Google Deepmind Raises the Bar: Gemini 1.5 Pro’s Multimodal Capabilities Set New Industry Standards!
In the rapidly evolving field of artificial intelligence, Google’s research team has made groundbreaking strides to enhance AI’s ability to process and understand multimodal data. This advancement revolves around developing the Gemini 1.5 Pro model, a highly sophisticated AI that epitomizes efficiency in integrating complex information from textual, visual, and auditory sources. Unlike previous models that tackled modalities in isolation or struggled with integrating diverse data types, Gemini 1.5 Pro stands out for its holistic approach and unparalleled performance in synthesizing information across formats.
At the heart of this innovation is a multimodal mixture-of-experts model architecture. This design allows the AI to navigate the complexities of various data types, managing to reason and recall over extended contexts that include millions of text tokens, numerous hours of video content, and comprehensive audio data. What sets Gemini 1.5 Pro apart is its ability to maintain near-perfect recall and understanding across these modalities, demonstrating a marked improvement over its predecessors and contemporaries in AI.
The methodological brilliance of Gemini 1.5 Pro is underscored by its efficient handling of long contexts, a feat achieved through a novel mixture of expert architecture. This architecture enables the model to delve into fine-grained information from vast datasets, effectively breaking the barriers that have traditionally limited AI’s understanding of complex multimodal inputs. The model’s architecture is a testament to the research team’s ingenuity, enabling it to process up to 10 million tokens, an unprecedented scale that facilitates the comprehensive analysis of lengthy documents, extensive video sequences, and prolonged audio recordings.
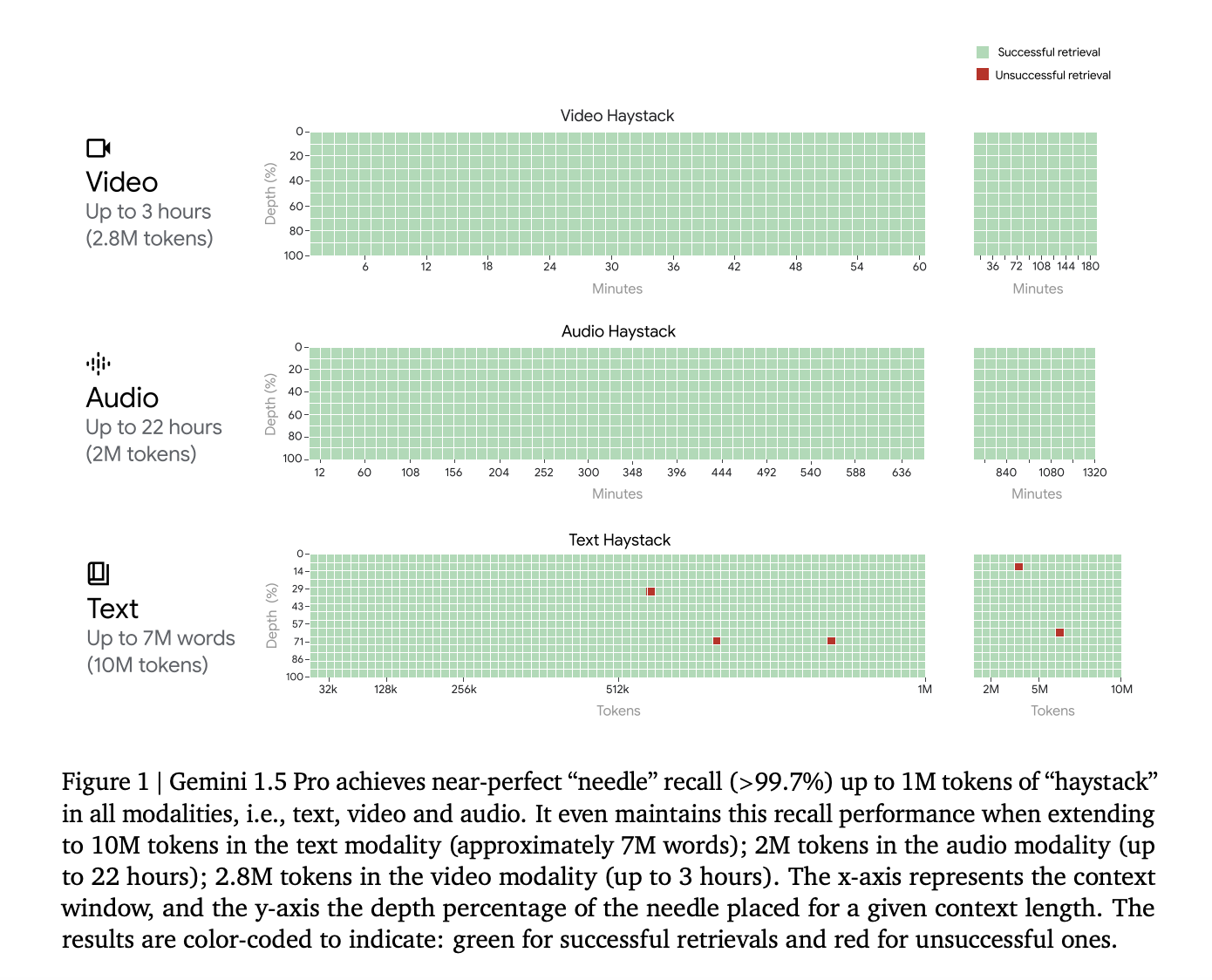
The performance metrics of Gemini 1.5 Pro are nothing short of revolutionary, showcasing near-perfect recall in long-context retrieval tasks across various modalities. The model has achieved groundbreaking results, surpassing the state-of-the-art in long-document question answering (QA), long-video QA, and long-context automatic speech recognition (ASR). For instance, in long-document QA tasks, Gemini 1.5 Pro demonstrated remarkable precision, achieving near-perfect recall (>99%) across modalities and significantly outperforming existing models in synthetic and real-world benchmarks. Its proficiency in processing and recalling information from documents containing up to 10 million tokens sets a new benchmark for AI capabilities.
Moreover, Gemini 1.5 Pro’s prowess extends beyond text to include video and audio modalities, where it continues to redefine the boundaries of AI’s potential. In tests involving long-video QA, the model exhibited exceptional performance, maintaining high recall rates and easily showcasing its ability to navigate through extensive video content. Similarly, in ASR, Gemini 1.5 Pro’s performance highlighted its superior ability to interpret and transcribe long audio sequences, further cementing its status as a paradigm-shifting development in multimodal AI research.
This leap in AI’s multimodal understanding and processing capacity heralds a new era in the field, opening up myriad possibilities for applications that require nuanced interpretation of complex data sets. The Gemini 1.5 Pro model, with its sophisticated architecture and unmatched efficiency, exemplifies the cutting-edge research being conducted by Google’s team. It advances the scientific community’s understanding of AI’s capabilities and lays the groundwork for innovative applications across various domains, from automated content analysis to enhanced natural language processing.
The implications of this research are vast, signaling a shift towards more integrated, efficient, and capable AI systems that can seamlessly process and understand the rich tapestry of human knowledge presented in multiple formats. As artificial intelligence (AI) advances, the groundwork established by Gemini 1.5 Pro and the committed work of Google’s researchers will undoubtedly significantly impact shaping the future of technology. These innovations could revolutionize how we interact with information in digital and physical environments.
Check out the Paper and Blog. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 37k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Efficient Deep Learning, with a focus on Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends advanced technical knowledge with practical applications. His current endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his commitment to enhancing AI’s capabilities. Athar’s work stands at the intersection “Sparse Training in DNN’s” and “Deep Reinforcemnt Learning”.
Credit: Source link
Comments are closed.