Google Researchers Introduce AudioPaLM: A Game-Changer in Speech Technology – A New Large Language Model That Listens, Speaks, and Translates with Unprecedented Accuracy
Large Language Models (LLMs) have been in the limelight for a few months. Being one of the best advancements in the field of Artificial Intelligence, these models are transforming the way how humans interact with machines. As every industry is adopting these models, they are the best example of how AI is taking over the world. LLMs are excelling in producing text for tasks involving complex interactions and knowledge retrieval, the best example of which is the famous chatbot developed by OpenAI, ChatGPT, based on the Transformer architecture of GPT 3.5 and GPT 4. Not only in text generation but models like CLIP (Contrastive Language-Image Pretraining) have also been developed for image production, enabling the creation of text depending on the content of the image.
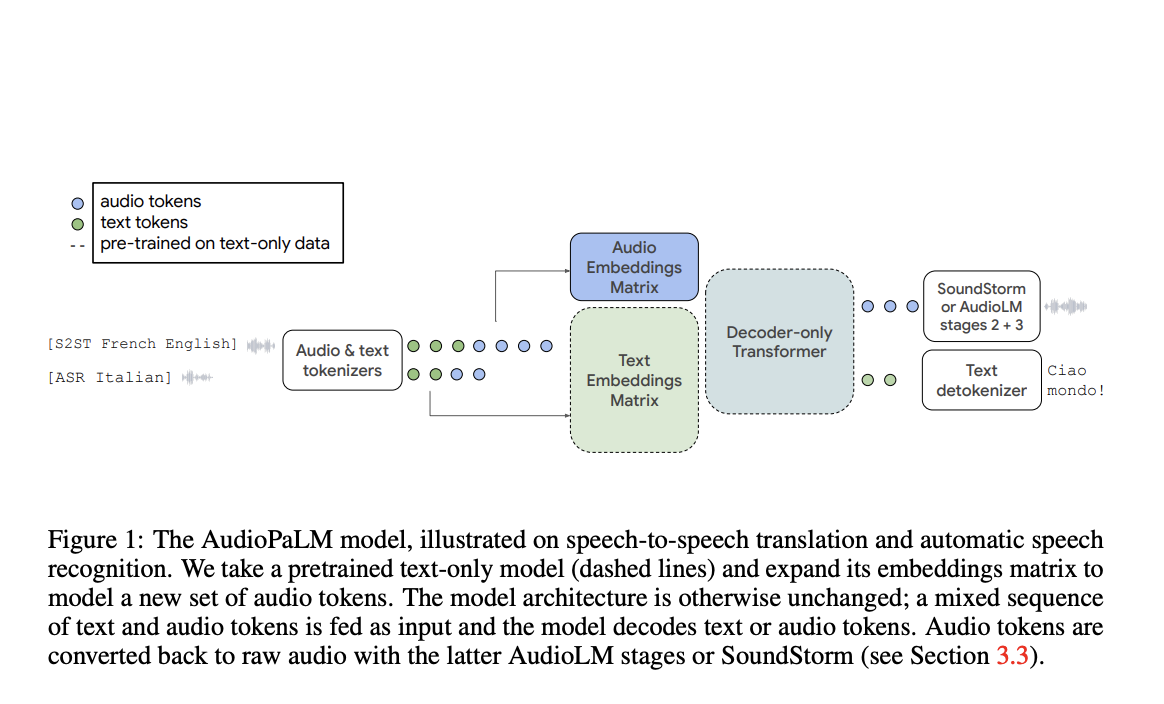
To progress in audio generation and understanding, a team of researchers from Google has introduced AudioPaLM, a large language model that can tackle speech understanding and generation tasks. AudioPaLM combines the advantages of two existing models, i.e., the PaLM-2 model and the AudioLM model, in order to produce a unified multimodal architecture that can process and produce both text and speech. This allows AudioPaLM to handle a variety of applications, ranging from voice recognition to voice-to-text conversion.
While AudioLM is excellent at maintaining paralinguistic information like speaker identity and tone, PaLM-2, which is a text-based language model, specializes in text-specific linguistic knowledge. By combining these two models, AudioPaLM takes advantage of PaLM-2’s linguistic expertise and AudioLM’s paralinguistic information preservation, leading to a more thorough comprehension and creation of both text and speech.
AudioPaLM makes use of a joint vocabulary that can represent both speech and text using a limited number of discrete tokens. Combining this joint vocabulary with markup task descriptions enables training a single decoder-only model on a variety of voice and text-based tasks. Tasks like speech recognition, text-to-speech synthesis, and speech-to-speech translation, which separate models traditionally addressed, can now be unified into a single architecture and training process.
Upon evaluation, AudioPaLM outperformed existing systems in speech translation by a significant margin. It demonstrated the ability to perform zero-shot speech-to-text translation for language combinations which means it can accurately translate speech into text for languages it has never encountered before, opening up possibilities for broader language support. AudioPaLM can also transfer voices across languages based on short spoken prompts and can capture and reproduce distinct voices in different languages, enabling voice conversion and adaptation.
The key contributions mentioned by the team are –
- AudioPaLM uses the capabilities of both PaLM and PaLM-2s from text-only pretraining.
- It has achieved SOTA results on Automatic Speech Translation and Speech-to-Speech Translation benchmarks and competitive performance on Automatic Speech Recognition benchmarks.
- The model performs Speech-to-Speech Translation with voice transfer of unseen speakers, surpassing existing methods in speech quality and voice preservation.
- AudioPaLM demonstrates zero-shot capabilities by performing Automatic Speech Translation with unseen language combinations.
In conclusion, AudioPaLM, which is a unified LLM that handles both speech and text by using the capabilities of text-based LLMs and incorporating audio prompting techniques, is a promising addition to the list of LLMs.
Check Out The Paper and Project. Don’t forget to join our 25k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
Featured Tools From AI Tools Club
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.