Google Introduces A New AI Robot Model Called ‘PaLM-SayCan’ That Allows Alphabet-Developed Robots To Better Understand the User’s commands and Respond Correctly
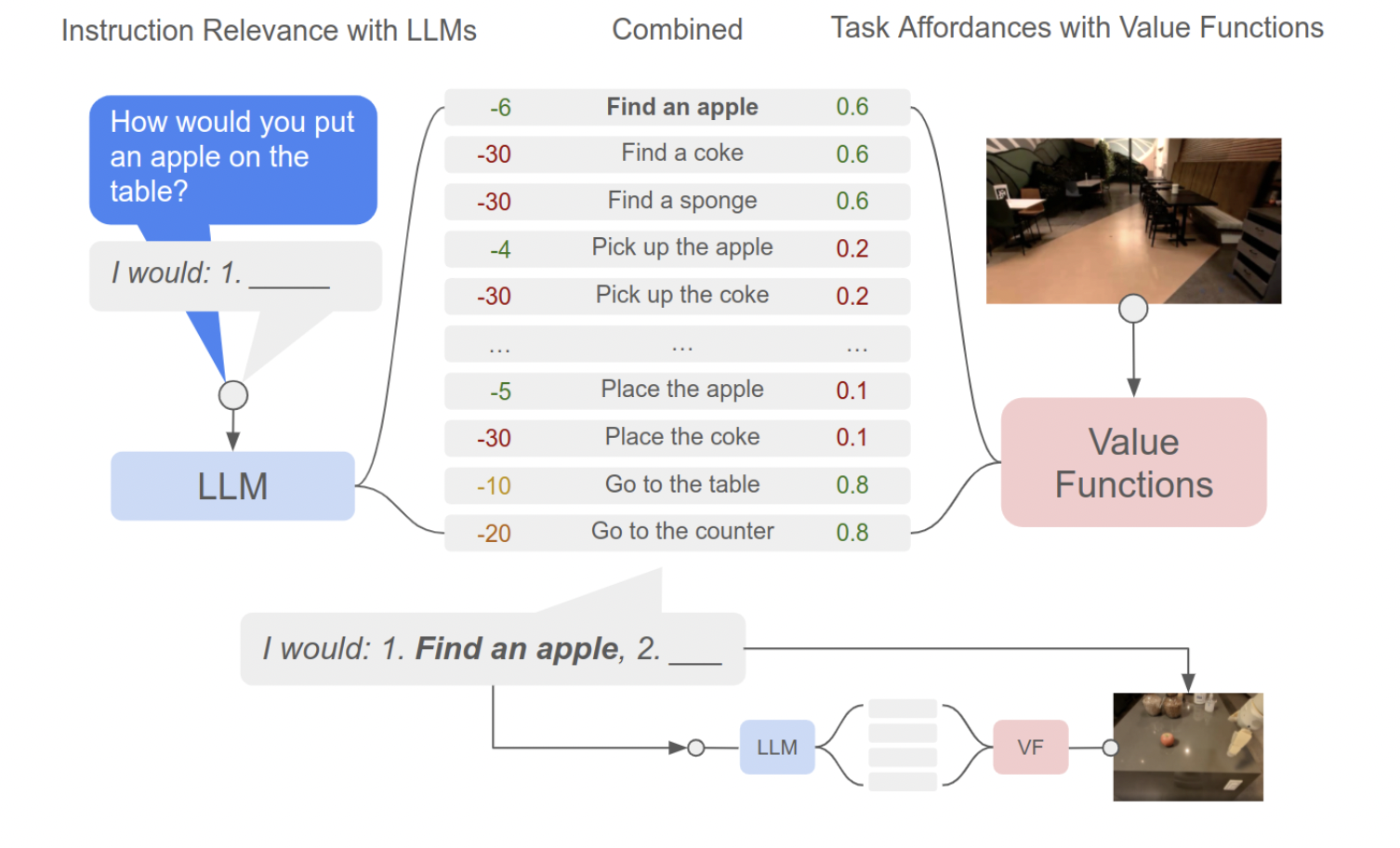
PaLM-SayCan is the first implementation that uses a large-scale language model to plan for a real robot. It is a novel approach that uses advanced language model knowledge to allow a physical agent to follow high-level instructions for physically-based tasks. It aims to ground the language model in tasks that are practical in a particular real-world context, such as driving or building a car.
It enables the robot to understand the way we communicate. Google Research and Everyday Robots are working together to combine the best of language models with robot learning.

Google’s PaLM-SayCan robots can take commands that are safe for a robot to perform and highly interpretable. When the system was integrated with PaLM, they saw a 14% improvement in the planning success rate. They also saw a 13% increase in the execution success rate or successfully carrying out a task.
A User and Robotic Dialogue Made Possible by the Language Model
The researcher’s method finds and scores actions that are helpful for high-level instructions using the knowledge found in language models. Additionally, it uses an affordance function (Can) to enable real-world grounding and choose which activities are feasible in a specific setting. They refer to this as PaLM-SayCan and use the PaLM language model.
Their method chooses abilities based on the language and affordance models’ ratings for usefulness to high-level instruction.
Their system can be considered a conversation between a user and a robot made possible by a language model. The language model begins by receiving an order from the user, which it then converts into a set of actions the robot should take. The robot’s skill set filters this sequence to find the best workable strategy given its current situation and surroundings. The model multiplies two probabilities:
(1) task-grounding
(2) world-grounding
to calculate the likelihood that a particular skill would successfully advance toward finishing the instruction.
Their strategy has extra advantages in terms of its safety and interpretability. First, they effectively limit the LM to only produce one of the pre-selected responses by allowing the LM to score many choices rather than generate the most likely reply. By examining the distinct language and affordance scores rather than a single result, the user can also easily comprehend the decision-making process.
The top choices that PaLM-SayCan examines at each stage can be seen in terms of their language score (blue), affordance score (red), and combination score (green).
Training Guidelines and Values
Each skill in the agent’s skillset is described as a policy with a brief linguistic description (such as “pick up the can”), expressed as embeddings, and an affordance function that shows the likelihood that the skill can be completed given the robot’s current state. They employ sparse reward functions set to 1.0 for successful execution and 0.0 otherwise to learn the affordance functions.
The language-conditioned policies are trained using image-based behavioural cloning (BC), and the value functions are trained using temporal-difference-based (TD) reinforcement learning (RL). Data from 68,000 demos done by 10 robots over 11 months were gathered to train the policies, and 12,000 successful episodes—filtered from a collection of autonomous episodes of learnt rules—were added. Then, in the Everyday Robots simulator, they knew the language’s conditioned value functions using MT-Opt. A simulated representation of the abilities and surroundings, which is changed using RetinaGAN to close the simulation-to-actual gap, augments our real robot fleet. By using demos to deliver early successes, they bootstrapped simulation policy performance and then constantly enhanced RL performance with online data gathering in simulation.
Their method chooses the subsequent skill to practice based on high-level instruction by combining the probability from the language model and value function (VF). Until the high-level instruction is successfully performed, this process is repeated.
The researcher team assesses the system’s performance using two metrics:
- The plan success rate, which shows if the robot selected the appropriate abilities for the instruction, and
- The execution success rate, which shows whether it effectively carried out the instruction. They contrast two language models, PaLM and FLAN (a smaller language model focused on instruction response), both with and without the underlying policies that directly use natural language.
The findings reveal that the PaLM-SayCan system, which uses PaLM with affordance grounding to reduce errors, selects the right sequence of skills 84% of the time and executes them successfully 74% of the time. This is a 50% improvement over FLAN and PaLM without robotic grounding. This is especially intriguing because it shows us for the first time how advancement in language models can lead to equivalent progress in robotics. This finding suggests that robotics may benefit from the improvements in language modelling in the future, bringing these two research areas closer together.
Compared to PaLM without affordances and to FLAN over 101 tasks, PaLM-SayCan reduces errors by half.
When used with PaLM, SayCan successfully planned 84% of the 101 test instructions.
Final Thoughts and Future Work
PaLM-SayCan is a universal and interpretable method for utilising language model knowledge that enables a robot to follow high-level textual instructions. They intend to better understand how real-world experience gained by the robot could be used to enhance the language model. They have made a robot simulation setup open-sourced, hoping it will be a useful tool for future research that blends robotic learning with sophisticated language models.
They follow all the tried and true principles of robot safety, including risk assessments, physical controls and emergency stops. For now, these robots are just getting better at grabbing snacks for Googlers in our micro-kitchens.
Paper: https://arxiv.org/pdf/2204.01691.pdf
Project: https://say-can.github.io/
Github: https://github.com/google-research/google-research/tree/master/saycan
References:
- https://blog.google/technology/ai/making-robots-more-helpful-with-language/
- https://www.ithome.com.tw/news/152540
- https://ai.googleblog.com/2022/08/towards-helpful-robots-grounding.html
![]()
Ashish kumar is a consulting intern at MarktechPost. He is currently pursuing his Btech from the Indian Institute of technology(IIT),kanpur. He is passionate about exploring the new advancements in technologies and their real life application.
Credit: Source link
Comments are closed.