluable for jobs like chart and document comprehension.
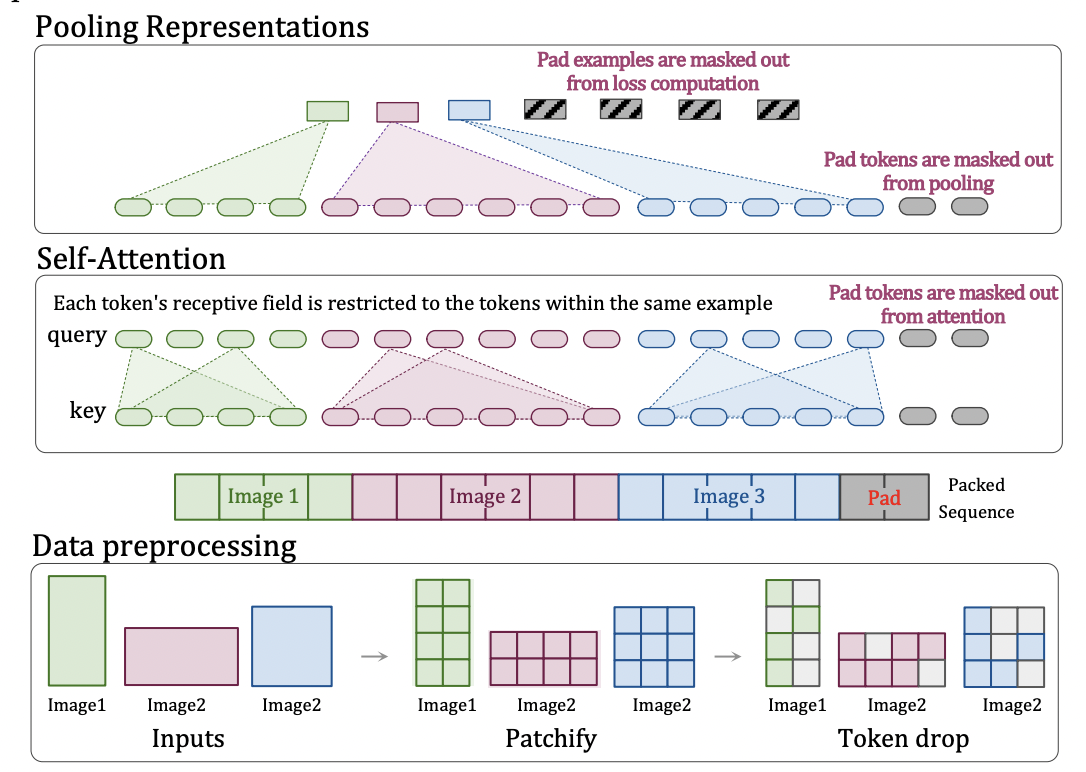
NaViT is an alternative that Google researchers developed. Patch n’ Pack is a technique that allows for varying resolution while maintaining the aspect ratio by packing many patches from distinct images into a single sequence. This idea is based on “example packing,” a technique used in natural language processing to efficiently train models with inputs of varying lengths by combining several instances into a single sequence. Scientists have found evidence of ;
A significant amount can reduce training time by randomly sampling resolutions. NaViT achieves great performance over a broad range of solutions, facilitating a smooth cost-performance trade-off at inference time, and is easily adaptable at low cost to new jobs.
Research ideas like aspect-ratio preserving resolution-sampling, variable token dropping rates, and adaptive computation emerge from the fixed batch shapes made possible by example packing.
NaViT’s computational efficiency is particularly impressive during pre-training and persists through fine-tuning. Successfully applying a single NaViT across different resolutions allows for a smooth trade-off between performance and inference cost.
Feeding data into a deep neural network during training and operation in batches is common practice. As a result, computer vision applications must use predetermined batch sizes and geometries to ensure optimal performance on existing hardware. Due to this and the inherent architectural constraints of convolutional neural networks, it has become common practice to either resize or pad images to a predetermined size.
While NaViT is based on the original ViT, any ViT variant that can process a sequence of patches can be used in theory. Researchers implement the following structural changes to support Patch n’ Pack. Patch n’ Pack is a simple application of sequence packing to visual transformers that dramatically boosts training efficiency, as proved by the research community. The resulting NaViT models are flexible and easy to adapt to new jobs without breaking the bank. Research into adaptive computation and new algorithms for enhancing training and inference efficiency are only two examples of the investigations made possible by Patch n’ Pack, which were previously hampered by the need for fixed batch forms. They also see NaViT as a step in the right direction for ViTs because it represents a change from most computer vision models’ conventional, CNN-designed input and modeling pipeline.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
🚀 Check Out 800+ AI Tools in AI Tools Club
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.