Google DeepMind Researchers Introduce DiLoCo: A Novel Distributed, Low-Communication Machine Learning Algorithm for Effective and Resilient Large Language Model Training
The soaring capabilities of language models in real-world applications are often hindered by the intricate challenges associated with their large-scale training using conventional methods like standard backpropagation. Google DeepMind’s latest breakthrough, DiLoCo (Distributed Low-Communication), sets a new precedent in language model optimization. In the paper “DiLoCo: Distributed Low-Communication Training of Language Models,” the research team introduces an innovative distributed optimization algorithm that revolutionizes training approaches by operating on clusters of loosely connected devices, achieving a remarkable performance boost and reducing communication by 500 times.
Inspired by Federated Learning principles, the researchers devised a variant of the widely recognized Federated Averaging (FedAvg) algorithm, infusing it with elements akin to the FedOpt algorithm. DiLoCo strategically incorporates AdamW as the inner optimizer and leverages Nesterov Momentum as the outer optimizer, crafting an ingenious amalgamation that tackles the challenges entrenched within conventional training paradigms.
The brilliance of DiLoCo lies in its three fundamental pillars:
1. Limited co-location requirements: Each worker necessitates co-located devices, yet the total number required is notably smaller, easing logistical complexities.
2. Reduced communication frequency: Workers no longer need to communicate at every step but synchronize only at intervals of 𝐻 steps, significantly curbing communication overhead to mere hundreds or even thousands.
3. Device heterogeneity: While devices within a cluster must be homogeneous, DiLoCo allows different clusters to operate using diverse device types, offering unparalleled flexibility.

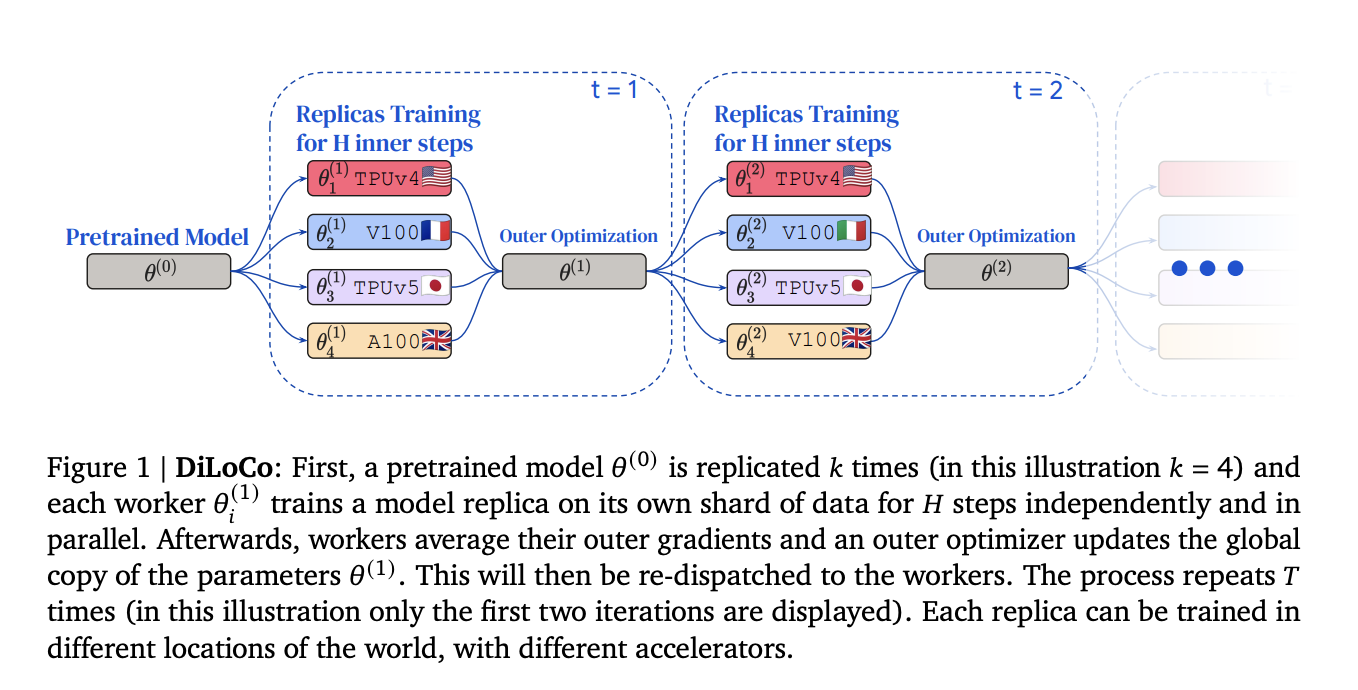
The DiLoCo training process involves replicating a pretrained model 𝜃 (0) multiple times. Each worker independently trains a model replica on its individual data shard for 𝐻 steps. Subsequently, workers average their outer gradients, and an outer optimizer updates the global parameter copy 𝜃 (1), which is distributed back to the workers. This cyclic process repeats 𝑇 times, enabling each replica’s training in distinct global locations using various accelerators.
In practical experiments with the C4 dataset, DiLoCo employing eight workers achieves performance on par with fully synchronous optimization while reducing communication by an astounding 500 times. Moreover, DiLoCo demonstrates exceptional resilience to variations in data distribution among workers and seamlessly adapts to changing resource availabilities during training.
In essence, DiLoCo emerges as a robust and transformative solution for distributing the training of transformer language models across multiple poorly connected machines. This groundbreaking approach not only surmounts infrastructure challenges but also showcases unparalleled performance and adaptability, heralding a significant leap forward in language model optimization.

Niharika is a Technical consulting intern at Marktechpost. She is a third year undergraduate, currently pursuing her B.Tech from Indian Institute of Technology(IIT), Kharagpur. She is a highly enthusiastic individual with a keen interest in Machine learning, Data science and AI and an avid reader of the latest developments in these fields.
Credit: Source link
Comments are closed.