Google Highlights How Statistical Uncertainty Of Outcomes Must Be Considered To Evaluate Deep RL Reliably and Propose A Python Library Called ‘RLiable’

Reinforcement Learning (RL) is a machine learning technique that allows an agent to learn by trial and error in an interactive environment from its experiences. While the subject of RL has achieved significant progress, it is becoming increasingly clear that current empirical evaluation standards may create the impression of rapid scientific development while actually slowing it down.
A recent Google study highlights how statistical uncertainty of outcomes must be considered for deep RL evaluation to be reliable, especially when only a few training runs are used. Google has also released an easy-to-use Python library called RLiable to help researchers incorporate these tools.
The common practice of presenting point estimates, in particular, ignores this uncertainty and makes results difficult to replicate. As they are often published, tables with per-task results can be overwhelming after a few tasks, and they frequently omit standard deviations. While a few outlier activities can dominate basic performance measurements like the mean, the median score is unaffected even if up to half of the tasks have zero performance scores.
As a result, the team proposes a number of statistical methodologies and improved metrics to improve the field’s confidence in reported results based on a number of trials.
Empirical research in RL assesses progress by evaluating performance on a variety of tasks, such as Atari 2600 video games. The aggregated mean and median scores across tasks are often compared in published findings on deep RL benchmarks. These ratings are often relative to some stated baseline and optimal performance to make scores comparable across different tasks.
Because the scores gained from separate training runs in most RL studies are random, giving merely point estimates does not disclose if similar results will be reached with new independent runs. Because of the small number of training runs and the considerable variability in the performance of deep RL algorithms, such point estimates often have a lot of statistical uncertainty.
Due to the additional work and data required to perform such tasks, evaluating more than a few runs will become increasingly tricky as benchmarks become more complicated. As a result, reviewing more runs to reduce statistical uncertainty on computationally demanding benchmarks is not a viable strategy. While statistical significance tests have been suggested in the past as a solution, because they are binary (either “significant” or “not significant”), they typically lack the granularity needed to offer meaningful insights and are sometimes misinterpreted.
To account for the fact that any aggregate metric based on a finite number of runs is a random variable, they recommend publishing stratified bootstrap confidence intervals (CIs). CIs forecast the likely values of aggregate metrics if the experiment were repeated with alternative runs. These confidence intervals help comprehend the statistical uncertainty and repeatability of the findings. The scores on combined runs across tasks are used in these CIs.
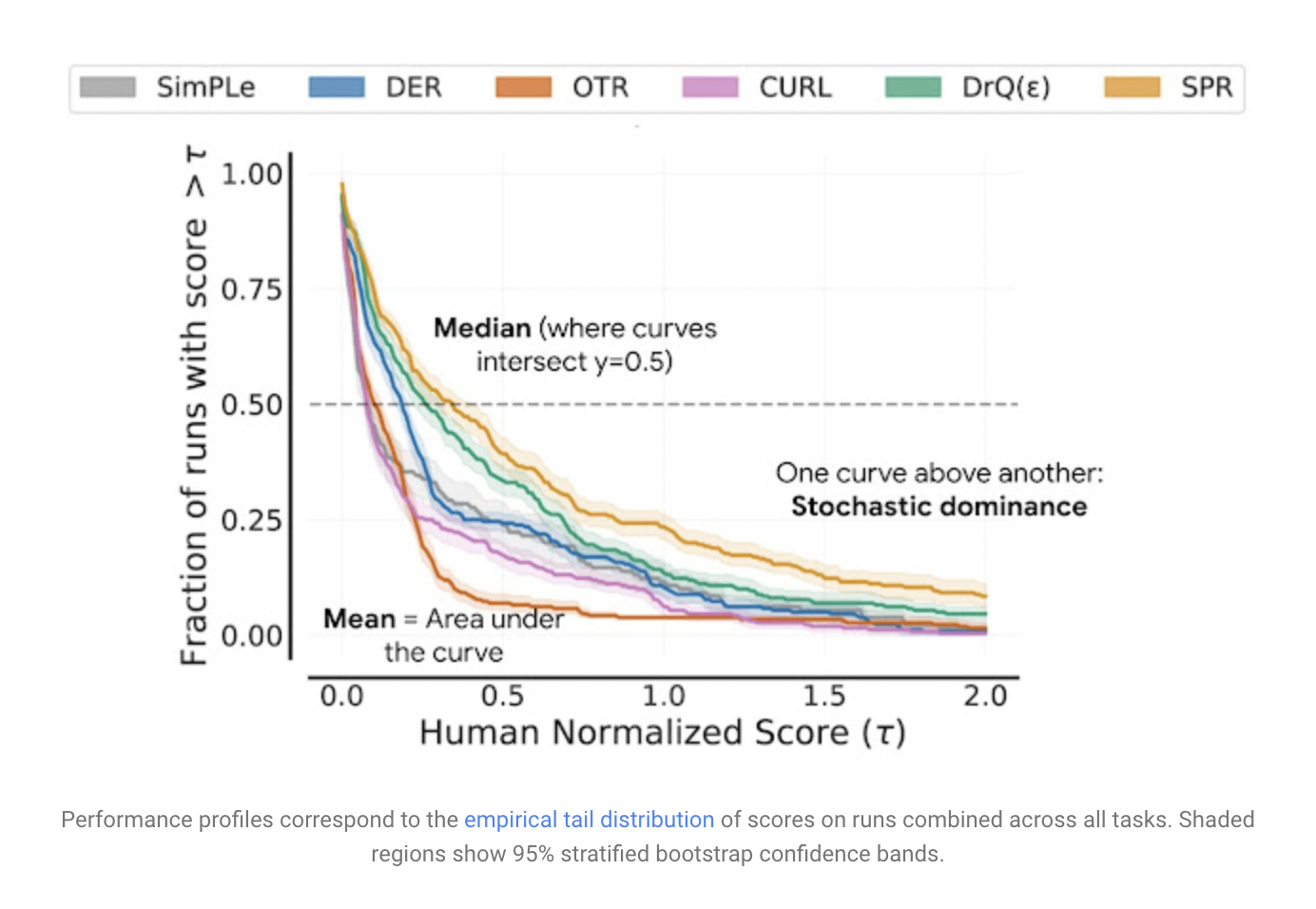
Although most deep RL algorithms perform better on some jobs and training runs than others, aggregate performance measurements might hide this variability. The researchers suggest using performance profiles, which are commonly used to compare optimization software solve times. These graphs show the distribution of scores over all runs and tasks, along with uncertainty estimates based on stratified bootstrap confidence bands.
Qualitative comparisons can be made at a glance with such profiles. Furthermore, the mean score is shown by the area beneath the profile.
While performance profiles are valuable for qualitative comparisons, algorithms seldom outperform one other on all tasks. Hence their profiles frequently intersect, needing aggregate performance measurements for finer quantitative comparisons. Existing metrics, however, have the following limitations:
- A single high-performing task might dominate the mean task score
- The task median is unaffected by zero scores on nearly half of the tasks
- Minimal statistical uncertainty needs a large number of training trials
For this, they propose two alternatives to solve the preceding limitations: the interquartile mean (IQM) and the optimality gap, both based on robust statistics.
IQM stands for the mean score of the middle 50% of all runs combined across all tasks as an alternative to the median and mean. It is more resistant to outliers than the mean, is a better predictor of overall performance than the median, has smaller CIs, and requires fewer runs to claim improvements. The optimality gap, an alternative to mean, evaluates how distant an algorithm is from its best performance.
Another measure to examine when directly comparing two algorithms is the average likelihood of improvement, which reflects how often an improvement over baseline is regardless of magnitude. The Mann-Whitney U-statistic is used to calculate this metric, which is averaged over tasks.
The team examines performance evaluations of existing algorithms on commonly used RL benchmarks using the methods mentioned above, showing anomalies in previous evaluations. For example, the performance ranking of algorithms in the Arcade Learning Environment (ALE), a well-known RL benchmark, varies depending on the aggregate statistic used. Because performance profiles provide a complete view, they are frequently used to explain why inconsistencies arise. Most algorithms have high overlaps in 95 percent CIs of mean normalized scores on DM Control, a standard continuous control benchmark.
Github: https://github.com/google-research/rliable
Project: https://agarwl.github.io/rliable/
Paper: https://openreview.net/forum?id=uqv8-U4lKBe
Source: https://ai.googleblog.com/2021/11/rliable-towards-reliable-evaluation.html
Suggested

Credit: Source link
Comments are closed.