Google Research Explores: Can AI Feedback Replace Human Input for Effective Reinforcement Learning in Large Language Models?
Human feedback is essential to improve and optimize machine learning models. In recent years, reinforcement learning from human feedback (RLHF) has proven extremely effective in aligning large language models (LLMs) with human preferences, but a significant challenge lies in collecting high-quality human preference labels. In a research study, researchers at Google AI have attempted to compare RLHF to Reinforcement Learning from AI Feedback (RLAIF). RLAIF is a technique in which preferences are labeled by a pre-trained LLM instead of relying on human annotators.

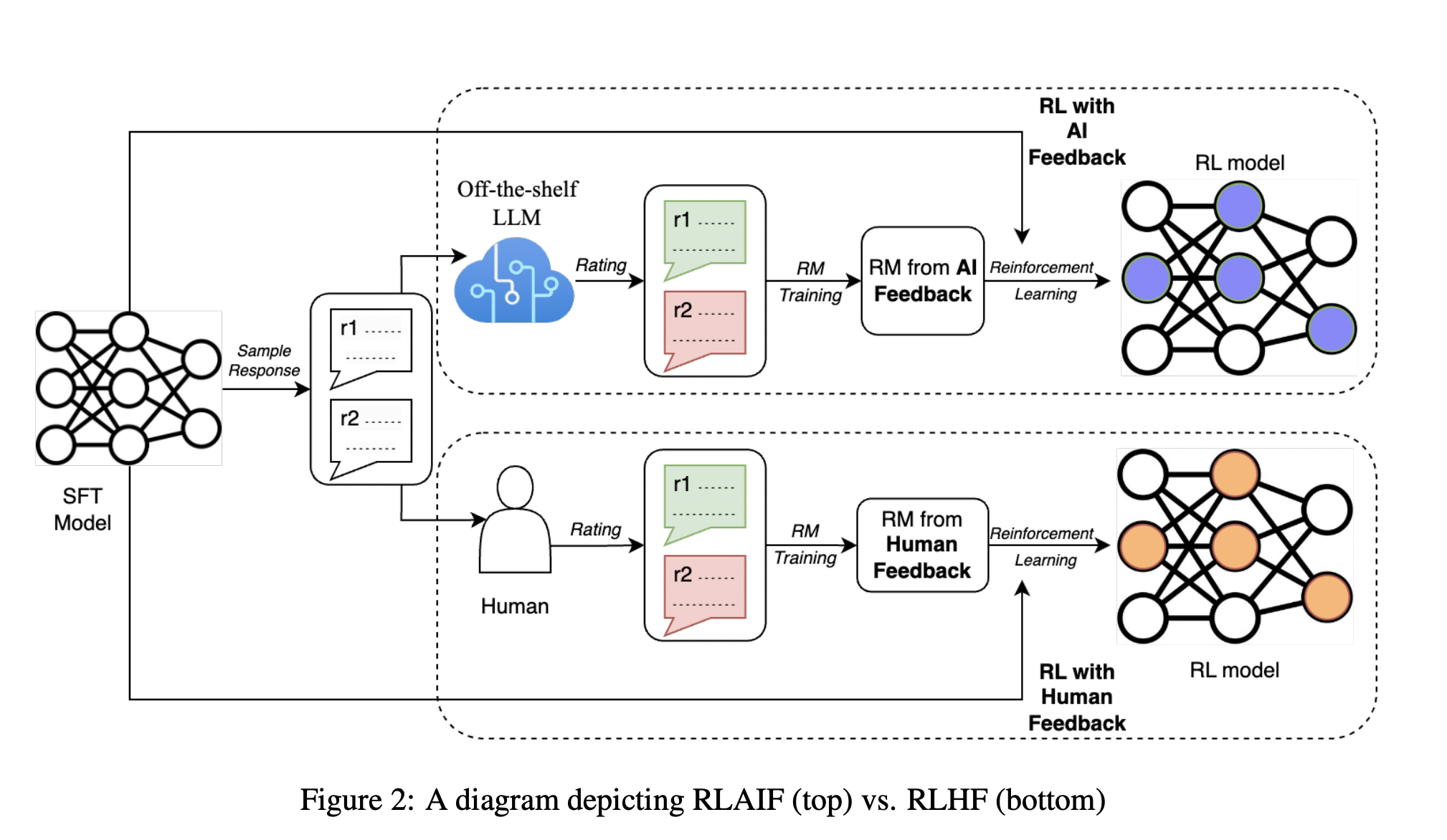
In this study, the researchers conducted a direct comparison between RLAIF and RLHF in the context of summarization tasks. They were tasked with providing preference labels for two candidate responses given a text, utilizing an off-the-shelf Large Language Model (LLM). Subsequently, a reward model (RM) was trained based on the preferences inferred by the LLM, incorporating a contrastive loss. The final step involved fine-tuning a policy model through reinforcement learning techniques. The above image demonstrates a diagram depicting RLAIF (top) vs. RLHF (bottom).

The above image demonstrates example summaries generated by SFT, RLHF and RLAIF policies for a Reddit post. RLHF and RLAIF have produced higher quality summaries than SFT, which fails to capture key details.
The results presented in this study demonstrate that RLAIF achieves comparable performance to RLHF when evaluated in two distinct ways:
- Firstly, it was observed that both RLAIF and RLHF policies received a preference from human evaluators over a supervised fine-tuned (SFT) baseline in 71% and 73% of cases, respectively. Importantly, statistical analysis did not reveal a significant difference in the win rates between the two approaches.
- Secondly, when humans were asked to directly compare generations produced by RLAIF versus RLHF, they expressed an equal preference for both, resulting in a 50% win rate for each method. These findings suggest that RLAIF represents a viable alternative to RLHF that operates independently of human annotation and exhibits attractive scalability properties.
We can note that this work only explores the task of summarization, leaving an open question about generalizability to other tasks. Further, the study does not include an estimation of whether Large Language Model (LLM) inference is cost-effective compared to human labeling in terms of monetary expenses. In the future, researchers hope to explore this area.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Janhavi Lande, is an Engineering Physics graduate from IIT Guwahati, class of 2023. She is an upcoming data scientist and has been working in the world of ml/ai research for the past two years. She is most fascinated by this ever changing world and its constant demand of humans to keep up with it. In her pastime she enjoys traveling, reading and writing poems.
Credit: Source link
Comments are closed.