Google DeepMind Researchers Utilize Vision-Language Models to Transform Reward Generation in Reinforcement Learning for Generalist Agents
Reinforcement learning (RL) agents epitomize artificial intelligence by embodying adaptive prowess, navigating intricate knowledge landscapes through iterative trial and error, and dynamically assimilating environmental insights to autonomously evolve and optimize their decision-making capabilities. Developing generalist RL agents that can perform diverse tasks in complex environments is a challenging task that requires numerous reward functions. However, researchers are investigating ways to overcome this obstacle.
Researchers from Google DeepMind explore using off-the-shelf vision-language models (VLMs), specifically the CLIP family, to derive rewards for training RL agents capable of diverse language goals. Demonstrating in two visual domains, the research reveals a scaling trend where larger VLMs lead to more accurate rewards, enhancing RL agent capabilities. It also discusses converting the reward function into a binary form through probability thresholding. Experiments address VLM reward maximization and scaling impact, suggesting improved VLM quality could enable training generalist RL agents in rich visual environments without task-specific finetuning.
The research addresses the challenge of creating versatile RL agents capable of diverse goals in complex environments. Traditional RL relies on explicit reward functions, posing challenges in defining varied goals. The study explores leveraging VLMs, particularly CLIP, as a solution. VLMs, like CLIP, trained on extensive image-text data, offer promising performance in various visual tasks and can serve as effective reward function generators. The research investigates using off-the-shelf VLMs for accurate reward derivation, focusing on language goals in visual contexts, aiming to streamline RL agent training.
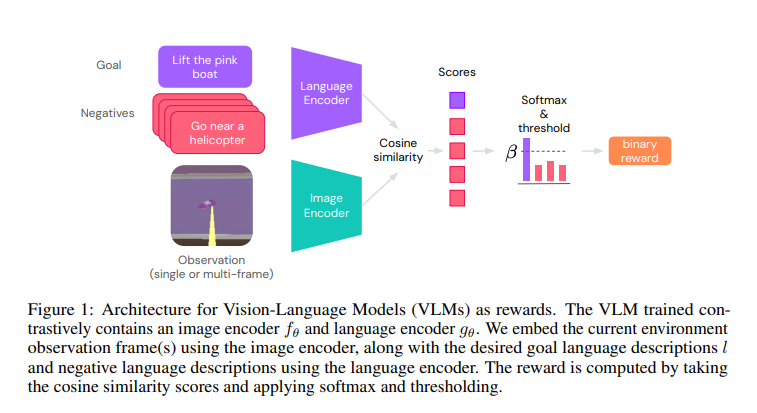
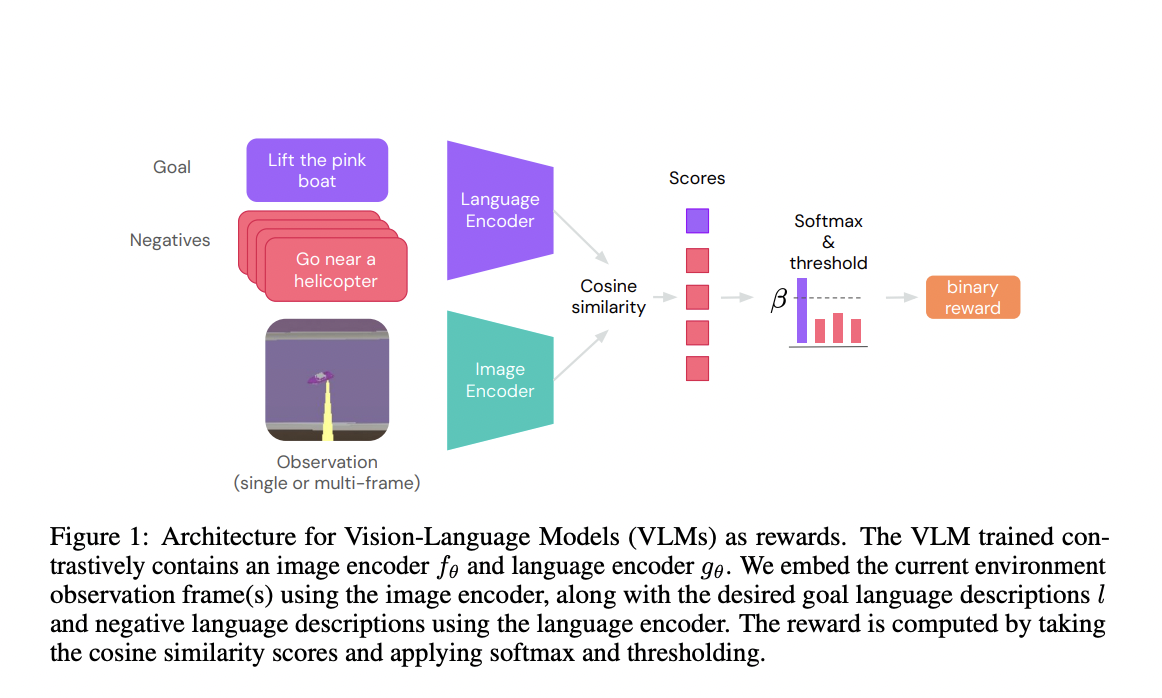
The study utilizes contrastive VLMs like CLIP to generate text-based reward models for reinforcement learning agents. It establishes a reward model comprising image and text encoders, producing binary rewards indicating goal achievement. Operating in a partially observed Markov Decision Process, the premium is computed through a VLM based on scanned images and language-based goals. The study employs pre-trained CLIP models in experiments across Playhouse and AndroidEnv, exploring encoder architectures such as Normalizer-Free Networks, Swin, and BERT for language encoding in tasks like Find, Lift, and Pick and Place.
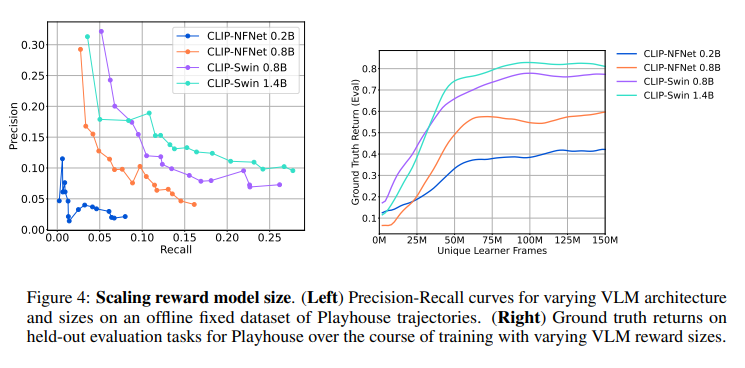
The approach highlights off-the-shelf VLMs, specifically CLIP, as reward sources for RL agents. It demonstrates deriving rewards for diverse language goals from CLIP, training RL agents across Playhouse and AndroidEnv domains. Larger VLMs yield more accurate rewards, enhancing agent capabilities. Scaling VLM size generally improves performance. It also explores prompt engineering’s impact on VLM reward performance, although the sources do not provide specific results.
To conclude, the research can be summarized in the following points:
- The study proposes a method to obtain sparse binary rewards for reinforcement learning agents using pre-trained CLIP embeddings for visual achievement of language goals.
- Off-the-shelf VLMs, such as CLIP, can be rewarded sources without environment-specific finetuning.
- The approach is demonstrated in Playhouse and AndroidEnv domains.
- Larger VLMs lead to more accurate rewards and more capable RL agents.
- Maximizing VLM rewards enhances ground truth rewards, and scaling VLM size positively impacts performance.
- The study examines the role of prompt engineering in VLM reward performance.
- The potential of VLMs for training versatile RL agents in diverse language goals within visual environments is highlighted.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 34k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
Credit: Source link
Comments are closed.