Google Researchers Propose MEMORY-VQ: A New AI Approach to Reduce Storage Requirements of Memory-Augmented Models without Sacrificing Performance
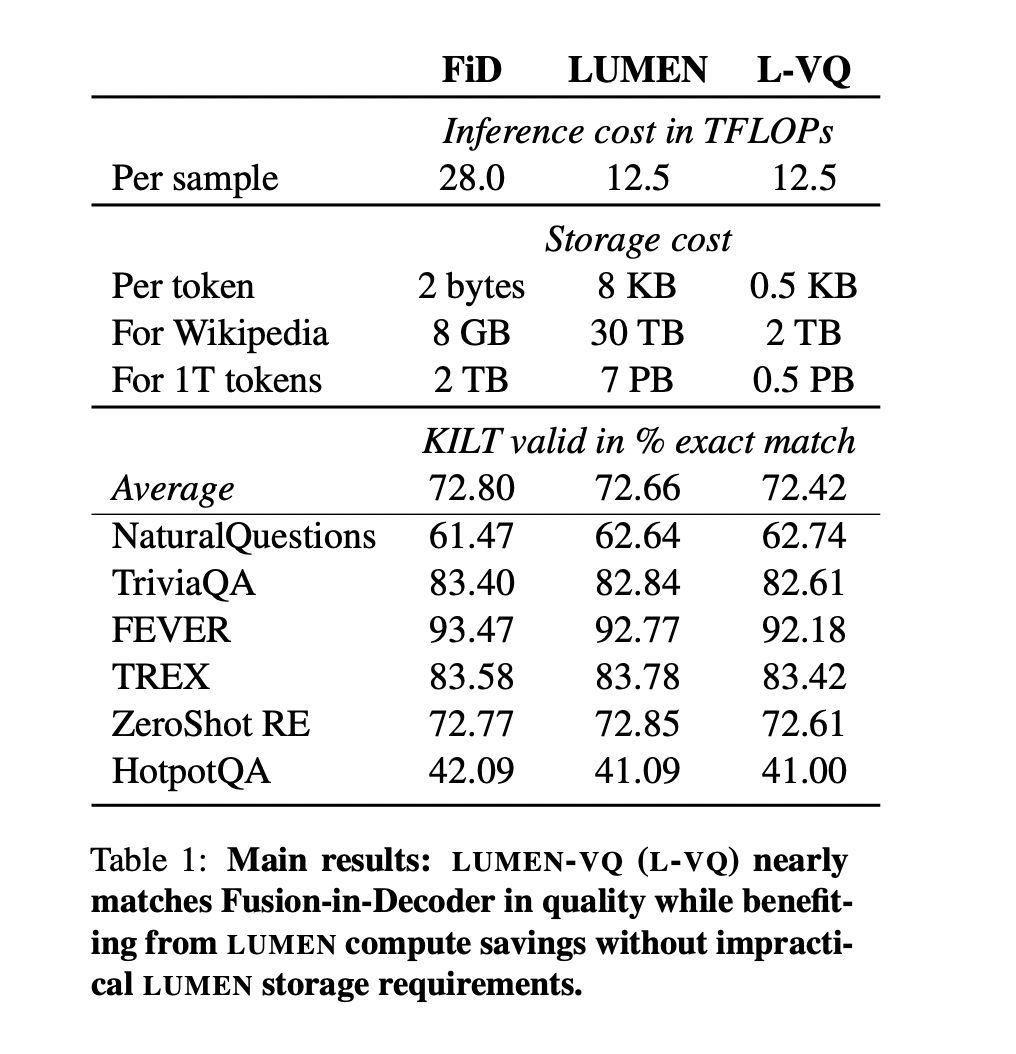
Recent research in language models has emphasized the importance of retrieval augmentation for enhancing factual knowledge. Retrieval augmentation involves providing these models with relevant text passages to improve their performances, but it comes at a higher computational cost. A new approach, depicted by LUMEN and LUMEN-VQ, aims to speed up the retrieval augmentation by pre-encoding passages from the corpus. This approach helps in reducing the computational burden while maintaining quality. However, pre-encoding requires substantial storage, which has been a challenge.
LUMEN-VQ, a combination of product quantization and VQ-VAE methods, addresses this storage problem by achieving a 16x compression rate. It implies that memory representations for vast corpora can be stored efficiently. This advancement marks a significant step towards practical large-scale retrieval augmentation, benefiting language understanding and information retrieval tasks.
Google researchers introduce MEMORY-VQ as a method for reducing storage requirements. It does this by compressing memories using vector quantization and replacing original memory vectors with integer codes that can be decompressed on the fly. The storage requirements for each quantized vector depend on the number of subspaces and the number of bits required to represent each code, determined by the logarithmic of the number of codes. This approach is applied to the LUMEN model, resulting in LUMEN-VQ. It employs product quantization and VQ-VAE for compression and decompression, with careful codebook initialization and memory division.
In conclusion, MEMORY-VQ is a pioneering method that effectively reduces storage demands in memory-augmented language models while maintaining high performance. It makes memory augmentation a practical solution for achieving substantial inference speed boosts, particularly when dealing with extensive retrieval corpora.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Astha Kumari is a consulting intern at MarktechPost. She is currently pursuing Dual degree course in the department of chemical engineering from Indian Institute of Technology(IIT), Kharagpur. She is a machine learning and artificial intelligence enthusiast. She is keen in exploring their real life applications in various fields.
Credit: Source link
Comments are closed.