Harmonizing Vision and Language: Advancing Consistency in Unified Models with CocoCon
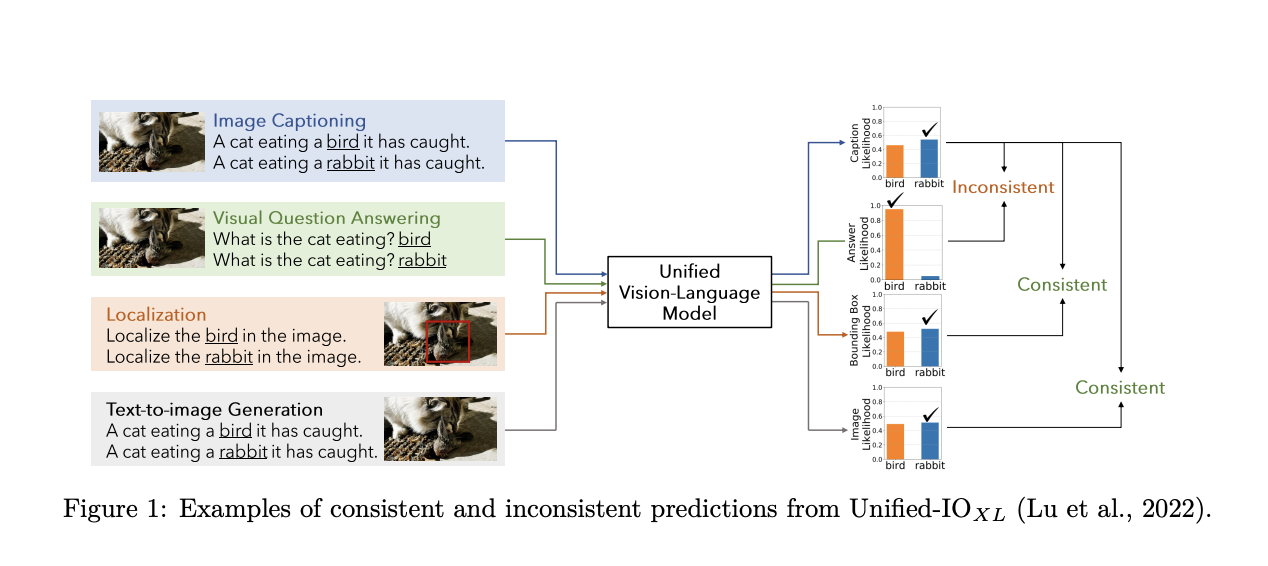
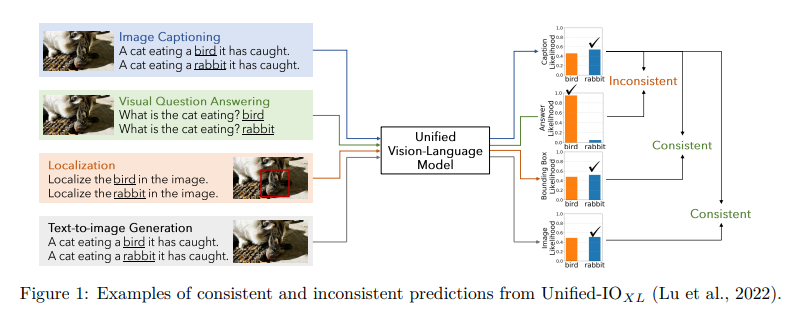
Unified vision-language models have emerged as a frontier, blending the visual with the verbal to create models that can interpret images and respond in human language. However, a stumbling block in their development has been ensuring that these models behave consistently across different tasks. The crux of the problem lies in the model’s ability to produce coherent and reliable outputs, whether they are identifying objects in images, answering questions based on those images, or generating textual descriptions from visual inputs.
Recent advancements have propelled these models to impressive heights, enabling them to tackle a wide array of multimodal tasks. Yet, this versatility has unveiled a critical issue: inconsistent responses across different tasks. Such inconsistencies erode trust in these models, making their integration into practical applications challenging. Imagine a model that identifies two jaguars in an image but contradicts itself when asked to describe the same scene in text. This inconsistency needs to be clarified for users and also undermines the model’s reliability.
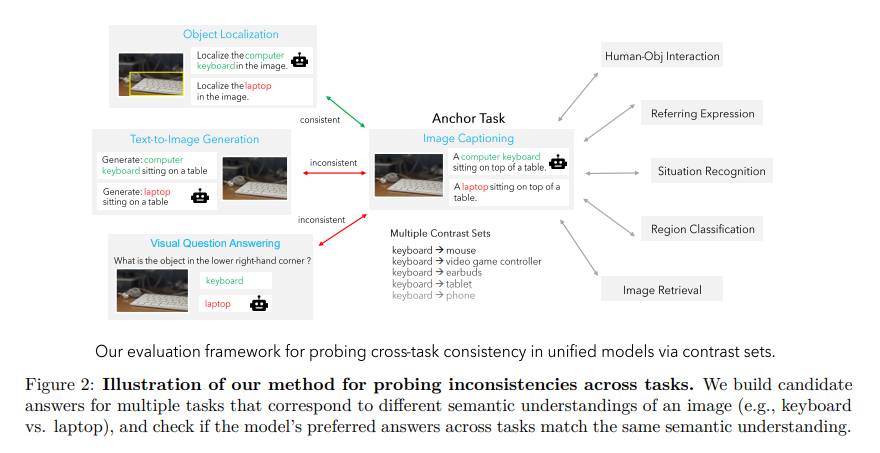
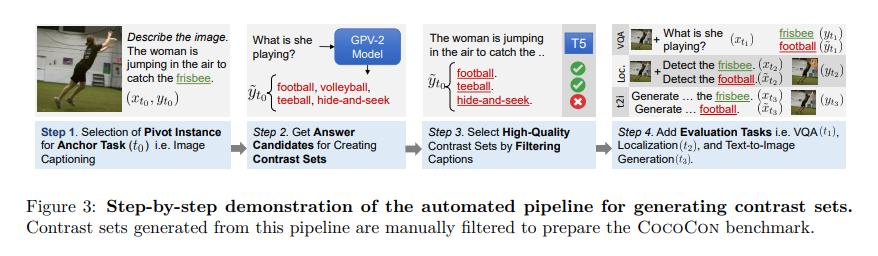
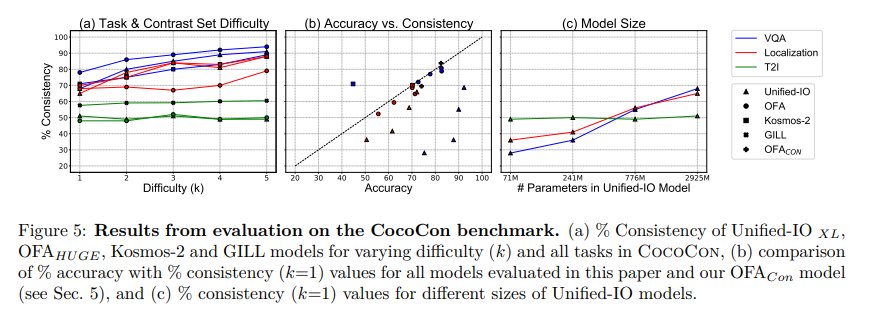
Researchers from the University of North Carolina, the University of California Los Angeles, and the Allen Institute for AI have developed a benchmark dataset, CocoCon, designed to evaluate and enhance the consistency of these models across various tasks. By creating contrast sets and modifying test instances in small but meaningful ways, the researchers can assess if a model’s responses remain consistent when the input changes slightly. This methodology revealed a significant degree of inconsistency among state-of-the-art vision-language models, particularly when tasks varied widely in their output format.
The study introduces a novel training objective based on rank correlation. This objective encourages models to maintain a consistent ranking of potential responses across tasks, thereby aligning their understanding of an image regardless of the question or task at hand. Preliminary results indicate that this approach not only improves cross-task consistency but also preserves, or even enhances, the model’s original accuracy on specific tasks.
This research underscores the importance of consistency in the development of unified vision-language models. By demonstrating the prevalence of cross-task inconsistency and proposing a method to mitigate it, the study paves the way for more reliable and trustworthy AI systems. The CocoCon benchmark emerges as a valuable tool in this endeavor, offering a means to rigorously evaluate and refine these complex models.
In conclusion, the implications of this work extend far beyond academic curiosity. In a world increasingly reliant on AI, the ability to trust the outputs of vision-language models becomes paramount. Whether for accessibility purposes, content creation, or even autonomous vehicles, the consistency ensured by approaches like those proposed in this study will be critical in realizing the full potential of AI in our daily lives. The journey toward models that can see and speak as we do, with all the nuance and reliability expected of human interaction, is just beginning.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
![]()
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
Credit: Source link
Comments are closed.