Google Docs Now Auto-Generate Short Summaries Using Machine Learning
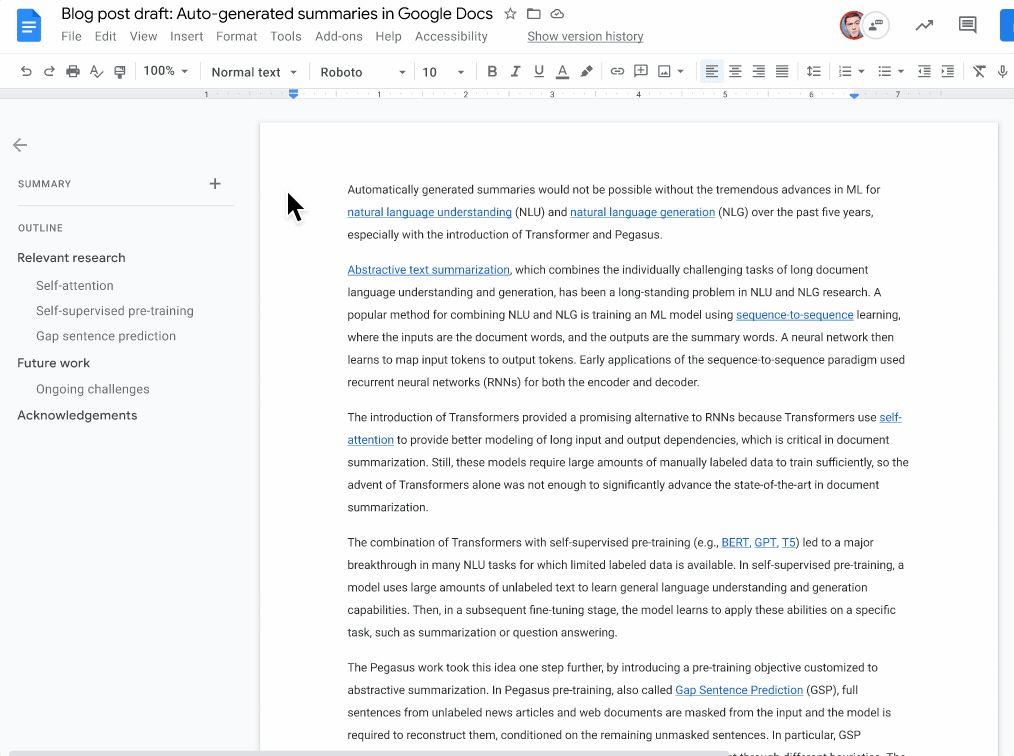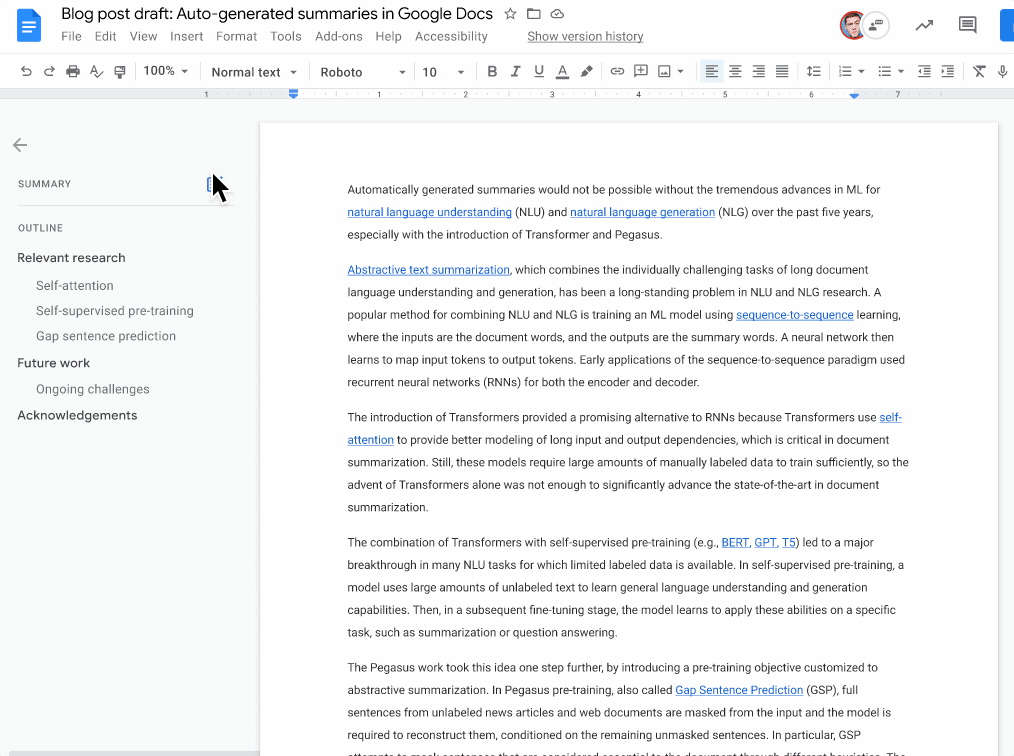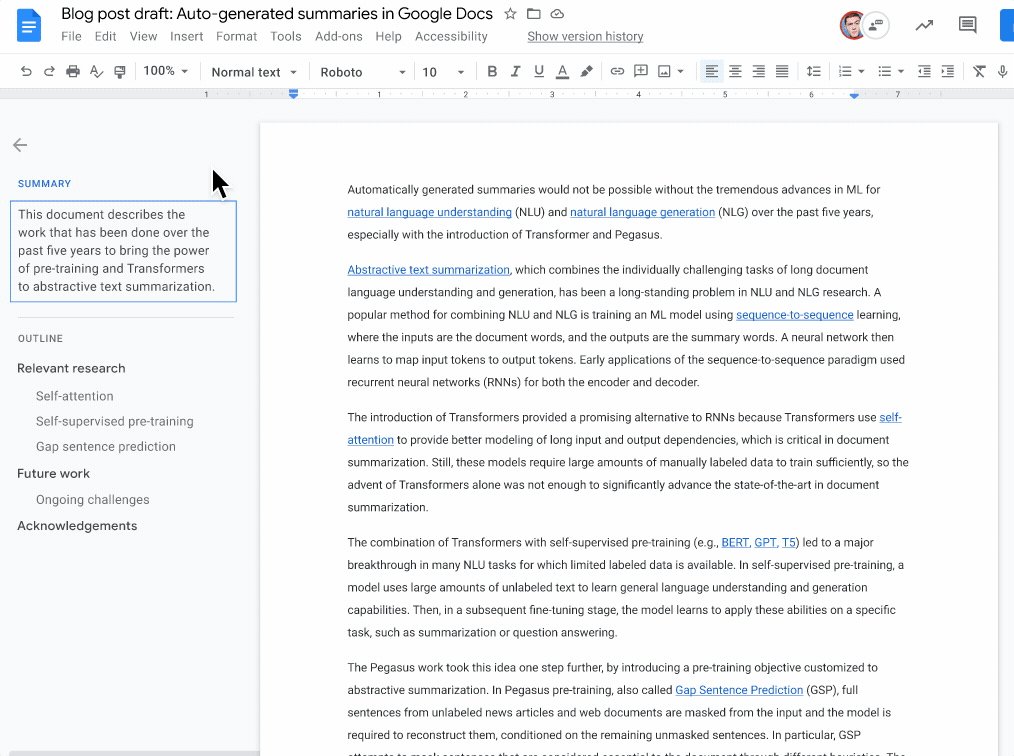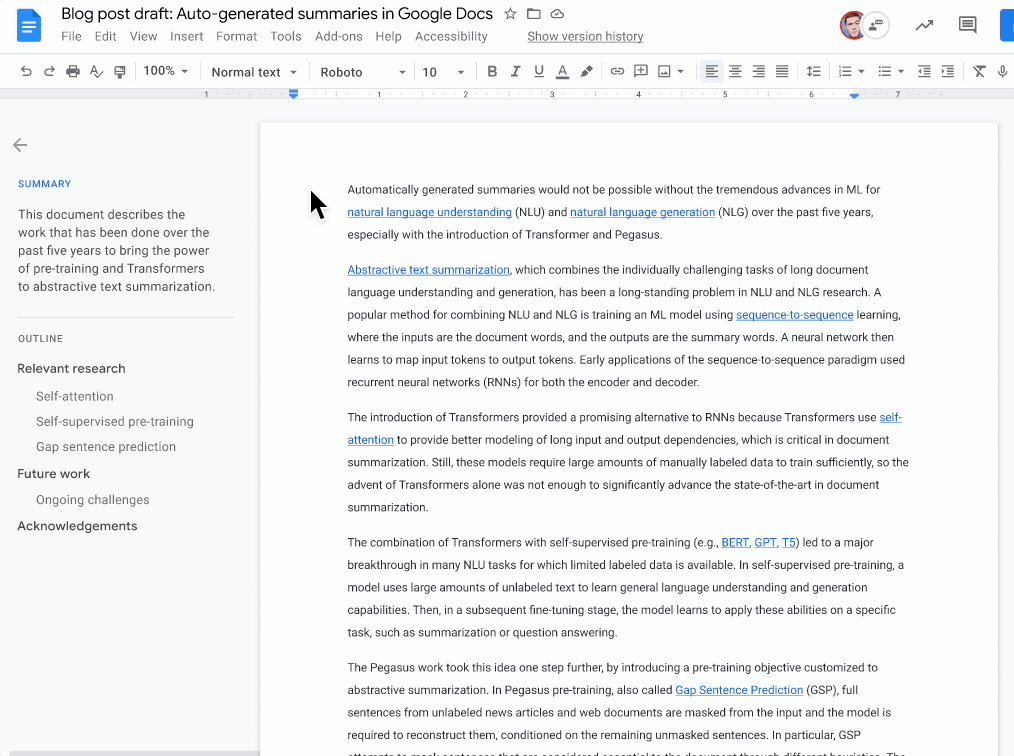
Many of us find it difficult to keep up with the daily flood of documents in our inboxes. These could be reports, reviews, briefs, policies, etc. Nowadays, readers wish to have a concise summary including major elements of their document, helping them prioritize their work efficiently. However, writing a document summary from scratch manually is a time-consuming task.
To aid document writers in writing content summaries, Google announced a new feature enabling Google Docs to generate ideas automatically when they are available. The team employs a machine learning (ML) model to understand document text and provide a one- to two-sentence natural language description of the material. On the other hand, the document writer retains complete control, choosing whether to accept the proposal as-is, make necessary adjustments to better capture the document summary, or ignore it entirely. This section, combined with the outline, can help readers understand and navigate the work at a high level. While anybody can contribute summaries, only Google Workspace business customers have access to auto-generated ideas.
The promising results achieved by numerous machine learning algorithms for natural language understanding (NLU) and natural language generation (NLG) have made automatically generated summaries possible.
Abstractive text summarization has been an issue in NLU and NLG research. This is because it combines the independently difficult tasks of long document language understanding and creation. Training an ML model using sequence-to-sequence learning is a popular method for integrating NLU and NLG. In this method, the inputs are document words, which are subsequently mapped to the output token, which are summary words.
Earlier work employed Recurrent neural networks (RNNs) in sequence-to-sequence applications. Transformers use self-attention to better model long input and output dependencies, which is crucial in document summarization. That is why they have become a promising alternative to RNNs because these models require a lot of manually labeled data to train.

In several NLU tasks with limited labeled data, Transformers and self-supervised pre-training combined resulted in a big breakthrough. A model learns generic language interpretation and generation capabilities in self-supervised pre-training by consuming vast amounts of unlabeled text. The model then learns to apply these talents to a specific goal in a later fine-tuning stage.
The researchers extended this approach by pre-training targets tailored to abstractive summarization in the Pegasus study. At first, entire sentences from unlabeled articles and web documents are masked from the input in Pegasus pre-training (also called Gap Sentence Prediction (GSP)). Then the model is needed to rebuild them based on the remaining unmasked phrases. GSP, for instance, employs a variety of heuristics to conceal sentences that are considered critical to the content. The idea is to get the pre-training near the summarising task as possible. On a variety of summarization datasets, Pegasus produced state-of-the-art results. However, there were still a few obstacles before this research breakthrough could be turned into a commercial.
Self-supervised pre-training produces an ML model capable of generic language understanding and creation. However, fine-tuning is required for the model to adapt to the application domain.
The team used a corpus of papers with human-created summaries (consistent with usual use scenarios) to fine-tune early iterations of the algorithm. However, this corpus had inconsistencies and a lot of variation because it included a lot of different types of documents and numerous ways of writing a summary. For example, academic abstracts are usually long and detailed, whereas executive summaries are short and to the point. As the model was trained on various papers and summaries, it struggled to grasp the differences between them.
The findings suggest that an efficient pre-training phase required less supervised data in the fine-tuning step. Pegasus matches the performance of Transformer baselines with 10,000+ supervised instances with as few as 1,000 fine-tuning examples in several summarization evaluations. This implies that quality could be prioritized before the number.
The fine-tuning data was rigorously cleaned and filtered to include training examples that were more consistent and represented a consistent definition of summaries. Despite using less training data, the model turned out to be of superior quality. This suggests that a smaller, high-quality dataset was preferable to a larger, high-variance dataset.
The encoder-decoder architecture’s transformer version is the most popular method for training models for sequence-to-sequence tasks such as abstractive summarization. However, it is observed to be wasteful and unworkable in real-world applications. RNNs are a more efficient decoding architecture than Transformers since there is no self-attention with prior tokens.
To incorporate the Pegasus model into a hybrid architecture of a Transformer encoder and an RNN decoder, the team employed knowledge distillation. This involves transferring knowledge from a large model to a smaller, more efficient model. They also lowered the number of RNN decoder layers to increase efficiency. The new model had significantly reduced latency and memory footprint while maintaining the same level of quality as the previous model. They serve the summarization model using TPUs to enhance latency and user experience further. TPUs enable considerable speedups and allow more requests to be handled by a single machine.
Due to the enormous variety of documents, developing a collection of documents for the fine-tuning stage is difficult. The current model only suggests a summary for papers in which it has the most confidence. The researchers plan to expand this collection to further different summaries, for instance, abstractive summaries. Many distinct summaries can be judged correct for a given document, and various readers may favor different ones. This makes it difficult to evaluate summaries only based on artificial analytics; user feedback and usage statistics will be crucial in helping us understand and improve quality.
Long documents are the most difficult for the model to summarise since it is more difficult to capture all of the elements and abstract them into a single summary. Moreover, it can also raise memory use dramatically during training and serving. That is why it will be beneficial to automatically summarise because it allows document writers to get a head start on this time-consuming work. The team hopes that more research work will help address this problem.
References:
- https://ai.googleblog.com/2022/03/auto-generated-summaries-in-google-docs.html
- https://cloud.google.com/blog/products/workspace/delivering-new-innovations-in-google-workspace-with-smart-canvas
Suggested
Credit: Source link
Comments are closed.