Guess What I Saw Today? This AI Model Decodes Your Brain Signals to Reconstruct the Things You Saw
Brain 🧠. The most fascinating organ of the human body. Understanding how it works is the key to unlocking the secrets of life. How do we think, sense, smell, sense, act? The answer to all these questions lies in understanding how the brain works.
Understanding how the brain responds to what we see is a hot research topic, as this knowledge could lead to the development of advanced computational cognitive systems. Since we have fancy tools like functional magnetic resonance imaging (fMRI) and electroencephalograph (EEG), scientists can now record brain activity triggered by visual stimuli. This has led to a growing interest in decoding and reconstructing the actual content that provokes these responses in the human brain.
One common approach to studying human visual perception is to reconstruct the images or videos that subjects viewed during experiments. This is done using computational methods, particularly deep neural networks, and is primarily based on fMRI data. However, collecting fMRI data is expensive and inconvenient for practical use. I mean, if you have ever been in an MRI device, you would probably know how uncomfortable to stay there. Nobody is willingly agreeing to be in an experiment with that.
This is where EEG comes in. EEG is a more efficient way to record and analyze brain signals while subjects view various stimuli, but it has its own challenges. EEG signals are time-series data, which is very different from static images. This makes it difficult to match stimuli to corresponding brain signal pieces. Additionally, issues like electrode misplacement and body motion can introduce significant noise into the data. Simply mapping EEG inputs to pixels for image reconstruction produces low-quality results.
On the other hand, diffusion models have emerged as state-of-the-art approaches in generative modeling. They have been successfully applied to various tasks, including image synthesis and video generation. By operating in the latent space of powerful pre-trained autoencoders, the researchers overcome the limitations of pixel space evaluation, enabling faster inference and reducing training costs.
Let us meet with NeuroImageGen, which tackles this problem using the power of diffusion models.
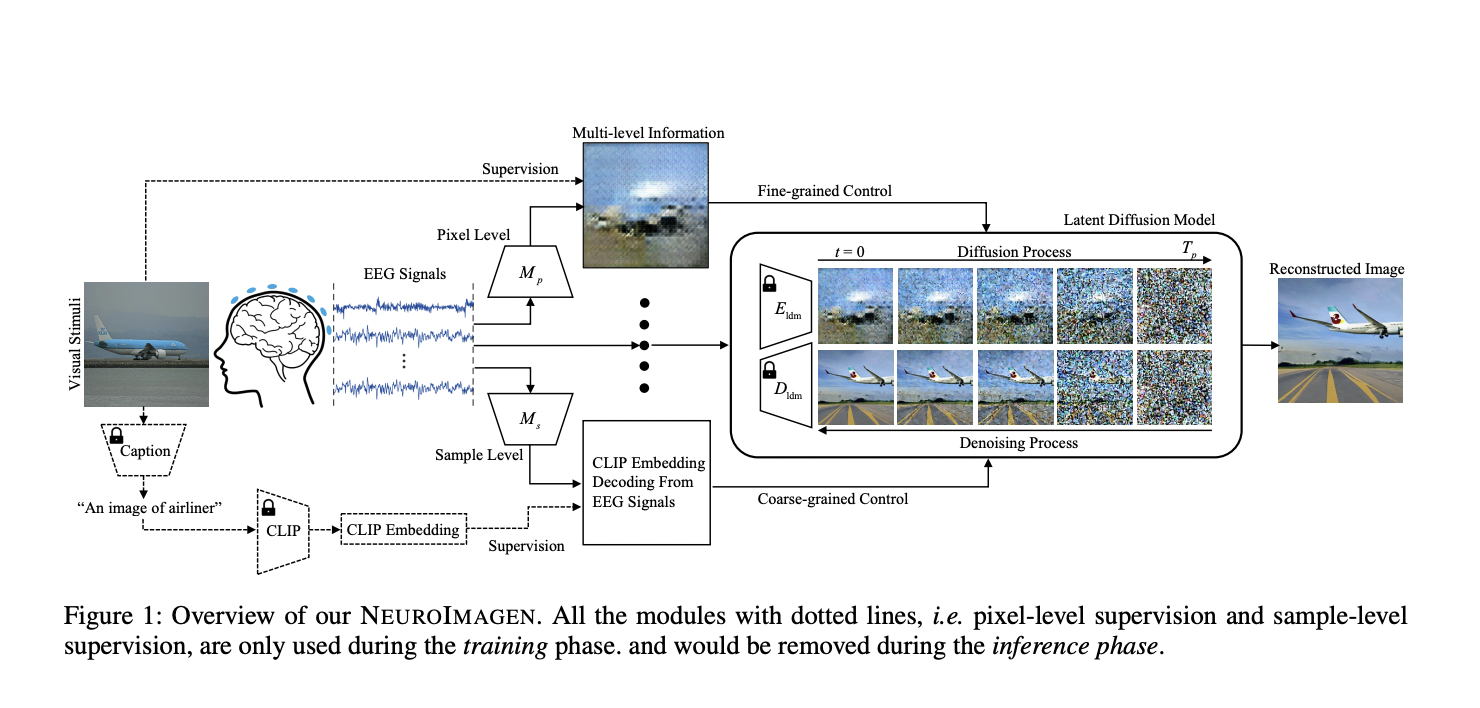
NeuroImageGen is a pipeline for neural image generation using EEG signals. It addresses the challenges associated with EEG-based image reconstruction by incorporating a multi-level semantics extraction module. This module decodes different levels of semantic information from EEG signals, ranging from sample-level semantics to pixel-level details like saliency maps. These multi-level outputs are then fed into pretrained diffusion models, effectively controlling the generation process at various semantic levels.
The EEG signals are complex time-series data prone to noise, making them challenging to work with. NeuroImageGen overcomes this by extracting multi-level semantics, which includes both pixel-level and sample-level information. Pixel-level semantics involve capturing fine-grained color, position, and shape details of visual stimuli through saliency maps. On the other hand, sample-level semantics provide a more coarse-grained understanding, such as recognizing image categories or text captions. This multi-level approach enables NeuroImageGen to handle the noisy EEG data effectively, facilitating high-quality visual stimulus reconstruction.
NeuroImageGen integrates these multi-level semantics into a latent diffusion model for image reconstruction. The pixel-level semantics, represented as saliency maps generated from EEG features, are used as an initial image. Sample-level semantics, derived from CLIP model embeddings of image captions, guide the denoising process in the diffusion model. This integration allows for a flexible control of semantic information at different levels during the reconstruction process. The result is the reconstructed visual stimulus, which effectively combines fine-grained and coarse-grained information to produce high-quality images.
The results of this approach are promising, outperforming traditional image reconstruction methods on EEG data. NEUROIMAGEN significantly enhances the structural similarity and semantic accuracy of reconstructed images, improving our understanding of the impact of visual stimuli on the human brain.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Ekrem Çetinkaya received his B.Sc. in 2018, and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He received his Ph.D. degree in 2023 from the University of Klagenfurt, Austria, with his dissertation titled “Video Coding Enhancements for HTTP Adaptive Streaming Using Machine Learning.” His research interests include deep learning, computer vision, video encoding, and multimedia networking.
Credit: Source link
Comments are closed.