Google Research Introduces TimesFM: A Single Forecasting Model Pre-Trained on a Large Time-Series Corpus of 100B Real World Time-Points
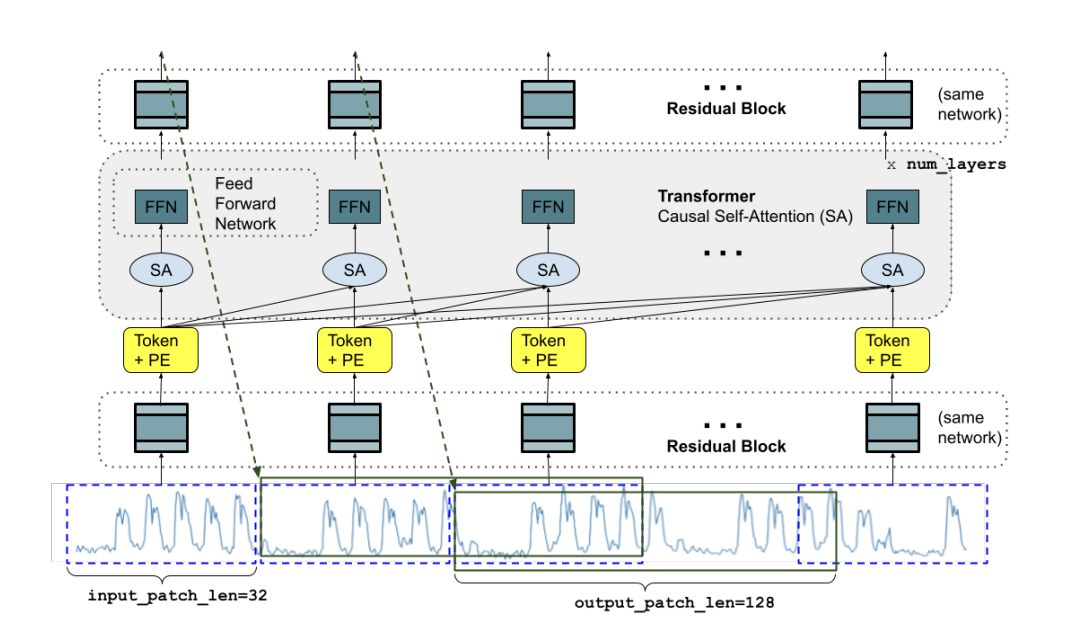
Time Series forecasting is an important task in machine learning and is frequently used in various domains such as finance, manufacturing, healthcare, and natural sciences. Researchers from Google introduced a decoder-only model for the task, called TimeFM, based on pretraining a patched-decoder style attention model on a large time-series corpus comprising both real-world and synthetic datasets. Time series data, collected at regular intervals over time, plays a crucial role in predicting future values. Traditional methods like ARIMA and GARCH have been widely used. The recent advancements in deep learning, particularly in large language models (LLMs) for Natural Language Processing (NLP), have opened new ways for researchers to handle time series forecasting by applying these models to the task.
The existing deep learning models such as DeepAR, Temporal Convolutions, and NBEATS are popular for time series forecasting, outperforming traditional statistical methods. There has been recent work on reusing or fine-tuning large language models (LLMs) like GPT-3 and LLaMA-2 for time series forecasting. In the paper, the researchers aim to investigate if a model pre-trained on massive amounts of time-series data can learn temporal patterns useful for accurate forecasting on previously unseen datasets.
TimesFM’s architecture involves a stacked transformer with a patched-decoder style attention mechanism inspired by successful patch-based modeling in long-horizon forecasting. The proposed model uses decoder-only training, which allows the model to predict the future by seeing different numbers of input patches in parallel. The data for training includes both real-world and synthetic data. The real-world data is taken from diverse sources like Google Trends and Wiki Pageviews, while the synthetic data is generated from statistical models like ARIMA.
Experiments demonstrate that TimesFM achieves impressive zero-shot forecasting performance. Not only the performance of the model is impressive but also it is more efficient than the existing models in parameter size and pretraining data. The model is evaluated on public datasets from Darts, Monash, and Informer, showcasing its ability to generalize and outperform specialized baselines.
Training on a wide corpus of synthetic and real-world data, TimesFM is a groundbreaking time series foundation model. The model’s unique architecture, which includes a patched-decoder attention mechanism and decoder-only training, contributes to its strong zero-shot forecasting performance. TimesFM’s ability to outperform baselines across multiple datasets demonstrates the potential of large pre-trained models for time series forecasting, providing a promising avenue for reducing training data and computational requirements in this field.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Pragati Jhunjhunwala is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Kharagpur. She is a tech enthusiast and has a keen interest in the scope of software and data science applications. She is always reading about the developments in different field of AI and ML.
Credit: Source link
Comments are closed.