Google researchers teach robots to learn by watching

|
Listen to this article  |

Different robot end effectors.
Roboticists usually teach robots new tasks by remotely operating them through performing a task. The robot then imitates the demonstration until it can perform the task on its own.
While this method of teaching robots is effective, it limits demonstrations to lab settings, and only programmers and roboticists can do the demonstrations. A research team at the robotics department at Google has been developing a new way for robots to learn.
Humans learn by watching all the time, but it’s not a simple task for robots to take on. This is difficult for robots because they look different than humans. For example, a robot with a two-fingered gripper won’t gain much knowledge about how to pick up a pen from watching a human with a five-fingered hand pick one up.
To tackle this problem, the team introduced a self-supervised method for Cross-Embodiment Inverse Reinforcement Learning (XIRL).
This method of teaching focuses on the robot learning the high-level task objective from videos. So, instead of trying to make individual human actions correspond with robot actions, the robot figures out what its end goal is.
It then summarizes that information in the form of a reward function that is invariant to physical differences like shape, actions and end effector dynamics. By utilizing the learned rewards and reinforcement learning, the research team taught robots how to handle objects through trial and error.
The robots learned more when the sample videos were more diverse. Experiments showed that the team’s learning method led to two to four times more sample efficient reinforcement learning on new embodiments.
The team has made an open-source implementation of its method and X-MAGICAL, its simulated benchmark for cross-embodiment imitation, to let others extend and build on their work.
X-MAGICAL was created to evaluate XIRL’s performance in a consistent environment. The program challenges a set of agent embodiments, that have different shapes and end effectors, to perform a task. The agents perform the tasks in different ways and at different speeds.
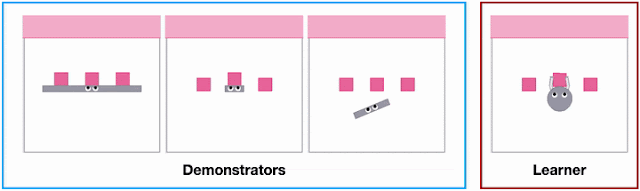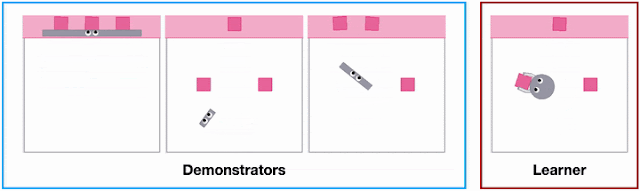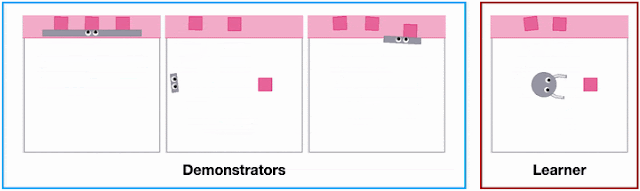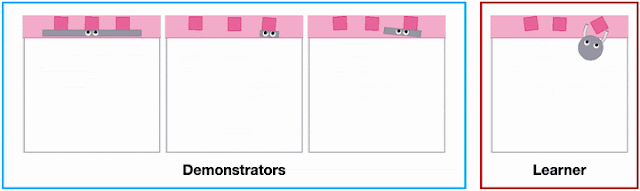
Demonstrating different shapes performing a task in X-MAGICAL. | Source: Google
The team also taught using real-world human demonstrations of tasks. They used their method to train a simulated Sawyer arm to push a puck into a target zone. Their teaching method also outperformed baseline methods.
The research team included Kevin Zakka, Andy Zeng, Pete Florence, Jonathan Tompson and Debidatta Dwibedi from robotics at Google, and Jeannette Bohg from Stanford University.
Credit: Source link
Comments are closed.