Griffon v2: A Unified High-Resolution Artificial Intelligence Model Designed to Provide Flexible Object Referring Via Textual and Visual Cues
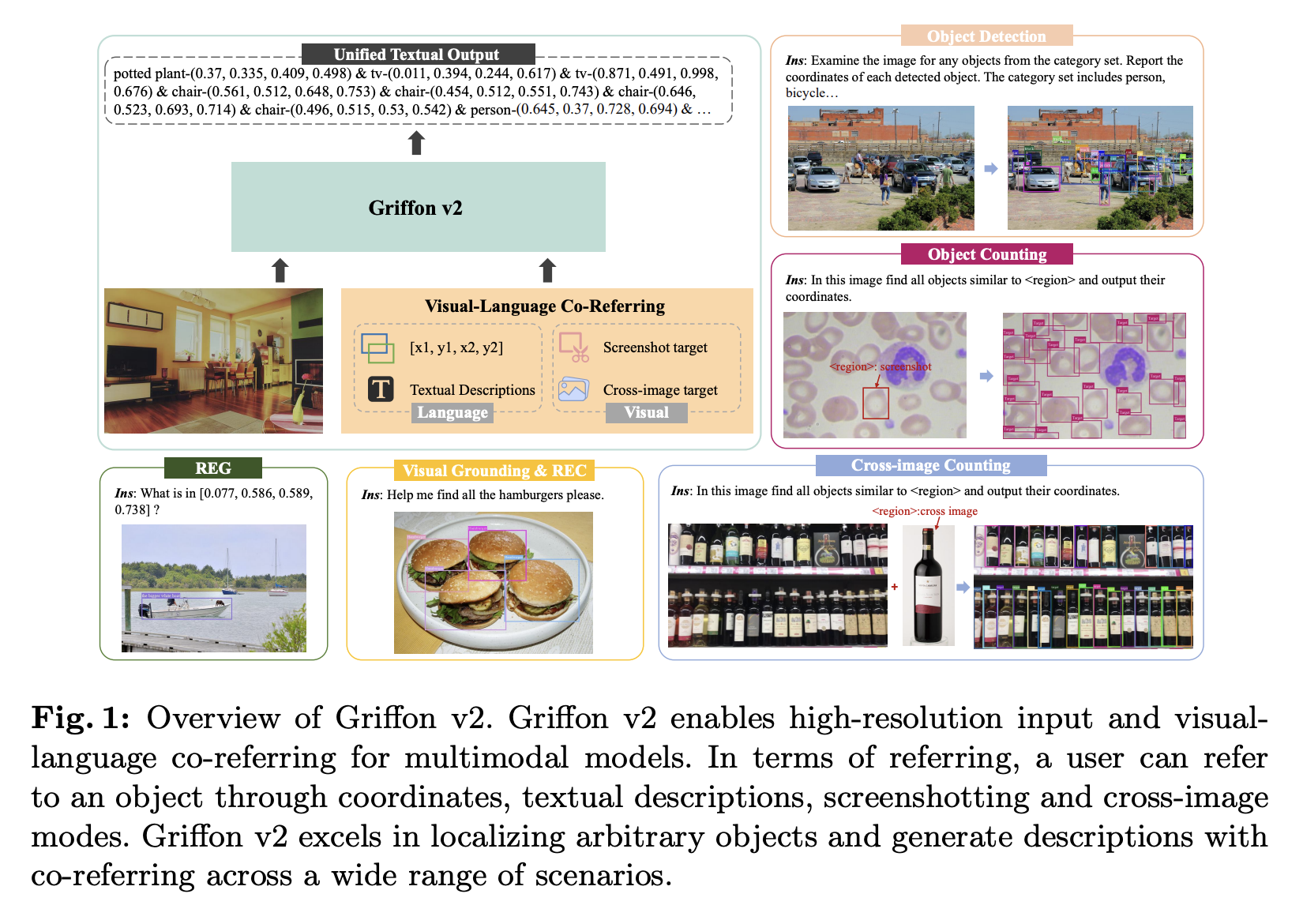
Recently, Large Vision Language Models (LVLMs) have demonstrated remarkable performance in tasks requiring both text and image comprehension. Particularly in region-level tasks like Referring Expression Comprehension (REC), this progress has become noticeable after image-text understanding and reasoning developments. Models such as Griffon have demonstrated remarkable performance in tasks such as object detection, suggesting a major advancement in perception inside LVLMs. This development has spurred additional research into the use of flexible references outside of textual descriptions to improve user interfaces.
Despite tremendous progress in fine-grained object perception, LVLMs are unable to outperform task-specific specialists in complex scenarios due to the constraint of picture resolution. This restriction limits their capacity to efficiently refer to things with both textual and visual cues, especially in areas like GUI Agents and counting activities.
To overcome this, a team of researchers has introduced Griffon v2, a unified high-resolution model designed to provide flexible object referring via textual and visual cues. In order to tackle the problem of effectively increasing image resolution, a straightforward and lightweight downsampling projector has been presented. The goal of this projector’s design is to get over the limitations placed by Large Language Models’ input tokens.
This approach greatly improves multimodal perception abilities by keeping fine features and entire contexts, especially for little things that lower-resolution models can miss. The team has built on this base using a plug-and-play visual tokenizer and has augmented Griffon v2 with visual-language co-referring capabilities. This feature makes it possible to interact with a variety of inputs in an easy-to-use manner, such as coordinates, free-form text, and flexible target pictures.
Griffon v2 has proven to be effective in a variety of tasks, such as Referring Expression Generation (REG), phrase grounding, and Referring Expression Comprehension (REC), according to experimental data. The model has performed better in object detection and object counting than expert models.
The team has summarized their primary contributions as follows:
- High-Resolution Multimodal Perception Model: By eliminating the requirement to split images, the model offers a unique method for multimodal perception that improves local understanding. The model’s capacity to capture small details has been improved by its ability to handle resolutions up to 1K.
- Visual-Language Co-Referring Structure: To extend the model’s utility and enable many interaction modes, a co-referring structure has been presented that combines language and visual inputs. This feature makes more adaptable and natural communication between users and the model possible.
- Extensive experiments have been conducted to verify the effectiveness of the model on a variety of localization tasks. In phrase grounding, Referring Expression Generation (REG), and Referring Expression Comprehension (REC), state-of-the-art performance has been obtained. The model has outperformed expert models in both quantitative and qualitative object counting, demonstrating its superiority in perception and comprehension.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 38k+ ML SubReddit
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.