Has the release of ChatGPT affected the production of open data? Researchers Examine How LLMs Gaining Popularity Are Leading to a Substantial Decrease in Content on StackOverflow
Large Language Models (LLMs) are becoming popular with every new update and new releases. LLMs like BERT, GPT, and PaLM have shown tremendous capabilities in the field of Natural Language Processing and Natural Language Understanding. The well-known chatbot developed by OpenAI called ChatGPT is based on GPT 3.5 and GPT 4’s transformer architecture and is being used by more than a million users. Due to its human-imitating properties, it has caught everyone’s attention, from researchers and developers to students. It efficiently generates unique content, answers questions like a human would do, summarizes long textual paragraphs, completes code samples, translates languages, and so on.
ChatGPT has proven to be astonishingly good at giving users information on a variety of topics, making them potential alternatives to conventional web searches, and asking other users for assistance online. But there also comes a limitation, which is that the amount of publicly accessible human-generated data and knowledge resources might dramatically reduce if users keep on engaging privately with massive language models. This reduction in open data can make it difficult to secure training data for future models as there might be less freely available information.
To further research about it, a team of researchers has examined activity on Stack Overflow in order to determine how the release of ChatGPT affected the production of open data. Stack Overflow, a well-known Q&A site for computer programmers, has been used as it makes a great case study for examining user behavior and contributions when numerous language models are present. The team has dived into investigating how, as LLMs like ChatGPT are gaining massive popularity, they are leading to a substantial decrease in the content on sites like StackOverflow.
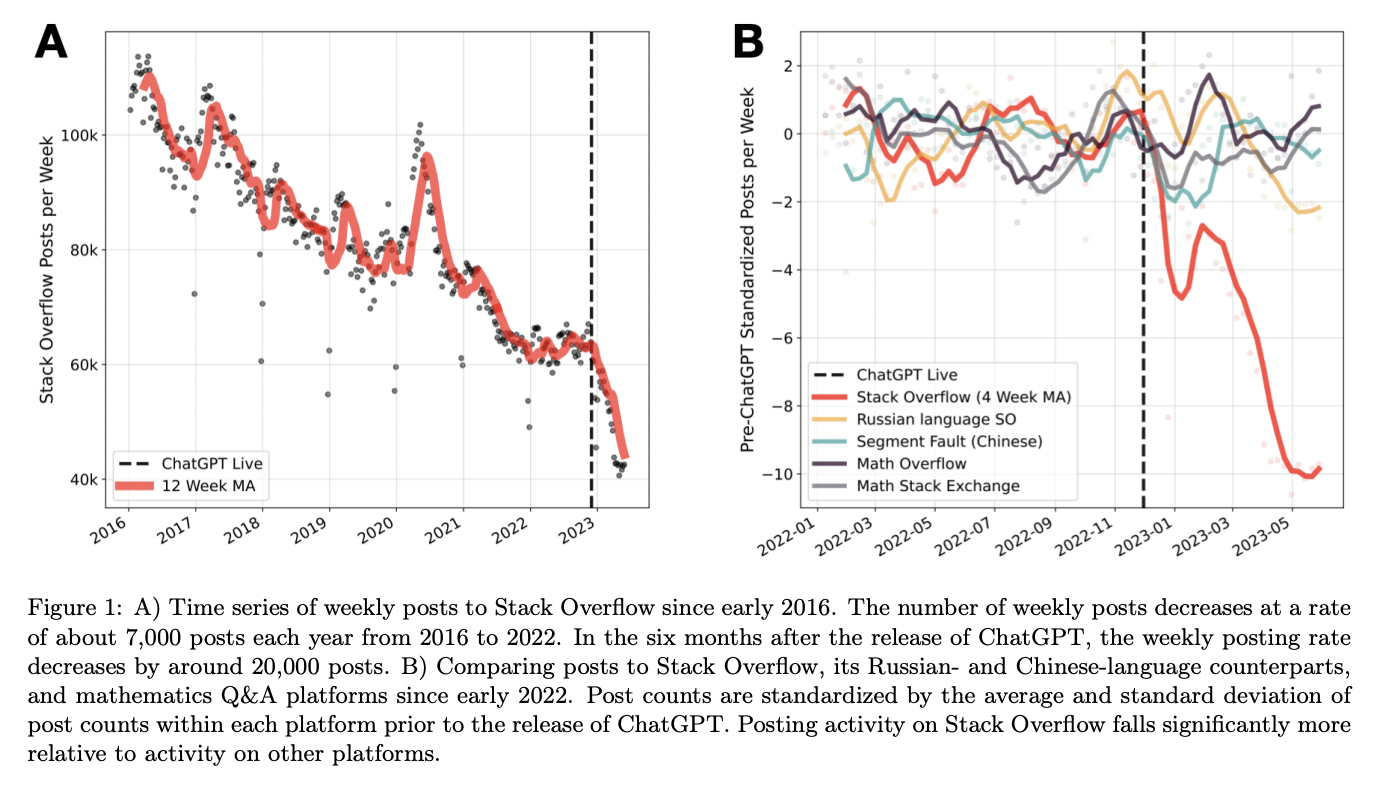
Upon evaluation, the team drew some interesting conclusions. Stack Overflow saw a large decrease in its activity compared to its Chinese and Russian competitors, where ChatGPT access is restricted, and to similar forums for mathematics, where ChatGPT is less effective due to a lack of useful training data. The team predicted a 16% decline in Stack Overflow weekly posts after the launch of OpenAI’s ChatGPT. Also, it was seen that the impact of ChatGPT on reducing activity on Stack Overflow has risen with time, suggesting that as users became more accustomed to the model’s features, they began to rely on it more and more for information, further limiting contributions to the site.
The team has narrowed down to three key findings, which are as follows.
- Reduced Posting Activity: After ChatGPT was released, Stack Overflow saw a decline in the number of posts, i.e., in questions and answers. A difference-in-differences methodology was used to calculate the activity reduction and compare it to four other Q&A platforms. The posting activity on Stack Overflow originally declined by about 16% within six months of ChatGPT’s debut before increasing to about 25%.
- No change in post votes – The number of votes, both up and down, that postings on Stack Overflow have received since ChatGPT’s launch has not changed significantly, despite the drop in posting activity, which shows that ChatGPT is replacing not only low-quality postings but also high-quality articles.
- Effect on Diverse Programming Languages: ChatGPT had a diverse effect on the various programming languages discussed on Stack Overflow. Compared to the global site average, posting activity decreased more noticeably for some languages, such as Python and JavaScript. The relative declines in posting activity were also influenced by the prevalence of programming languages on GitHub.
The authors have concluded by explaining how the widespread usage of LLMs and the subsequent move away from websites like Stack Overflow may ultimately limit the amount of open data that users and future models can learn from, despite the potential efficiency gains in solving some programming problems. This has consequences for the accessibility and sharing of knowledge on the internet as well as the long-term viability of the AI ecosystem.
Check out the Paper and Reddit Post. Don’t forget to join our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 800+ AI Tools in AI Tools Club
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.